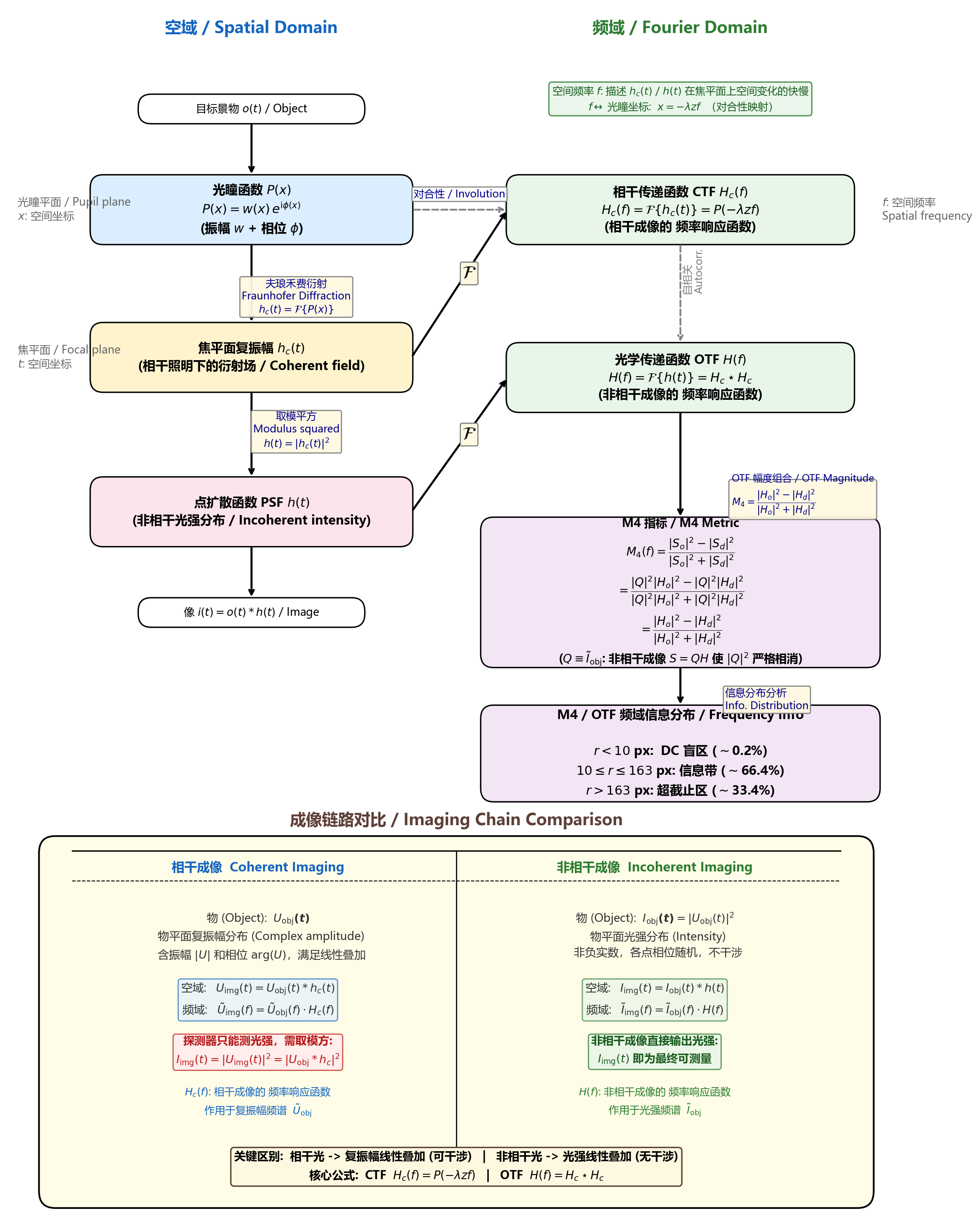
1. 1.1. 所有长度量均采用米(m)为单位,空间频率采用像素坐标(pixel)为单位(因数值计算采用离散傅里叶变换)。
符号
含义
量纲 / 单位
x x x 光瞳平面内的二维空间坐标,x = ( x 1 , x 2 ) x = (x_1, x_2) x = ( x 1 , x 2 )
m
t t t 焦平面(图像平面)内的二维空间坐标,t = ( t 1 , t 2 ) t = (t_1, t_2) t = ( t 1 , t 2 )
m
f f f 空间频率坐标,f = ( f 1 , f 2 ) f = (f_1, f_2) f = ( f 1 , f 2 )
cycle · m− 1 ^{-1} − 1
λ \lambda λ 光波波长
m
z z z 光瞳到焦平面的距离(等效焦距)
m
P ( x ) P(x) P ( x ) 光瞳函数(pupil function),P ( x ) = w ( x ) exp [ i ϕ ( x ) ] P(x) = w(x) \exp[\mathrm{i} \phi(x)] P ( x ) = w ( x ) exp [ i ϕ ( x ) ]
无量纲
P ~ ( u ) \tilde{P}(u) P ~ ( u ) 光瞳函数的纯数学傅里叶变换,P ~ ( u ) = F { P ( x ) } \tilde{P}(u) = \mathcal{F}\{P(x)\} P ~ ( u ) = F { P ( x ) }
无量纲
w ( x ) w(x) w ( x ) 光瞳振幅透射率,圆孔径内为 1,外为 0
无量纲
ϕ ( x ) \phi(x) ϕ ( x ) 波前相位畸变(以弧度为单位)
rad
h c ( t ) h_c(t) h c ( t ) 相干照明下的焦平面复振幅(complex amplitude)
m− 1 ^{-1} − 1
h ( t ) h(t) h ( t ) 点扩散函数(PSF),h ( t ) = ∥ h c ( t ) ∥ 2 h(t) = \|h_c(t)\|^2 h ( t ) = ∥ h c ( t ) ∥ 2
m− 2 ^{-2} − 2
H c ( f ) H_c(f) H c ( f ) 相干传递函数(CTF),H c ( f ) = F { h c ( t ) } H_c(f) = \mathcal{F}\{h_c(t)\} H c ( f ) = F { h c ( t ) }
无量纲
H ( f ) H(f) H ( f ) 光学传递函数(OTF),H ( f ) = F { h ( t ) } H(f) = \mathcal{F}\{h(t)\} H ( f ) = F { h ( t ) }
无量纲
o ( t ) o(t) o ( t ) 目标景物(object)的空间强度分布,非相干成像下 o ( t ) ≡ I o b j ( t ) o(t) \equiv I_{\mathrm{obj}}(t) o ( t ) ≡ I o b j ( t )
W · m− 2 ^{-2} − 2
i ( t ) i(t) i ( t ) 像平面强度分布(image),非相干成像下 i ( t ) ≡ I i m g ( t ) i(t) \equiv I_{\mathrm{img}}(t) i ( t ) ≡ I i m g ( t )
W · m− 2 ^{-2} − 2
Q ( f ) Q(f) Q ( f ) 目标景物(物光强)的傅里叶谱,Q ( f ) = F { o ( t ) } ≡ I ~ o b j ( f ) Q(f) = \mathcal{F}\{o(t)\} \equiv \tilde{I}_{\mathrm{obj}}(f) Q ( f ) = F { o ( t ) } ≡ I ~ o b j ( f )
W · m− 2 ^{-2} − 2 2 ^{2} 2
S o ( f ) S_o(f) S o ( f ) 在焦图像的傅里叶变换
W · m− 2 ^{-2} − 2 2 ^{2} 2
S d ( f ) S_d(f) S d ( f ) 离焦图像的傅里叶变换
W · m− 2 ^{-2} − 2 2 ^{2} 2
M 4 ( f ) M_4(f) M 4 ( f ) M4 指标,由 Eq.(12) 定义
无量纲
H o ( f ) H_o(f) H o ( f ) 在焦系统的光学传递函数(OTF)
无量纲
H d ( f ) H_d(f) H d ( f ) 离焦系统的光学传递函数(OTF)
无量纲
U o b j ( t ) U_{\mathrm{obj}}(t) U o b j ( t ) 物平面复振幅分布(相干成像)
复数(归一化)
U i m g ( t ) U_{\mathrm{img}}(t) U i m g ( t ) 像平面复振幅分布(相干成像)
复数(归一化)
U ~ o b j ( f ) \tilde{U}_{\mathrm{obj}}(f) U ~ o b j ( f ) 物平面复振幅的傅里叶谱
复数 · m2 ^{2} 2
U ~ i m g ( f ) \tilde{U}_{\mathrm{img}}(f) U ~ i m g ( f ) 像平面复振幅的傅里叶谱
复数 · m2 ^{2} 2
I o b j ( t ) I_{\mathrm{obj}}(t) I o b j ( t ) 物平面光强分布(非相干成像)
W · m− 2 ^{-2} − 2
I i m g ( t ) I_{\mathrm{img}}(t) I i m g ( t ) 像平面光强分布(非相干成像)
W · m− 2 ^{-2} − 2
I ~ o b j ( f ) \tilde{I}_{\mathrm{obj}}(f) I ~ o b j ( f ) 物平面光强的傅里叶谱
W
I ~ i m g ( f ) \tilde{I}_{\mathrm{img}}(f) I ~ i m g ( f ) 像平面光强的傅里叶谱
W
F { ⋅ } \mathcal{F}\{\cdot\} F { ⋅ } 傅里叶变换算子
—
⋆ \star ⋆ 复共轭自相关算子,( g ⋆ h ) ( f ) = ∫ g ( f ′ ) h ∗ ( f ′ − f ) d f ′ (g\star h)(f)=\int g(f')h^*(f'-f)\,df' ( g ⋆ h ) ( f ) = ∫ g ( f ′ ) h ∗ ( f ′ − f ) d f ′
—
D D D 光瞳物理直径
m
N p N_p N p 光瞳采样像素数(直径方向)
pixel
N 1 N_1 N 1 第一次 FFT(光瞳→焦平面)的零填充尺寸
pixel
N 2 N_2 N 2 第二次 FFT(生成 M4)的零填充尺寸
pixel
Δ x pupil \Delta x_{\text{pupil}} Δ x pupil 光瞳物理采样间隔,Δ x pupil = D / N p \Delta x_{\text{pupil}} = D / N_p Δ x pupil = D / N p
m
Δ f FFT \Delta f_{\text{FFT}} Δ f FFT 第一次 FFT 的频率分辨率,Δ f FFT = 1 / ( N 1 Δ x pupil ) \Delta f_{\text{FFT}} = 1/(N_1 \Delta x_{\text{pupil}}) Δ f FFT = 1 / ( N 1 Δ x pupil )
cycles/m
Δ t sim \Delta t_{\text{sim}} Δ t sim 仿真 PSF 像素间距,Δ t sim = λ z Δ f FFT \Delta t_{\text{sim}} = \lambda z \, \Delta f_{\text{FFT}} Δ t sim = λ z Δ f FFT
m
Δ t CCD \Delta t_{\text{CCD}} Δ t CCD CCD 像素间距
m
Δ f 400 \Delta f_{400} Δ f 4 0 0 400 点 FFT 的频率分辨率,Δ f 400 = 1 / ( N 2 Δ t CCD ) \Delta f_{400} = 1/(N_2 \Delta t_{\text{CCD}}) Δ f 4 0 0 = 1 / ( N 2 Δ t CCD )
cycles/m
α \alpha α PSF 插值缩放因子(sim → CCD),α = Δ t sim / Δ t CCD \alpha = \Delta t_{\text{sim}} / \Delta t_{\text{CCD}} α = Δ t sim / Δ t CCD
无量纲
k k k 频域总缩放因子(256 坐标 → 400 坐标),k = N 2 Δ t CCD / ( N 1 Δ t sim ) k = N_2 \Delta t_{\text{CCD}} / (N_1 \Delta t_{\text{sim}}) k = N 2 Δ t CCD / ( N 1 Δ t sim )
无量纲
f cutoff f_{\text{cutoff}} f cutoff OTF 截止频率,f cutoff = D / ( λ z ) f_{\text{cutoff}} = D / (\lambda z) f cutoff = D / ( λ z )
cycles/m
r cutoff r_{\text{cutoff}} r cutoff 截止频率在 N 2 N_2 N 2
px
A overlap A_{\text{overlap}} A overlap 光瞳自相关重叠区面积
m2 ^{2} 2
Δ \Delta Δ 光瞳平移量(Hopkins 积分),Δ = λ z f \Delta = \lambda z f Δ = λ z f
m
Z n m Z_n^m Z n m Zernike 多项式(第 n n n m m m
无量纲
δ ( x ) \delta(x) δ ( x ) 狄拉克 delta 函数
m− 1 ^{-1} − 1
σ M 4 ( f ) \sigma_{M_4}(f) σ M 4 ( f ) M4 指标在频率 f f f
无量纲
M ( f ) \mathcal{M}(f) M ( f ) 频率掩膜(M4 loss 的环形通带权重)
无量纲
r peak r_{\text{peak}} r peak 各像差模式的峰值灵敏度半径
px
坐标系约定 :
光瞳平面 x x x
焦平面 t t t
空间频率 f f f t t t f = t / ( λ z ) f = t / (\lambda z) f = t / ( λ z )
1.2. 下图展示了从光瞳函数 P ( x ) P(x) P ( x )
x x x t t t f f f
全文涉及三层变量,容易混淆。这里用一句话概括各自的物理身份:
变量
所在的"域"
物理身份
单位
x x x 光瞳平面
空间坐标 (光瞳上的位置)m
t t t 焦平面
空间坐标 (焦平面上的位置)m
f f f 频率平面
空间频率 (描述 h c ( t ) h_c(t) h c ( t ) cycles/m
关键区分 :
h c ( t ) = F { P ( x ) } h_c(t) = \mathcal{F}\{P(x)\} h c ( t ) = F { P ( x ) } t t t 不是频率 ——它是焦平面的物理空间坐标 (单位米)。式子中隐含的 f = t / ( λ z ) f = t/(\lambda z) f = t / ( λ z ) 光瞳函数 P ( x ) P(x) P ( x ) (即在光瞳平面上,P ( x ) P(x) P ( x ) x x x H c ( f ) = F { h c ( t ) } H_c(f) = \mathcal{F}\{h_c(t)\} H c ( f ) = F { h c ( t ) } f f f 焦平面复振幅 h c ( t ) h_c(t) h c ( t ) (即 h c ( t ) h_c(t) h c ( t ) t t t H c ( f ) = P ( − λ z f ) H_c(f) = P(-\lambda z f) H c ( f ) = P ( − λ z f ) x x x f = − x / ( λ z ) f = -x/(\lambda z) f = − x / ( λ z ) P ( D / 2 ) = 0 P(D/2)=0 P ( D / 2 ) = 0 H c ( f cutoff ) = 0 H_c(f_{\text{cutoff}})=0 H c ( f cutoff ) = 0 由于对合性 H c ( f ) = P ( − λ z f ) H_c(f) = P(-\lambda z f) H c ( f ) = P ( − λ z f ) f f f x = − λ z f x = -\lambda z f x = − λ z f x x x f f f f = 0 f=0 f = 0 f = f cutoff f = f_{\text{cutoff}} f = f cutoff
graph LR
Start[300mm] --> S1
subgraph S1[主缩束系统]
S1_s[缩束比: 5x]
end
S1 --> DM
subgraph DM[瞳面]
DM_s[变形镜
1.3. h c ( t ) = F { P ( x ) } h_c(t) = \mathcal{F}\{P(x)\} h c ( t ) = F { P ( x ) } H c ( f ) = F { h c ( t ) } H_c(f) = \mathcal{F}\{h_c(t)\} H c ( f ) = F { h c ( t ) } H c ( f ) H_c(f) H c ( f ) P ( x ) P(x) P ( x )
傅里叶变换的对合性(Involution Property) :一个函数连续做两次相同形式的傅里叶变换(正变换+正变换),结果是原函数的空间反转,即
F { F { g ( x ) } } = g ( − x ) \boxed{\mathcal{F}\{\mathcal{F}\{g(x)\}\} = g(-x)}
F { F { g ( x ) } } = g ( − x )
1.3.1. 一个典型的 4F 成像系统 由两个焦距均为 F F F 2 F 2F 2 F
第一个透镜 :对物平面做傅里叶变换,在中间焦平面(傅里叶面)形成物的频谱第二个透镜 :对中间焦平面的频谱再做一次傅里叶变换,在像平面恢复出物的像
两次傅里叶变换的累积效果是什么?像相对于物是同时左右和上下颠倒的 (等价于绕光轴旋转180°)——也就是说,两次傅里叶变换等于原函数的空间反转。
这就是傅里叶变换的对合性 在物理上的直接体现。
1.3.2. 设 g ( x ) g(x) g ( x ) g ^ ( f ) = F { g ( x ) } = ∫ g ( x ) e − i 2 π f x d x \hat{g}(f) = \mathcal{F}\{g(x)\} = \int g(x) e^{-\mathrm{i} 2\pi f x} dx g ^ ( f ) = F { g ( x ) } = ∫ g ( x ) e − i 2 π f x d x g ^ ( f ) \hat{g}(f) g ^ ( f )
F { g ^ ( f ) } = ∫ − ∞ + ∞ g ^ ( f ) e − i 2 π f x d f \mathcal{F}\{\hat{g}(f)\} = \int_{-\infty}^{+\infty} \hat{g}(f) \, e^{-\mathrm{i} 2\pi f x} \, df
F { g ^ ( f ) } = ∫ − ∞ + ∞ g ^ ( f ) e − i 2 π f x d f
将 g ^ ( f ) \hat{g}(f) g ^ ( f )
= ∫ − ∞ + ∞ [ ∫ − ∞ + ∞ g ( x ′ ) e − i 2 π f x ′ d x ′ ] e − i 2 π f x d f = \int_{-\infty}^{+\infty} \left[ \int_{-\infty}^{+\infty} g(x') \, e^{-\mathrm{i} 2\pi f x'} \, dx' \right] e^{-\mathrm{i} 2\pi f x} \, df
= ∫ − ∞ + ∞ [ ∫ − ∞ + ∞ g ( x ′ ) e − i 2 π f x ′ d x ′ ] e − i 2 π f x d f
交换积分次序:
= ∫ − ∞ + ∞ g ( x ′ ) [ ∫ − ∞ + ∞ e − i 2 π f ( x ′ + x ) d f ] d x ′ = \int_{-\infty}^{+\infty} g(x') \left[ \int_{-\infty}^{+\infty} e^{-\mathrm{i} 2\pi f (x' + x)} \, df \right] dx'
= ∫ − ∞ + ∞ g ( x ′ ) [ ∫ − ∞ + ∞ e − i 2 π f ( x ′ + x ) d f ] d x ′
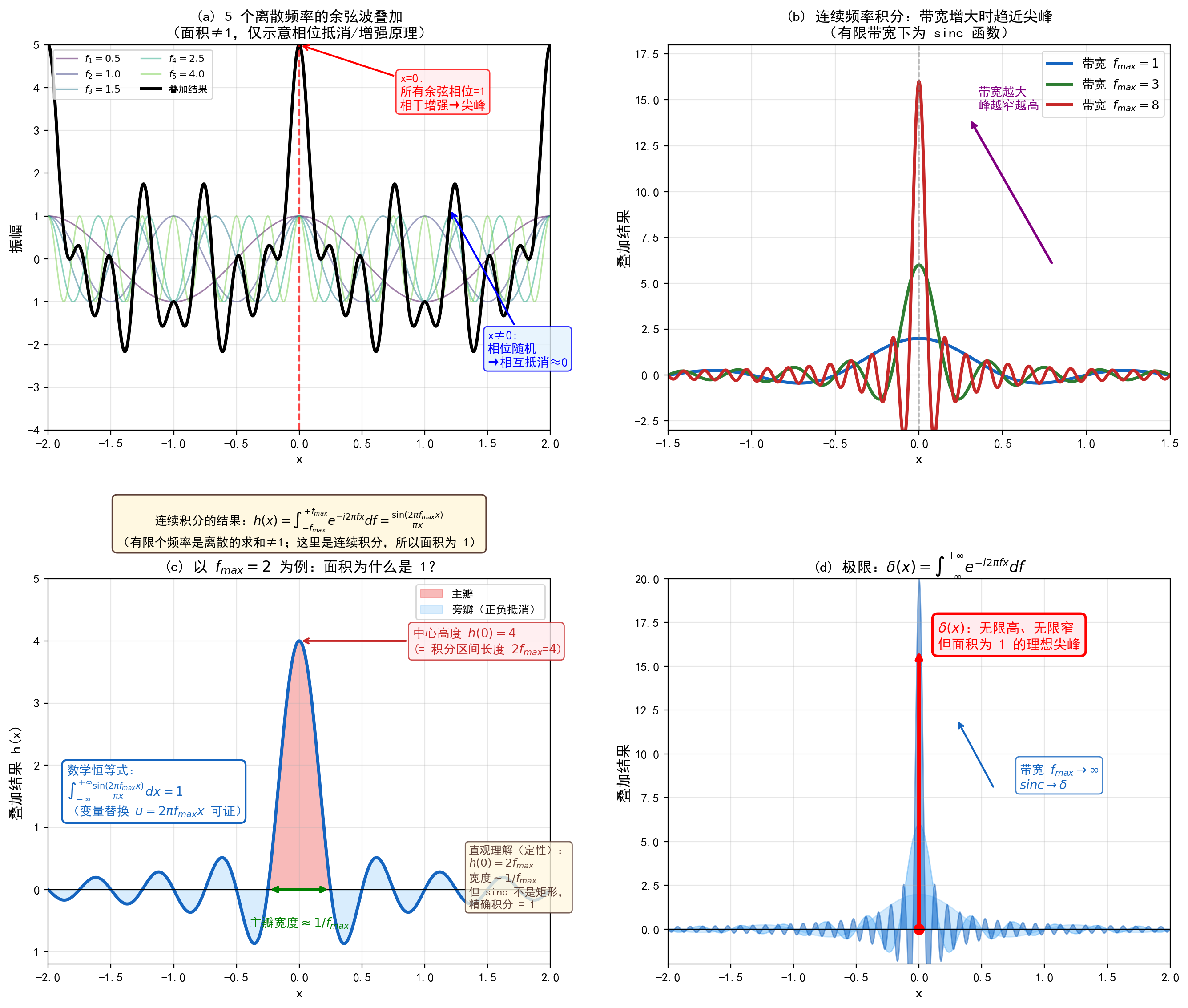
现在来看内层积分。这里用到一个重要的数学工具——狄拉克 delta 函数 δ ( x ) \delta(x) δ ( x ) δ ( x ) \delta(x) δ ( x )
在 x ≠ 0 x \neq 0 x = 0 δ ( x ) = 0 \delta(x) = 0 δ ( x ) = 0
在 x = 0 x = 0 x = 0
但它的总面积为 1:∫ − ∞ + ∞ δ ( x ) d x = 1 \displaystyle\int_{-\infty}^{+\infty} \delta(x) \, dx = 1 ∫ − ∞ + ∞ δ ( x ) d x = 1
下图直观地展示了 delta 函数的构造过程。
delta 函数最核心的性质是筛选性 :当它与任意函数 g ( x ) g(x) g ( x ) g ( x ) g(x) g ( x ) x = 0 x=0 x = 0
∫ − ∞ + ∞ g ( x ) δ ( x ) d x = g ( 0 ) \int_{-\infty}^{+\infty} g(x) \, \delta(x) \, dx = g(0)
∫ − ∞ + ∞ g ( x ) δ ( x ) d x = g ( 0 )
更一般地,δ ( x − a ) \delta(x - a) δ ( x − a ) g ( a ) g(a) g ( a )
而 delta 函数还有一个非常漂亮的傅里叶积分表示 ——它恰好是复指数函数对所有频率的积分:
∫ − ∞ + ∞ e − i 2 π f u d f = δ ( u ) \int_{-\infty}^{+\infty} e^{-\mathrm{i} 2\pi f \, u} \, df = \delta(u)
∫ − ∞ + ∞ e − i 2 π f u d f = δ ( u )
这个等式的物理直觉是:所有频率的平面波 e − i 2 π f u e^{-\mathrm{i} 2\pi f u} e − i 2 π f u u = 0 u = 0 u = 0 δ ( u ) \delta(u) δ ( u ) u = 0 u=0 u = 0 e 0 = 1 e^0 = 1 e 0 = 1
把 u = x ′ + x u = x' + x u = x ′ + x
∫ − ∞ + ∞ e − i 2 π f ( x ′ + x ) d f = δ ( x ′ + x ) \int_{-\infty}^{+\infty} e^{-\mathrm{i} 2\pi f (x' + x)} \, df = \delta(x' + x)
∫ − ∞ + ∞ e − i 2 π f ( x ′ + x ) d f = δ ( x ′ + x )
因此,原式变为:
F { g ^ ( f ) } = ∫ − ∞ + ∞ g ( x ′ ) δ ( x ′ + x ) d x ′ \mathcal{F}\{\hat{g}(f)\} = \int_{-\infty}^{+\infty} g(x') \, \delta(x' + x) \, dx'
F { g ^ ( f ) } = ∫ − ∞ + ∞ g ( x ′ ) δ ( x ′ + x ) d x ′
利用 delta 函数的筛选性(令 x ′ = − x x' = -x x ′ = − x
∫ − ∞ + ∞ g ( x ′ ) δ ( x ′ + x ) d x ′ = g ( − x ) \int_{-\infty}^{+\infty} g(x') \, \delta(x' + x) \, dx' = g(-x)
∫ − ∞ + ∞ g ( x ′ ) δ ( x ′ + x ) d x ′ = g ( − x )
即:
F { F { g ( x ) } } = g ( − x ) \boxed{\mathcal{F}\{\mathcal{F}\{g(x)\}\} = g(-x)}
F { F { g ( x ) } } = g ( − x )
1.3.3. 两次正变换给出空间反转(F 2 = R \mathcal{F}^2 = R F 2 = R F − 1 F = I \mathcal{F}^{-1}\mathcal{F} = \mathbb{I} F − 1 F = I
正变换: ∫ g ( x ) e − i 2 π f x d x 逆变换: ∫ g ^ ( f ) e + i 2 π f x d f \begin{aligned}
\text{正变换:} &\quad \int g(x) \, e^{-\mathrm{i} 2\pi f x} \, dx \\
\text{逆变换:} &\quad \int \hat{g}(f) \, e^{+\mathrm{i} 2\pi f x} \, df
\end{aligned}
正变换: 逆变换: ∫ g ( x ) e − i 2 π f x d x ∫ g ^ ( f ) e + i 2 π f x d f
这一点可严格证明:对任意 g ( x ) g(x) g ( x )
F { g } ( f ) = ∫ − ∞ + ∞ g ( x ) e − i 2 π f x d x = ∫ + ∞ − ∞ g ( − u ) e + i 2 π f u ( − d u ) ( 令 u = − x ) = ∫ − ∞ + ∞ g ( − u ) e + i 2 π f u d u = F − 1 { g ( − x ) } ( f ) \begin{aligned}
\mathcal{F}\{g\}(f)
&= \int_{-\infty}^{+\infty} g(x) \, e^{-\mathrm{i} 2\pi f x} \, dx \\
&= \int_{+\infty}^{-\infty} g(-u) \, e^{+\mathrm{i} 2\pi f u} \, (-du) \qquad (\text{令 } u = -x) \\
&= \int_{-\infty}^{+\infty} g(-u) \, e^{+\mathrm{i} 2\pi f u} \, du \\
&= \mathcal{F}^{-1}\{g(-x)\}(f)
\end{aligned}
F { g } ( f ) = ∫ − ∞ + ∞ g ( x ) e − i 2 π f x d x = ∫ + ∞ − ∞ g ( − u ) e + i 2 π f u ( − d u ) ( 令 u = − x ) = ∫ − ∞ + ∞ g ( − u ) e + i 2 π f u d u = F − 1 { g ( − x ) } ( f )
即 F { g } = F − 1 { g ( − x ) } \mathcal{F}\{g\} = \mathcal{F}^{-1}\{g(-x)\} F { g } = F − 1 { g ( − x ) }
F = F − 1 ∘ R \mathcal{F} = \mathcal{F}^{-1} \circ R
F = F − 1 ∘ R
正变换 = 逆变换 + 一次空间翻转 。上面证明的复合顺序是"先翻转、后逆变换"(F − 1 { g ( − x ) } \mathcal{F}^{-1}\{g(-x)\} F − 1 { g ( − x ) } R R R
( R ∘ F ) { g } ( t ) = F { g } ( − t ) = ∫ g ( x ) e + i 2 π x t d x = F − 1 { g } ( t ) ( F ∘ R ) { g } ( t ) = F { g ( − x ) } ( t ) = ∫ g ( − x ) e − i 2 π x t d x = ∫ + ∞ − ∞ g ( u ) e + i 2 π u t ( − d u ) = ∫ − ∞ + ∞ g ( u ) e + i 2 π u t d u = F − 1 { g } ( t ) \begin{aligned}
(R \circ \mathcal{F})\{g\}(t) &= \mathcal{F}\{g\}(-t) = \int g(x) \, e^{+i2\pi x t} \, dx = \mathcal{F}^{-1}\{g\}(t) \\
(\mathcal{F} \circ R)\{g\}(t) &= \mathcal{F}\{g(-x)\}(t) = \int g(-x) \, e^{-i2\pi x t} \, dx = \int_{+\infty}^{-\infty} g(u) \, e^{+i2\pi u t} \, (-du) = \int_{-\infty}^{+\infty} g(u) \, e^{+i2\pi u t} \, du = \mathcal{F}^{-1}\{g\}(t)
\end{aligned}
( R ∘ F ) { g } ( t ) ( F ∘ R ) { g } ( t ) = F { g } ( − t ) = ∫ g ( x ) e + i 2 π x t d x = F − 1 { g } ( t ) = F { g ( − x ) } ( t ) = ∫ g ( − x ) e − i 2 π x t d x = ∫ + ∞ − ∞ g ( u ) e + i 2 π u t ( − d u ) = ∫ − ∞ + ∞ g ( u ) e + i 2 π u t d u = F − 1 { g } ( t )
同理可证 R ∘ F − 1 = F − 1 ∘ R = F R \circ \mathcal{F}^{-1} = \mathcal{F}^{-1} \circ R = \mathcal{F} R ∘ F − 1 = F − 1 ∘ R = F
F = F − 1 ∘ R = R ∘ F − 1 \mathcal{F} = \mathcal{F}^{-1} \circ R = R \circ \mathcal{F}^{-1}
F = F − 1 ∘ R = R ∘ F − 1
在下面的 CTF 推导中,采用"先逆变换、后翻转 "的顺序更自然——这样正变换与逆变换可以直接相邻抵消,不需要翻转挡在中间。于是两次正变换可以写成:
F 2 = F ∘ F = ( R ∘ F − 1 ) ∘ F = R ∘ ( F − 1 ∘ F ) = R \mathcal{F}^2 = \mathcal{F} \circ \mathcal{F} = (R \circ \mathcal{F}^{-1}) \circ \mathcal{F} = R \circ (\mathcal{F}^{-1} \circ \mathcal{F}) = R
F 2 = F ∘ F = ( R ∘ F − 1 ) ∘ F = R ∘ ( F − 1 ∘ F ) = R
"正变换 + 逆变换"抵消为恒等,只剩空间翻转。正变换与逆变换的核函数仅差一个符号,这正是上述替换精确成立的原因:
运算
算子等式
含义
F 2 \mathcal{F}^2 F 2 R R R 两次正变换 = 空间反转
F − 1 F \mathcal{F}^{-1}\mathcal{F} F − 1 F I \mathbb{I} I 正逆变换 = 完全还原
F 4 \mathcal{F}^4 F 4 I \mathbb{I} I 四次正变换 = 回到自身
1.3.4. 下面按这个思路展开。光学中从光瞳函数 P ( x ) P(x) P ( x ) H c ( f ) H_c(f) H c ( f )
第一次 :夫琅禾费衍射 = 傅里叶变换 + 缩放(t / λ z t/\lambda z t / λ z 第二次 :对 h c ( t ) h_c(t) h c ( t )
关键在于:傅里叶变换的尺度性质 允许将第一步的"傅里叶变换 + 缩放"重新排列为"缩放 + 傅里叶变换 ";而已证明的"正变换 = 逆变换 + 翻转"允许将第二步的傅里叶变换替换为"逆变换 + 翻转 "。于是整个链路变成:
缩放 → F → F − 1 → R \text{缩放} \to \mathcal{F} \to \mathcal{F}^{-1} \to R
缩放 → F → F − 1 → R
中间的正逆抵消,最终只剩缩放 + 翻转 。下面分步验证。
第一步:把夫琅禾费衍射的缩放"吸收"进光瞳函数
夫琅禾费衍射 h c ( t ) ∝ P ~ ( t / ( λ z ) ) h_c(t) \propto \tilde{P}(t/(\lambda z)) h c ( t ) ∝ P ~ ( t / ( λ z ) ) f f f t t t f = t / ( λ z ) f = t/(\lambda z) f = t / ( λ z )
物理直觉 :对光瞳函数做完傅里叶变换后,频率域坐标 f f f λ z \lambda z λ z t t t
t = f ⋅ λ z t = f \cdot \lambda z
t = f ⋅ λ z
这意味着 FFT 频率轴上的每一个 bin,经过 λ z \lambda z λ z
为什么是 cycles/m 而不是 Hz?
频率的单位取决于所讨论的是时间信号 还是空间信号 :
频率类型
单位
物理含义
应用场景
时间频率 Hz = cycles/s
描述信号随时间 变化的快慢
音频、射频、时变信号
空间频率 cycles/m
描述信号随空间位置 变化的快慢
图像、光瞳、波前
在夫琅禾费衍射中:
光瞳函数 P ( x ) P(x) P ( x ) 空间分布 (随光瞳位置 x x x 空间频率谱 P ~ ( f ) \tilde{P}(f) P ~ ( f )
焦平面复振幅 h c ( t ) h_c(t) h c ( t ) 空间分布 (随焦面位置 t t t
因此这里出现的频率 f f f 空间频率 (cycles/m),描述的是"光瞳函数在空间上变化有多快",而非"信号随时间振荡有多快"。
更具体地说,夫琅禾费衍射的完整公式(省略常数相位因子)为:
h c ( t ) ∝ ∫ P ( x ) e − i 2 π t ⋅ x λ z d x = ∫ P ( x ) e − i 2 π f ⋅ x d x = P ~ ( f ) , f = t λ z h_c(t) \propto \int P(x) \, e^{-\mathrm{i} \, 2\pi \, \frac{t \cdot x}{\lambda z}} \, dx
= \int P(x) \, e^{-\mathrm{i} \, 2\pi \, f \cdot x} \, dx
= \tilde{P}(f), \quad f = \frac{t}{\lambda z}
h c ( t ) ∝ ∫ P ( x ) e − i 2 π λ z t ⋅ x d x = ∫ P ( x ) e − i 2 π f ⋅ x d x = P ~ ( f ) , f = λ z t
被积函数中的指数 e − i 2 π f x e^{-\mathrm{i} 2\pi f x} e − i 2 π f x e − i 2 π f x e^{-\mathrm{i} 2\pi f x} e − i 2 π f x f = t / ( λ z ) f = t/(\lambda z) f = t / ( λ z ) λ z \lambda z λ z 空间位置 t t t 空间频率 f f f f ⋅ x f \cdot x f ⋅ x
频率单位与被变换函数 P ( x ) P(x) P ( x )
需要区分两个概念:频率变量 f f f vs 变换结果 P ~ ( f ) \tilde{P}(f) P ~ ( f ) 。
标准傅里叶变换定义为:
P ~ ( f ) = ∫ − ∞ ∞ P ( x ) e − i 2 π f x d x \tilde{P}(f) = \int_{-\infty}^{\infty} P(x) \, e^{-\mathrm{i} 2\pi f x} \, dx
P ~ ( f ) = ∫ − ∞ ∞ P ( x ) e − i 2 π f x d x
指数 e − i 2 π f x e^{-\mathrm{i} 2\pi f x} e − i 2 π f x f ⋅ x f \cdot x f ⋅ x
频率变量 f f f 只由 x x x P ( x ) P(x) P ( x ) 无关 :
若 x x x f f f
若 x x x f f f
若 x x x f f f
变换结果 P ~ ( f ) \tilde{P}(f) P ~ ( f ) 则等于 P ( x ) P(x) P ( x ) d x dx d x x x x
[ P ~ ( f ) ] = [ P ( x ) ] ⋅ [ x ] [\tilde{P}(f)] = [P(x)] \cdot [x]
[ P ~ ( f ) ] = [ P ( x ) ] ⋅ [ x ]
具体例子:
被变换函数
[ P ( x ) ] [P(x)] [ P ( x ) ] [ x ] [x] [ x ] [ f ] [f] [ f ] [ P ~ ( f ) ] = [ P ] ⋅ [ x ] [\tilde{P}(f)] = [P] \cdot [x] [ P ~ ( f ) ] = [ P ] ⋅ [ x ]
光瞳函数 P ( x ) P(x) P ( x )
无量纲
m
cycles/m
m
焦面复振幅 h c ( t ) h_c(t) h c ( t )
m− 1 ^{-1} − 1
m
cycles/m
m (= m − 1 ⋅ m 2 = \mathrm{m}^{-1} \cdot \mathrm{m}^{2} = m − 1 ⋅ m 2 1 / λ z 1/\lambda z 1 / λ z
PSF h ( t ) h(t) h ( t )
m− 2 ^{-2} − 2
m
cycles/m
无量纲 (= m − 2 ⋅ m 2 = \mathrm{m}^{-2} \cdot \mathrm{m}^{2} = m − 2 ⋅ m 2
物光强 I o b j ( t ) I_{\mathrm{obj}}(t) I o b j ( t )
W·m− 2 ^{-2} − 2
m
cycles/m
W (= W ⋅ m − 2 ⋅ m 2 = \mathrm{W}\cdot\mathrm{m}^{-2} \cdot \mathrm{m}^{2} = W ⋅ m − 2 ⋅ m 2
因此:
所有"空间上的二维东西"做傅里叶变换后,频率变量都是空间频率 (cycles/m、cycles/pixel 等),因为 x x x P P P 变换结果 P ~ ( f ) \tilde{P}(f) P ~ ( f ) P P P ,因为积分运算 ∫ P ( x ) d x \int P(x) dx ∫ P ( x ) d x P P P
代码中的 torch.fft.fft2 输出的是什么频率?
在代码 generative_M4_model.py 中,夫琅禾费衍射通过 torch.fft.fft2(pupil_complex, norm="ortho") 实现。torch.fft.fft2 计算的是离散傅里叶变换(DFT) ,其定义为:
X [ k ] = ∑ n = 0 N − 1 x [ n ] e − i 2 π k n N X[k] = \sum_{n=0}^{N-1} x[n] \, e^{-\mathrm{i} 2\pi \frac{k n}{N}}
X [ k ] = n = 0 ∑ N − 1 x [ n ] e − i 2 π N k n
其中 n n n k k k 整数索引 (像素位置),因此 k / N k/N k / N 归一化频率 ,单位是 cycles/sample (或无量纲)——不是 cycles/m。
要从 DFT 的归一化频率得到物理频率 (cycles/m),本质上是乘以频率分辨率 Δ f = 1 N ⋅ Δ x \Delta f = \dfrac{1}{N \cdot \Delta x} Δ f = N ⋅ Δ x 1
f 物理 = k ⋅ Δ f = k N ⋅ Δ x f_{\text{物理}} = k \cdot \Delta f = \frac{k}{N \cdot \Delta x}
f 物理 = k ⋅ Δ f = N ⋅ Δ x k
其中 N N N Δ x \Delta x Δ x Δ f \Delta f Δ f
具体到本系统(对应代码中的参数):
光瞳采样:N p = 51 N_p = 51 N p = 5 1 D = 60 D = 60 D = 6 0
光瞳像素物理间距:Δ x pupil = D / N p \Delta x_{\text{pupil}} = D / N_p Δ x pupil = D / N p
FFT 零填充后尺寸:M = 256 M = 256 M = 2 5 6
DFT 输出的归一化频率:k / M k/M k / M k = − M / 2 , … , M / 2 − 1 k = -M/2, \dots, M/2-1 k = − M / 2 , … , M / 2 − 1
物理频率 :f = k M ⋅ Δ x pupil = k ⋅ N p M ⋅ D f = \dfrac{k}{M \cdot \Delta x_{\text{pupil}}} = \dfrac{k \cdot N_p}{M \cdot D} f = M ⋅ Δ x pupil k = M ⋅ D k ⋅ N p
焦平面上的物理位置由 t = f ⋅ λ z t = f \cdot \lambda z t = f ⋅ λ z
t = k ⋅ N p M ⋅ D ⋅ λ z t = \frac{k \cdot N_p}{M \cdot D} \cdot \lambda z
t = M ⋅ D k ⋅ N p ⋅ λ z
这正是代码中 sim_pixel_pitch_m = wavelength_m * pupil_ccd_focal_len_m * H / (M * pupil_diameter_m) 的物理来源(其中 H = N p H = N_p H = N p
Δ t sim = λ z ⏟ 焦平面映射因子 × H M ⋅ D ⏟ 频率分辨率 Δ f \Delta t_{\text{sim}} = \underbrace{\lambda z}_{\text{焦平面映射因子}} \times \underbrace{\frac{H}{M \cdot D}}_{\text{频率分辨率 } \Delta f}
Δ t sim = 焦平面映射因子 λ z × 频率分辨率 Δ f M ⋅ D H
后半部分 H M ⋅ D \dfrac{H}{M \cdot D} M ⋅ D H 频率分辨率 (单位 cycles/m):H H H M M M D D D
前半部分 λ z \lambda z λ z t = f ⋅ λ z t = f \cdot \lambda z t = f ⋅ λ z λ z \lambda z λ z
代码将两步合并为一次计算,但物理上仍是"先求频率分辨率,再映射到焦平面"的顺序。
一句话总结 :torch.fft.fft2 输出的是归一化离散频率 (cycles/sample);文档中所说的 cycles/m 是经过像素物理间距 映射后的物理空间频率 。两者通过 f 物理 = f 离散 / Δ x f_{\text{物理}} = f_{\text{离散}} / \Delta x f 物理 = f 离散 / Δ x
离散实现 :在数值仿真中(见代码 generative_M4_model.py),焦平面的像素间距由下式决定:
Δ t sim = λ z ⋅ H M ⋅ D \Delta t_{\text{sim}} = \frac{\lambda z \cdot H}{M \cdot D}
Δ t sim = M ⋅ D λ z ⋅ H
其中 H H H N p N_p N p M M M D D D
Δ t sim = λ z D ⏟ 衍射尺度 ⋅ H M ⏟ 零填充因子 \Delta t_{\text{sim}} = \underbrace{\frac{\lambda z}{D}}_{\text{衍射尺度}} \cdot \underbrace{\frac{H}{M}}_{\text{零填充因子}}
Δ t sim = 衍射尺度 D λ z ⋅ 零填充因子 M H
离散频率分辨率 Δ f = H / ( M ⋅ D ) \Delta f = H/(M \cdot D) Δ f = H / ( M ⋅ D ) λ z \lambda z λ z M > H M > H M > H H / M < 1 H/M < 1 H / M < 1
为利用纯数学的尺度性质,可将该缩放"吸收"进光瞳函数:
F { g ( a x ) } ( f ) = 1 ∣ a ∣ g ^ ( f / a ) \mathcal{F}\{g(ax)\}(f) = \frac{1}{|a|}\hat{g}(f/a)
F { g ( a x ) } ( f ) = ∣ a ∣ 1 g ^ ( f / a )
取 a = λ z a = \lambda z a = λ z g = P g = P g = P
P ~ ( t λ z ) ⏟ 先傅里叶变换,再缩放 = λ z ⋅ F { P ( λ z ⋅ x ) } ( t ) ⏟ 先缩放,再傅里叶变换 \underbrace{\tilde{P}\!\left(\frac{t}{\lambda z}\right)}_{\text{先傅里叶变换,再缩放}}
= \lambda z \cdot
\underbrace{\mathcal{F}\{P(\lambda z \cdot x)\}(t)}_{\text{先缩放,再傅里叶变换}}
先傅里叶变换,再缩放 P ~ ( λ z t ) = λ z ⋅ 先缩放,再傅里叶变换 F { P ( λ z ⋅ x ) } ( t )
即:夫琅禾费衍射 = 先把光瞳缩放 x → λ z x x \to \lambda z x x → λ z x 。
第二步:正逆抵消,只剩缩放 + 翻转
CTF 定义为 h c ( t ) h_c(t) h c ( t )
H c ( f ) ∝ F { F { P ( λ z ⋅ x ) } } ( f ) H_c(f) \propto \mathcal{F}\{\mathcal{F}\{P(\lambda z \cdot x)\}\}(f)
H c ( f ) ∝ F { F { P ( λ z ⋅ x ) } } ( f )
把第二次正变换拆成"逆变换 + 翻转"(F = R ∘ F − 1 \mathcal{F} = R \circ \mathcal{F}^{-1} F = R ∘ F − 1
F { F { P ( λ z ⋅ x ) } } = ( R ∘ F − 1 ) { F { P ( λ z ⋅ x ) } } \mathcal{F}\{\mathcal{F}\{P(\lambda z \cdot x)\}\} = (R \circ \mathcal{F}^{-1})\{\mathcal{F}\{P(\lambda z \cdot x)\}\}
F { F { P ( λ z ⋅ x ) } } = ( R ∘ F − 1 ) { F { P ( λ z ⋅ x ) } }
利用算子复合的结合律,正逆直接抵消:
F ∘ F = ( R ∘ F − 1 ) ∘ F = R ∘ ( F − 1 ∘ F ) = R \mathcal{F} \circ \mathcal{F} = (R \circ \mathcal{F}^{-1}) \circ \mathcal{F} = R \circ (\mathcal{F}^{-1} \circ \mathcal{F}) = R
F ∘ F = ( R ∘ F − 1 ) ∘ F = R ∘ ( F − 1 ∘ F ) = R
对合性 F 2 = R \mathcal{F}^2 = R F 2 = R P ( λ z ⋅ x ) P(\lambda z \cdot x) P ( λ z ⋅ x )
H c ( f ) ∝ R { P ( λ z ⋅ x ) } ( f ) = P ( − λ z f ) H_c(f) \propto R\{P(\lambda z \cdot x)\}(f) = P(-\lambda z f)
H c ( f ) ∝ R { P ( λ z ⋅ x ) } ( f ) = P ( − λ z f )
最终只留下了缩放 (λ z \lambda z λ z 翻转 (负号)。
H c ( f ) ∝ P ( − λ z f ) \boxed{H_c(f) \propto P(-\lambda z f)}
H c ( f ) ∝ P ( − λ z f )
一句话总结
把第二次变换看成"逆变换 + 翻转"时,整个光学链路变成:缩放 → 正变换 → 逆变换 → 翻转 。中间的正逆抵消,只剩最前面的缩放和最后面的翻转。缩放因子 λ z \lambda z λ z
1.3.5. H c ( f ) = P ( − λ z f ) H_c(f) = P(-\lambda z f) H c ( f ) = P ( − λ z f ) 数学上 H c ( f ) ∝ P ( − λ z f ) H_c(f) \propto P(-\lambda z f) H c ( f ) ∝ P ( − λ z f ) 这个等式的物理含义是什么?
为什么 P ( − λ z f ) P(-\lambda z f) P ( − λ z f ) H c ( f ) H_c(f) H c ( f )
反直觉:也就是说,若将光瞳x=0处的光遮住,该光学系统就无法对0频率进行响应了。
数学推导(对任意频率 f f f
从 CTF 的定义出发:
H c ( f ) = F { h c } ( f ) = ∫ h c ( t ) e − i 2 π f t d t H_c(f) = \mathcal{F}\{h_c\}(f) = \int h_c(t) \, e^{-i 2\pi f t} \, dt
H c ( f ) = F { h c } ( f ) = ∫ h c ( t ) e − i 2 π f t d t
把 h c ( t ) = F { P } ( t ) h_c(t) = \mathcal{F}\{P\}(t) h c ( t ) = F { P } ( t )
H c ( f ) = ∫ [ ∫ P ( x ) e − i 2 π x t / ( λ z ) d x ] e − i 2 π f t d t H_c(f) = \int \left[ \int P(x) \, e^{-i 2\pi x t / (\lambda z)} \, dx \right] e^{-i 2\pi f t} \, dt
H c ( f ) = ∫ [ ∫ P ( x ) e − i 2 π x t / ( λ z ) d x ] e − i 2 π f t d t
交换积分顺序:
H c ( f ) = ∫ P ( x ) [ ∫ e − i 2 π t ( x / ( λ z ) + f ) d t ] d x H_c(f) = \int P(x) \left[ \int e^{-i 2\pi t \, (x / (\lambda z) + f)} \, dt \right] dx
H c ( f ) = ∫ P ( x ) [ ∫ e − i 2 π t ( x / ( λ z ) + f ) d t ] d x
内层积分 ∫ e − i 2 π t ( x / ( λ z ) + f ) d t \int e^{-i 2\pi t \, (x / (\lambda z) + f)} dt ∫ e − i 2 π t ( x / ( λ z ) + f ) d t 复指数对所有焦平面位置 t t t 。只有当指数中的频率恰好为零,即 x / ( λ z ) + f = 0 x / (\lambda z) + f = 0 x / ( λ z ) + f = 0 e 0 = 1 e^0 = 1 e 0 = 1 x ≠ − λ z f x \neq -\lambda z f x = − λ z f t t t
所以内层积分"挑选"出了 x = − λ z f x = -\lambda z f x = − λ z f
∫ e − i 2 π t ( x / ( λ z ) + f ) d t ∝ δ ( x + λ z f ) \int e^{-i 2\pi t \, (x / (\lambda z) + f)} \, dt \propto \delta(x + \lambda z f)
∫ e − i 2 π t ( x / ( λ z ) + f ) d t ∝ δ ( x + λ z f )
代回去:
H c ( f ) ∝ ∫ P ( x ) δ ( x + λ z f ) d x = P ( − λ z f ) H_c(f) \propto \int P(x) \, \delta(x + \lambda z f) \, dx = P(-\lambda z f)
H c ( f ) ∝ ∫ P ( x ) δ ( x + λ z f ) d x = P ( − λ z f )
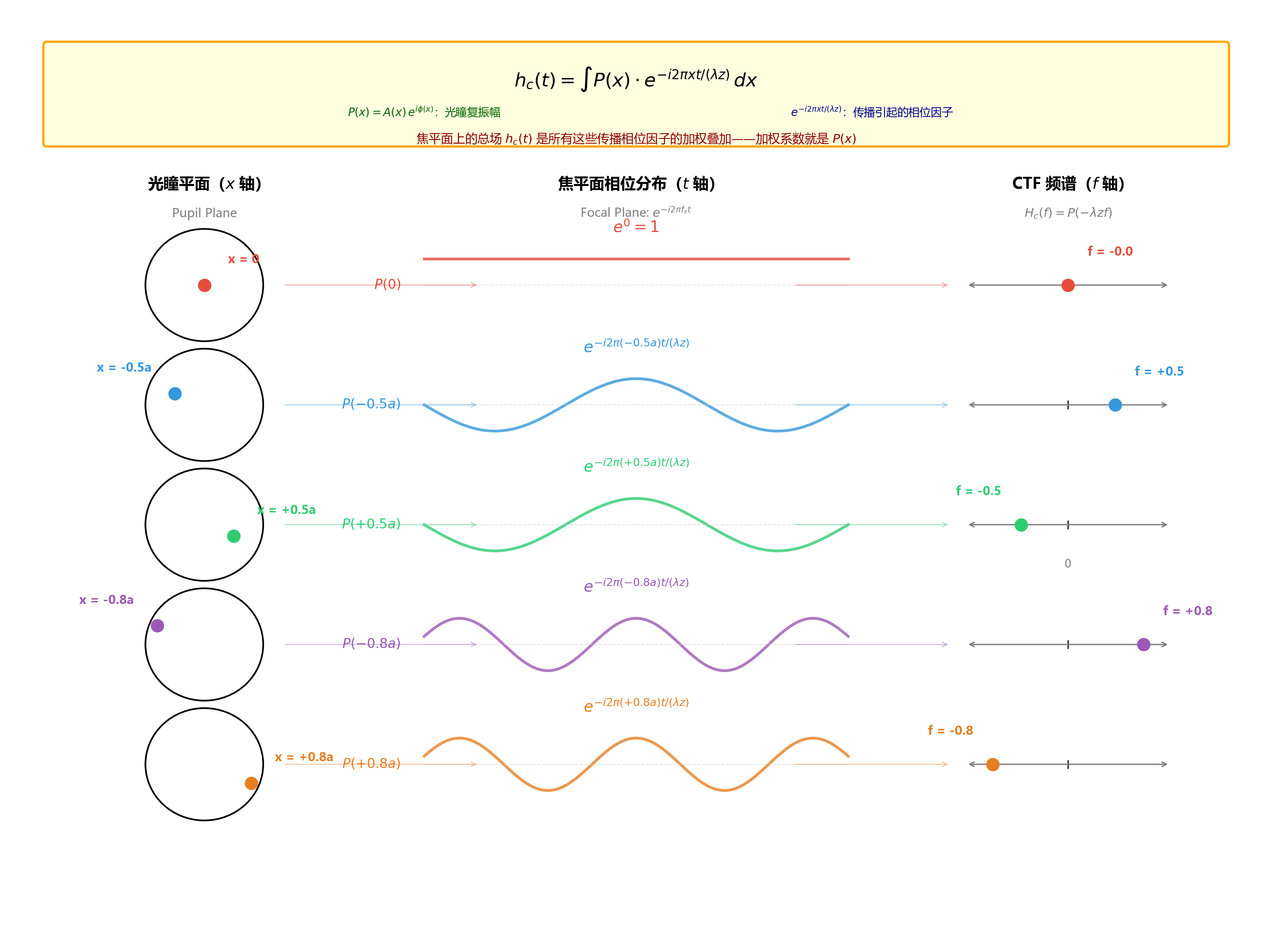
核心物理图像:光瞳上的每个位置在焦平面上"写"下一条条纹
先把夫琅禾费衍射公式中的两种相位 严格分开:
h c ( t ) = ∫ A ( x ) e i ϕ ( x ) ⏟ 光瞳上的复振幅 P ( x ) e − i 2 π x t / ( λ z ) ⏟ 传播引起的相位因子 d x h_c(t) = \int \underbrace{A(x) \, e^{i\phi(x)}}_{\text{光瞳上的复振幅 } P(x)} \, \underbrace{e^{-i 2\pi x t / (\lambda z)}}_{\text{传播引起的相位因子}} \, dx
h c ( t ) = ∫ 光瞳上的复振幅 P ( x ) A ( x ) e i ϕ ( x ) 传播引起的相位因子 e − i 2 π x t / ( λ z ) d x
光瞳相位 ϕ ( x ) \phi(x) ϕ ( x ) x x x 传播相位因子 e − i 2 π x t / ( λ z ) e^{-i 2\pi x t / (\lambda z)} e − i 2 π x t / ( λ z )
传播相位因子的来源: 从光瞳上位置 x x x t t t
r = z 2 + ( t − x ) 2 r = \sqrt{z^2 + (t-x)^2}
r = z 2 + ( t − x ) 2
令 d = t − x d = t-x d = t − x d ≪ z d \ll z d ≪ z
r = z 1 + d 2 z 2 = z ( 1 + d 2 z 2 ) 1 / 2 \begin{aligned}
r &= z \sqrt{1 + \frac{d^2}{z^2}} \\
&= z \left(1 + \frac{d^2}{z^2}\right)^{1/2}
\end{aligned}
r = z 1 + z 2 d 2 = z ( 1 + z 2 d 2 ) 1 / 2
对 ( 1 + ϵ ) α (1 + \epsilon)^\alpha ( 1 + ϵ ) α ϵ = d 2 / z 2 ≪ 1 \epsilon = d^2/z^2 \ll 1 ϵ = d 2 / z 2 ≪ 1 α = 1 / 2 \alpha = 1/2 α = 1 / 2
( 1 + ϵ ) α ≈ 1 + α ϵ + O ( ϵ 2 ) (1 + \epsilon)^\alpha \approx 1 + \alpha\epsilon + \mathcal{O}(\epsilon^2)
( 1 + ϵ ) α ≈ 1 + α ϵ + O ( ϵ 2 )
代回:
r ≈ z ( 1 + 1 2 ⋅ d 2 z 2 ) = z + ( t − x ) 2 2 z r \approx z \left(1 + \frac{1}{2} \cdot \frac{d^2}{z^2}\right) = z + \frac{(t-x)^2}{2z}
r ≈ z ( 1 + 2 1 ⋅ z 2 d 2 ) = z + 2 z ( t − x ) 2
这就是傍轴近似下传播距离的表达式。
相位延迟 Δ ϕ = 2 π λ r = 2 π λ [ z + ( t − x ) 2 2 z ] \Delta\phi = \frac{2\pi}{\lambda} r = \frac{2\pi}{\lambda}\left[z + \frac{(t-x)^2}{2z}\right] Δ ϕ = λ 2 π r = λ 2 π [ z + 2 z ( t − x ) 2 ] ( t − x ) 2 = t 2 − 2 x t + x 2 (t-x)^2 = t^2 - 2xt + x^2 ( t − x ) 2 = t 2 − 2 x t + x 2
Δ ϕ = 2 π λ z + π λ z t 2 − 2 π λ z x t + π λ z x 2 \Delta\phi = \frac{2\pi}{\lambda} z + \frac{\pi}{\lambda z} t^2 - \frac{2\pi}{\lambda z} x t + \frac{\pi}{\lambda z} x^2
Δ ϕ = λ 2 π z + λ z π t 2 − λ z 2 π x t + λ z π x 2
各项的物理命运:
2 π λ z \frac{2\pi}{\lambda} z λ 2 π z x , t x,t x , t π λ z x 2 \frac{\pi}{\lambda z} x^2 λ z π x 2 e − i π λ z x 2 e^{-i\frac{\pi}{\lambda z} x^2} e − i λ z π x 2 − 2 π λ z x t -\frac{2\pi}{\lambda z} x t − λ z 2 π x t 这是唯一保留下来的关键项
因此,在相干成像的标准定义下,只保留与光瞳形状相关的核心部分:
e i Δ ϕ 传播 = e − i 2 π λ z x t e^{i \Delta\phi_{\text{传播}}} = e^{-i \frac{2\pi}{\lambda z} x t}
e i Δ ϕ 传播 = e − i λ z 2 π x t
⚠️ 关于焦平面二次相位 π λ z t 2 \frac{\pi}{\lambda z} t^2 λ z π t 2
严格来说,夫琅禾费衍射的完整结果是:
U f ( t ) = C ⋅ e i π λ z t 2 ⋅ ∫ P ( x ) e − i 2 π λ z x t d x ⏟ h c ( t ) U_f(t) = C \cdot e^{i\frac{\pi}{\lambda z}t^2} \cdot \underbrace{\int P(x) \, e^{-i \frac{2\pi}{\lambda z} x t} \, dx}_{h_c(t)}
U f ( t ) = C ⋅ e i λ z π t 2 ⋅ h c ( t ) ∫ P ( x ) e − i λ z 2 π x t d x
其中 C C C e i π λ z t 2 e^{i\frac{\pi}{\lambda z}t^2} e i λ z π t 2
标准定义为何可省略它? 关键在于 ∣ e i π λ z t 2 ∣ = 1 |e^{i\frac{\pi}{\lambda z}t^2}| = 1 ∣ e i λ z π t 2 ∣ = 1 相位 ,不改变幅度 :
∣ U f ( t ) ∣ = ∣ C ∣ ⋅ ∣ h c ( t ) ∣ |U_f(t)| = |C| \cdot |h_c(t)|
∣ U f ( t ) ∣ = ∣ C ∣ ⋅ ∣ h c ( t ) ∣
因此:
它不改变 PSF 的幅度分布 ∣ h c ( t ) ∣ |h_c(t)| ∣ h c ( t ) ∣
它不改变光强分布 ∣ h c ( t ) ∣ 2 |h_c(t)|^2 ∣ h c ( t ) ∣ 2
它只改变焦平面上复振幅的相位分布
在相干成像理论中,脉冲响应被定义 为不含二次相位的形式:
h c ( t ) ≡ ∫ P ( x ) e − i 2 π λ z x t d x h_c(t) \equiv \int P(x) \, e^{-i \frac{2\pi}{\lambda z} x t} \, dx
h c ( t ) ≡ ∫ P ( x ) e − i λ z 2 π x t d x
这个定义是自洽的 :h c ( t ) h_c(t) h c ( t ) H c ( f ) = P ( − λ z f ) H_c(f) = P(-\lambda z f) H c ( f ) = P ( − λ z f ) P ( − λ z f ) P(-\lambda z f) P ( − λ z f )
更直观地说:二次相位 e i π λ z t 2 e^{i\frac{\pi}{\lambda z}t^2} e i λ z π t 2
核心物理图像:
光瞳上每个位置 x x x 的子波到达焦平面后,由于传播相位因子的存在,在焦平面上形成一个单一空间频率的相位分布 :
e − i 2 π f x t , 其中 f x = x λ z e^{-i 2\pi f_x t}, \quad \text{其中 } f_x = \frac{x}{\lambda z}
e − i 2 π f x t , 其中 f x = λ z x
这个子波的振幅模恒为 1(均匀分布),但它的相位在焦平面上以固定频率 f x f_x f x x x x
e − i 2 π x t / ( λ z ) = cos ( 2 π x t λ z ) − i sin ( 2 π x t λ z ) e^{-i 2\pi x t / (\lambda z)} = \cos\left(\frac{2\pi x t}{\lambda z}\right) - i \, \sin\left(\frac{2\pi x t}{\lambda z}\right)
e − i 2 π x t / ( λ z ) = cos ( λ z 2 π x t ) − i sin ( λ z 2 π x t )
实部和虚部都是随 t t t
f x = x λ z f_x = \frac{x}{\lambda z}
f x = λ z x
这个公式揭示了一个关键对应关系:光瞳上的每个空间位置 x x x f x = x / ( λ z ) f_x = x/(\lambda z) f x = x / ( λ z ) 。
焦平面上的总场 h c ( t ) h_c(t) h c ( t ) P ( x ) P(x) P ( x )
CTF H c ( f ) H_c(f) H c ( f ) f f f
从数学上看,H c ( f ) H_c(f) H c ( f ) h c ( t ) h_c(t) h c ( t ) e − i 2 π f t e^{-i 2\pi f t} e − i 2 π f t t t t
H c ( f ) = ∫ h c ( t ) e − i 2 π f t d t = ∫ [ ∫ P ( x ) e − i 2 π f x t d x ] e − i 2 π f t d t H_c(f) = \int h_c(t) \, e^{-i 2\pi f t} \, dt = \int \left[ \int P(x) \, e^{-i 2\pi f_x t} \, dx \right] e^{-i 2\pi f t} \, dt
H c ( f ) = ∫ h c ( t ) e − i 2 π f t d t = ∫ [ ∫ P ( x ) e − i 2 π f x t d x ] e − i 2 π f t d t
其中 f x = x / ( λ z ) f_x = x / (\lambda z) f x = x / ( λ z ) x x x
∫ e − i 2 π f x t ⋅ e − i 2 π f t d t = ∫ e − i 2 π ( f x + f ) t d t \int e^{-i 2\pi f_x t} \cdot e^{-i 2\pi f t} \, dt = \int e^{-i 2\pi (f_x + f) t} \, dt
∫ e − i 2 π f x t ⋅ e − i 2 π f t d t = ∫ e − i 2 π ( f x + f ) t d t
这个积分的结果是什么?分两种情况:
f x + f ≠ 0 f_x + f \neq 0 f x + f = 0 e − i 2 π ( f x + f ) t e^{-i 2\pi (f_x + f) t} e − i 2 π ( f x + f ) t t t t 零 f x + f = 0 f_x + f = 0 f x + f = 0 e 0 = 1 e^0 = 1 e 0 = 1 不为零
(用有限区间帮助理解:∫ − T / 2 T / 2 e − i 2 π ω t d t = sin ( π ω T ) π ω \int_{-T/2}^{T/2} e^{-i 2\pi \omega t} dt = \frac{\sin(\pi \omega T)}{\pi \omega} ∫ − T / 2 T / 2 e − i 2 π ω t d t = π ω sin ( π ω T ) T → ∞ T \to \infty T → ∞ ω ≠ 0 \omega \neq 0 ω = 0 [ − 1 , 1 ] [-1,1] [ − 1 , 1 ] ω = 0 \omega = 0 ω = 0 T T T
因此,只有满足 f x + f = 0 f_x + f = 0 f x + f = 0 f x = − f f_x = -f f x = − f
x λ z = − f ⇒ x = − λ z f \frac{x}{\lambda z} = -f \quad \Rightarrow \quad x = -\lambda z f
λ z x = − f ⇒ x = − λ z f
系统对频率 f f f f f f P ( − λ z f ) P(-\lambda z f) P ( − λ z f )
1.3.6. 既然已经证明 H c ( f ) = P ( − λ z f ) H_c(f) = P(-\lambda z f) H c ( f ) = P ( − λ z f )
光瞳的边界 → CTF 的边界 → 系统的频率截止边界光瞳内的相位 (如像差 e i ϕ ( x ) e^{i\phi(x)} e i ϕ ( x )
所以相干成像系统的频域响应完全由光瞳的几何形状决定 。
在相干成像中,焦平面复振幅等于物平面复振幅与相干脉冲响应 h c ( t ) h_c(t) h c ( t )
U i m g ( t ) = U o b j ( t ) ∗ h c ( t ) U_{\mathrm{img}}(t) = U_{\mathrm{obj}}(t) * h_c(t)
U i m g ( t ) = U o b j ( t ) ∗ h c ( t )
两边取傅里叶变换,卷积变乘积 :
U ~ i m g ( f ) = U ~ o b j ( f ) ⋅ H c ( f ) \tilde{U}_{\mathrm{img}}(f) = \tilde{U}_{\mathrm{obj}}(f) \cdot H_c(f)
U ~ i m g ( f ) = U ~ o b j ( f ) ⋅ H c ( f )
这说明 H c ( f ) H_c(f) H c ( f ) 频率响应函数 。
对比:相干 vs 非相干成像的完整链路
相干成像
非相干成像
照明
激光等相干光源
热光源、荧光等不相干光源
物点关系
相位相关,可干涉
相位随机,不干涉
像平面叠加量
复振幅 U U U 光强 I = ∥ U ∥ 2 I = \|U\|^2 I = ∥ U ∥ 2
空域关系
U i m g = U o b j ∗ h c U_{\mathrm{img}} = U_{\mathrm{obj}} * h_c U i m g = U o b j ∗ h c I i m g = I o b j ∗ h I_{\mathrm{img}} = I_{\mathrm{obj}} * h I i m g = I o b j ∗ h
频域关系
U ~ i m g = U ~ o b j ⋅ H c \tilde{U}_{\mathrm{img}} = \tilde{U}_{\mathrm{obj}} \cdot H_c U ~ i m g = U ~ o b j ⋅ H c I ~ i m g = I ~ o b j ⋅ H \tilde{I}_{\mathrm{img}} = \tilde{I}_{\mathrm{obj}} \cdot H I ~ i m g = I ~ o b j ⋅ H
最终光强
I i m g = ∥ U i m g ∥ 2 I_{\mathrm{img}} = \|U_{\mathrm{img}}\|^2 I i m g = ∥ U i m g ∥ 2 I i m g I_{\mathrm{img}} I i m g
其中 PSF h ( t ) = ∣ h c ( t ) ∣ 2 h(t) = |h_c(t)|^2 h ( t ) = ∣ h c ( t ) ∣ 2 H = H c ⋆ H c H = H_c \star H_c H = H c ⋆ H c
1.4. 下面严格证明:非相干 PSF 的傅里叶变换(即光学传递函数,OTF)等于相干传递函数(CTF)的自相关。
已知 :
由夫琅禾费衍射,焦平面复振幅是光瞳函数的傅里叶变换:h c ( t ) = F { P ( x ) } h_c(t) = \mathcal{F}\{P(x)\} h c ( t ) = F { P ( x ) }
相干传递函数(CTF)定义为焦平面复振幅的傅里叶变换:H c ( f ) = F { h c ( t ) } H_c(f) = \mathcal{F}\{h_c(t)\} H c ( f ) = F { h c ( t ) } H c ( f ) H_c(f) H c ( f ) P ( − λ z f ) P(-\lambda z f) P ( − λ z f )
非相干 PSF 为复振幅的模平方:h ( t ) = ∣ h c ( t ) ∣ 2 = h c ( t ) ⋅ h c ∗ ( t ) h(t) = |h_c(t)|^2 = h_c(t) \cdot h_c^*(t) h ( t ) = ∣ h c ( t ) ∣ 2 = h c ( t ) ⋅ h c ∗ ( t )
目标 :证明 F { h ( t ) } = H c ( f ) ⋆ H c ( f ) \mathcal{F}\{h(t)\} = H_c(f) \star H_c(f) F { h ( t ) } = H c ( f ) ⋆ H c ( f )
步骤一 :对 h ( t ) h(t) h ( t )
F { h ( t ) } = F { h c ( t ) ⋅ h c ∗ ( t ) } \mathcal{F}\{h(t)\} = \mathcal{F}\{h_c(t) \cdot h_c^*(t)\}
F { h ( t ) } = F { h c ( t ) ⋅ h c ∗ ( t ) }
步骤二 :应用乘积-卷积定理
两个函数乘积的傅里叶变换等于它们各自傅里叶变换的卷积:
F { g ( t ) ⋅ k ( t ) } = G ( f ) ∗ K ( f ) \mathcal{F}\{g(t) \cdot k(t)\} = G(f) * K(f)
F { g ( t ) ⋅ k ( t ) } = G ( f ) ∗ K ( f )
乘积后再傅里叶变换 = 傅里叶变换后再卷积。
F { h c ( t ) ⋅ h c ∗ ( t ) } = F { h c ( t ) } ∗ F { h c ∗ ( t ) } = H c ( f ) ∗ F { h c ∗ ( t ) } \mathcal{F}\{h_c(t) \cdot h_c^*(t)\} = \mathcal{F}\{h_c(t)\} * \mathcal{F}\{h_c^*(t)\} = H_c(f) * \mathcal{F}\{h_c^*(t)\}
F { h c ( t ) ⋅ h c ∗ ( t ) } = F { h c ( t ) } ∗ F { h c ∗ ( t ) } = H c ( f ) ∗ F { h c ∗ ( t ) }
步骤三 :复共轭的傅里叶变换
由傅里叶变换定义可直接证明:
F { g ∗ ( t ) } = G ∗ ( − f ) \mathcal{F}\{g^*(t)\} = G^*(-f)
F { g ∗ ( t ) } = G ∗ ( − f )
先取复共轭再傅里叶变换 = 先傅里叶变换再取复共轭,同时频率翻号。
证明:
F { g ∗ ( t ) } = ∫ g ∗ ( t ) e − i 2 π f t d t = [ ∫ g ( t ) e i 2 π f t d t ] ∗ = [ ∫ g ( t ) e − i 2 π ( − f ) t d t ] ∗ = G ∗ ( − f ) \mathcal{F}\{g^*(t)\} = \int g^*(t) e^{-\mathrm{i} 2\pi f t} \, dt = \left[ \int g(t) e^{\mathrm{i} 2\pi f t} \, dt \right]^* = \left[ \int g(t) e^{-\mathrm{i} 2\pi (-f) t} \, dt \right]^* = G^*(-f)
F { g ∗ ( t ) } = ∫ g ∗ ( t ) e − i 2 π f t d t = [ ∫ g ( t ) e i 2 π f t d t ] ∗ = [ ∫ g ( t ) e − i 2 π ( − f ) t d t ] ∗ = G ∗ ( − f )
因此:
F { h c ∗ ( t ) } = H c ∗ ( − f ) \mathcal{F}\{h_c^*(t)\} = H_c^*(-f)
F { h c ∗ ( t ) } = H c ∗ ( − f )
步骤四 :代入并得到自相关
F { h ( t ) } = H c ( f ) ∗ H c ∗ ( − f ) = ∫ H c ( f ′ ) H c ∗ ( − ( f − f ′ ) ) d f ′ = ∫ H c ( f ′ ) H c ∗ ( f ′ − f ) d f ′ \mathcal{F}\{h(t)\} = H_c(f) * H_c^*(-f) = \int H_c(f') H_c^*\bigl(-(f - f')\bigr) \, df' = \int H_c(f') H_c^*(f' - f) \, df'
F { h ( t ) } = H c ( f ) ∗ H c ∗ ( − f ) = ∫ H c ( f ′ ) H c ∗ ( − ( f − f ′ ) ) d f ′ = ∫ H c ( f ′ ) H c ∗ ( f ′ − f ) d f ′
上式右端正是自相关函数的定义:
( H c ⋆ H c ) ( f ) = ∫ H c ( f ′ ) H c ∗ ( f ′ − f ) d f ′ (H_c \star H_c)(f) = \int H_c(f') H_c^*(f' - f) \, df'
( H c ⋆ H c ) ( f ) = ∫ H c ( f ′ ) H c ∗ ( f ′ − f ) d f ′
对比:卷积与自相关的定义
卷积(Convolution)的标准定义为:
( g ∗ h ) ( f ) = ∫ − ∞ + ∞ g ( f ′ ) h ( f − f ′ ) d f ′ (g * h)(f) = \int_{-\infty}^{+\infty} g(f')\, h(f - f') \, df'
( g ∗ h ) ( f ) = ∫ − ∞ + ∞ g ( f ′ ) h ( f − f ′ ) d f ′
将上式与自相关定义并置,关键差异仅在于第二个因子的形式 :
运算
第二个因子的形式
核心操作
卷积
h ( f − f ′ ) h(f - f') h ( f − f ′ ) 反转 (f ′ → − f ′ f' \to -f' f ′ → − f ′
自相关
H c ∗ ( f ′ − f ) H_c^*(f' - f) H c ∗ ( f ′ − f ) 复共轭 + 平移
自相关的原始定义中,第二个因子 H c ∗ ( f ′ − f ) H_c^*(f' - f) H c ∗ ( f ′ − f ) H c ∗ H_c^* H c ∗
( H c ⋆ H c ) ( f ) = [ H c ∗ H c ∗ ( − ⋅ ) ] ( f ) = H c ( f ) ∗ H c ∗ ( − f ) (H_c \star H_c)(f) = \bigl[H_c * H_c^*(-\,\cdot\,)\bigr](f) = H_c(f) * H_c^*(-f)
( H c ⋆ H c ) ( f ) = [ H c ∗ H c ∗ ( − ⋅ ) ] ( f ) = H c ( f ) ∗ H c ∗ ( − f )
即:自相关 = 函数本身 与 其复共轭反转版本 的卷积 。步骤四中的 H c ( f ) ∗ H c ∗ ( − f ) H_c(f) * H_c^*(-f) H c ( f ) ∗ H c ∗ ( − f )
故得:
F { h ( t ) } = H c ( f ) ⋆ H c ( f ) \boxed{\mathcal{F}\{h(t)\} = H_c(f) \star H_c(f)}
F { h ( t ) } = H c ( f ) ⋆ H c ( f )
步骤五 直接代入
从步骤四得到 OTF 是 CTF 的自相关:
H ( f ) = H c ( f ) ⋆ H c ( f ) = ∫ H c ( f ′ ) H c ∗ ( f ′ − f ) d f ′ H(f) = H_c(f) \star H_c(f) = \int H_c(f')\, H_c^*(f' - f) \, df'
H ( f ) = H c ( f ) ⋆ H c ( f ) = ∫ H c ( f ′ ) H c ∗ ( f ′ − f ) d f ′
代入 H c ( f ) = P ( − λ z f ) H_c(f) = P(-\lambda z f) H c ( f ) = P ( − λ z f )
H ( f ) = ∫ P ( − λ z f ′ ) P ∗ ( − λ z ( f ′ − f ) ) d f ′ H(f) = \int P(-\lambda z f') \, P^*\bigl(-\lambda z (f' - f)\bigr) \, df'
H ( f ) = ∫ P ( − λ z f ′ ) P ∗ ( − λ z ( f ′ − f ) ) d f ′
做一次变量替换 x = − λ z f ′ x = -\lambda z f' x = − λ z f ′ f ′ = − x / ( λ z ) f' = -x/(\lambda z) f ′ = − x / ( λ z ) d f ′ = − d x / ( λ z ) df' = -dx/(\lambda z) d f ′ = − d x / ( λ z ) Δ = λ z f \Delta = \lambda z f Δ = λ z f
H ( f ) ∝ ∫ P ( x ) P ∗ ( x + Δ ) d x H(f) \propto \int P(x) \, P^*(x + \Delta) \, dx
H ( f ) ∝ ∫ P ( x ) P ∗ ( x + Δ ) d x
这就是 Hopkins 积分:OTF 正比于光瞳函数与其平移版本的复共轭之重叠积分。
1.5. 1.5.1. 由对合性 H c ( f ) = P ( − λ z f ) H_c(f) = P(-\lambda z f) H c ( f ) = P ( − λ z f ) P ( x ) P(x) P ( x ) 1 / ( λ z ) 1/(\lambda z) 1 / ( λ z ) ∣ x ∣ = D / 2 |x| = D/2 ∣ x ∣ = D / 2
∣ − λ z f ∣ = D 2 ⟹ ∣ f ∣ = D 2 λ z |-\lambda z f| = \frac{D}{2} \quad \Longrightarrow \quad |f| = \frac{D}{2\lambda z}
∣ − λ z f ∣ = 2 D ⟹ ∣ f ∣ = 2 λ z D
即 CTF 的非零支持域是一个半径为 D / ( 2 λ z ) D/(2\lambda z) D / ( 2 λ z )
1.5.2. OTF 是 CTF 的自相关(见第 5 节):
H ( f ) = H c ( f ) ⋆ H c ( f ) = ∫ H c ( f ′ ) H c ∗ ( f ′ − f ) d f ′ H(f) = H_c(f) \star H_c(f) = \int H_c(f')\, H_c^*(f' - f) \, df'
H ( f ) = H c ( f ) ⋆ H c ( f ) = ∫ H c ( f ′ ) H c ∗ ( f ′ − f ) d f ′
代入 H c ( f ) = P ( − λ z f ) H_c(f) = P(-\lambda z f) H c ( f ) = P ( − λ z f )
H ( f ) = ∫ P ( − λ z f ′ ) P ∗ ( − λ z ( f ′ − f ) ) d f ′ H(f) = \int P(-\lambda z f') \, P^*\bigl(-\lambda z (f' - f)\bigr) \, df'
H ( f ) = ∫ P ( − λ z f ′ ) P ∗ ( − λ z ( f ′ − f ) ) d f ′
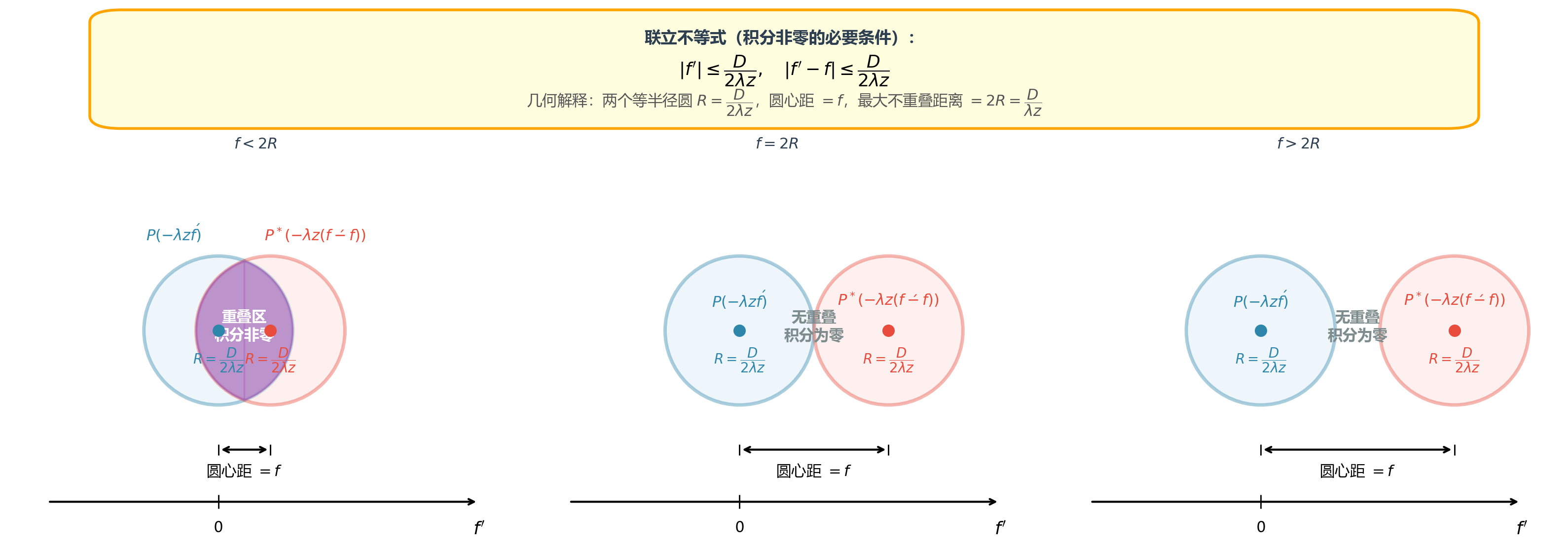
光瞳函数 P ( x ) P(x) P ( x ) 紧支撑 (compact support):对于圆孔径,P ( x ) = 0 P(x) = 0 P ( x ) = 0 ∣ x ∣ > D / 2 |x| > D/2 ∣ x ∣ > D / 2 P P P
{ ∣ − λ z f ′ ∣ ≤ D 2 ∣ − λ z ( f ′ − f ) ∣ ≤ D 2 ⟺ { ∣ f ′ ∣ ≤ D 2 λ z ∣ f ′ − f ∣ ≤ D 2 λ z \begin{cases}
|-\lambda z f'| \leq \dfrac{D}{2} \\[8pt]
|-\lambda z (f' - f)| \leq \dfrac{D}{2}
\end{cases}
\quad \Longleftrightarrow \quad
\begin{cases}
|f'| \leq \dfrac{D}{2\lambda z} \\[8pt]
|f' - f| \leq \dfrac{D}{2\lambda z}
\end{cases}
⎩ ⎪ ⎨ ⎪ ⎧ ∣ − λ z f ′ ∣ ≤ 2 D ∣ − λ z ( f ′ − f ) ∣ ≤ 2 D ⟺ ⎩ ⎪ ⎨ ⎪ ⎧ ∣ f ′ ∣ ≤ 2 λ z D ∣ f ′ − f ∣ ≤ 2 λ z D
两式联立,由三角不等式:
∣ f ∣ = ∣ f ′ − ( f ′ − f ) ∣ ≤ ∣ f ′ ∣ + ∣ f ′ − f ∣ ≤ D 2 λ z + D 2 λ z = D λ z |f| = |f' - (f' - f)| \leq |f'| + |f' - f| \leq \frac{D}{2\lambda z} + \frac{D}{2\lambda z} = \frac{D}{\lambda z}
∣ f ∣ = ∣ f ′ − ( f ′ − f ) ∣ ≤ ∣ f ′ ∣ + ∣ f ′ − f ∣ ≤ 2 λ z D + 2 λ z D = λ z D
取等边界条件 :上式最后一个等号成立要求两个不等式同时取等。
三角不等式取等要求 f ′ f' f ′ f ′ − f f'-f f ′ − f 方向相反 (共线且异号);
第二项取等要求两者同时位于各自光瞳的边缘:∣ f ′ ∣ = ∣ f ′ − f ∣ = D / ( 2 λ z ) |f'| = |f'-f| = D/(2\lambda z) ∣ f ′ ∣ = ∣ f ′ − f ∣ = D / ( 2 λ z )
因此当两个光瞳的边缘刚好外切 (圆孔径即两圆外切)时,∣ f ∣ |f| ∣ f ∣
∣ f ∣ max = D λ z |f|_{\max} = \frac{D}{\lambda z}
∣ f ∣ max = λ z D
这就是 OTF 的严格截止频率 (cutoff frequency):
∣ f ∣ ≤ D λ z (1) \boxed{|f| \leq \frac{D}{\lambda z}}
\tag{1}
∣ f ∣ ≤ λ z D ( 1 )
式 (1) 给出了 OTF 的严格截止频率 (cutoff frequency)。
1.5.2.1. H ( 0 ) H(0) H ( 0 ) 在结束支持域分析之前,需澄清一个细节:上面 Hopkins 积分给出的 H ( f ) H(f) H ( f ) 未归一化 的量。令 f = 0 f = 0 f = 0
H ( 0 ) = ∫ P ( − λ z f ′ ) P ∗ ( − λ z f ′ ) d f ′ = ∫ − ∞ + ∞ ∣ P ( − λ z f ′ ) ∣ 2 d f ′ H(0) = \int P(-\lambda z f') \, P^*(-\lambda z f') \, df'
= \int_{-\infty}^{+\infty} |P(-\lambda z f')|^2 \, df'
H ( 0 ) = ∫ P ( − λ z f ′ ) P ∗ ( − λ z f ′ ) d f ′ = ∫ − ∞ + ∞ ∣ P ( − λ z f ′ ) ∣ 2 d f ′
做变量替换 x = − λ z f ′ x = -\lambda z f' x = − λ z f ′ d x = − λ z d f ′ dx = -\lambda z \, df' d x = − λ z d f ′
H ( 0 ) = 1 λ z ∫ − ∞ + ∞ ∣ P ( x ) ∣ 2 d x = 1 λ z ⋅ S pupil H(0) = \frac{1}{\lambda z} \int_{-\infty}^{+\infty} |P(x)|^2 \, dx
= \frac{1}{\lambda z} \cdot S_{\text{pupil}}
H ( 0 ) = λ z 1 ∫ − ∞ + ∞ ∣ P ( x ) ∣ 2 d x = λ z 1 ⋅ S pupil
其中 S pupil S_{\text{pupil}} S pupil S pupil = π D 2 / 4 S_{\text{pupil}} = \pi D^2/4 S pupil = π D 2 / 4 原始 Hopkins 积分的 H ( 0 ) H(0) H ( 0 ) ,而是与光瞳面积成正比的一个常数。
工程上使用的 OTF 必须做能量归一化 ,使零频处的传递系数为 1:
H norm ( f ) = H ( f ) H ( 0 ) = ∫ P ( x ) P ∗ ( x + Δ ) d x ∫ ∣ P ( x ) ∣ 2 d x H_{\text{norm}}(f) = \frac{H(f)}{H(0)}
= \frac{\displaystyle\int P(x) \, P^*(x + \Delta) \, dx}
{\displaystyle\int |P(x)|^2 \, dx}
H norm ( f ) = H ( 0 ) H ( f ) = ∫ ∣ P ( x ) ∣ 2 d x ∫ P ( x ) P ∗ ( x + Δ ) d x
这样归一化后:
H norm ( 0 ) = 1 H_{\text{norm}}(0) = 1 H norm ( 0 ) = 1
一个重要细节 :分子 ∫ P ( x ) P ∗ ( x + Δ ) d x \int P(x) P^*(x+\Delta) \, dx ∫ P ( x ) P ∗ ( x + Δ ) d x 有像差 时一般是复数(P ( x ) = A ( x ) e i ϕ ( x ) P(x) = A(x)e^{i\phi(x)} P ( x ) = A ( x ) e i ϕ ( x ) ϕ ( x ) \phi(x) ϕ ( x ) 仅在无像差的理想衍射受限系统下严格成立 ——此时 P ( x ) P(x) P ( x ) P = 1 P=1 P = 1 P = 0 P=0 P = 0 P ( x ) P ( x + Δ ) ≥ 0 P(x)P(x+\Delta) \geq 0 P ( x ) P ( x + Δ ) ≥ 0 H norm ( f ) H_{\text{norm}}(f) H norm ( f ) f f f
对于有像差的实际系统,OTF 是复值函数,其模 ∣ H ( f ) ∣ |H(f)| ∣ H ( f ) ∣ ∣ H ( f ) ∣ ≤ H ( 0 ) = 1 |H(f)| \leq H(0) = 1 ∣ H ( f ) ∣ ≤ H ( 0 ) = 1 ∣ H ( f ) ∣ |H(f)| ∣ H ( f ) ∣
下文提到的 OTF 均指归一化后的 H norm ( f ) H_{\text{norm}}(f) H norm ( f ) H ( f ) H(f) H ( f )
1.5.3. 从上图的几何直观可以得出一个推论:在无像差的理想衍射受限系统中 ,随着 ∣ f ∣ |f| ∣ f ∣ H ( f ) H(f) H ( f ) 这一直觉需严格修正。
1.5.3.1. OTF 的物理意义是系统对不同空间频率分量的对比度衰减系数 。
当 f ≈ 0 f \approx 0 f ≈ 0 H ( 0 ) = 1 H(0) = 1 H ( 0 ) = 1 大致轮廓与平均亮度 ,对精细结构的区分能力极弱。
当 f → D / ( λ z ) f \to D/(\lambda z) f → D / ( λ z ) H ( f ) → 0 H(f) \to 0 H ( f ) → 0 高频分量恰恰承载边缘、纹理、小尺度特征等精细结构信息 ——这些信息是低频分量完全无法替代的。
因此,OTF 幅值随频率升高而下降,描述的是"系统对该频率的传递效率降低",绝非"该频率本身的信息含量更少"。相反,从成像重建的角度,高频信息往往是最珍贵 的约束:若只恢复低频,图像必然模糊;唯有高频被准确重建,细节才能显现。
1.5.3.2. OTF 衰减是一个确定性的、已知的 系统传递特性。只要 H ( f ) ≠ 0 H(f) \neq 0 H ( f ) = 0
真正使高频"难以保住"的是噪声 。高频分量在原始信号中的能量本就远低于低频,经 OTF 衰减后信号更弱;而探测器噪声(读出噪声、光子散粒噪声)在频域近似白噪声,高低频一视同仁。这导致高频处的信噪比(SNR)急剧恶化 。当信号被噪声淹没时,即使 H ( f ) H(f) H ( f )
因此,高频保护的工程本质不是"对抗 OTF 衰减",而是在 OTF 衰减既定的前提下,尽可能地提升高频信噪比、让网络学会从微弱信号中提取高频约束 。
1.5.4. 截止频率的物理本质只由光学系统决定,与仿真细节无关。下面将前文推导链在此复现,从对合性到 OTF 截止边界:
第一步:对合性给出 CTF 与光瞳的关系
由第 3 节对合性推导,相干传递函数(CTF)与光瞳函数满足:
H c ( f ) = P ( − λ z f ) H_c(f) = P(-\lambda z f)
H c ( f ) = P ( − λ z f )
这说明 CTF 的"形状"就是光瞳的缩放副本,频率坐标缩放因子为 1 / ( λ z ) 1/(\lambda z) 1 / ( λ z )
第二步:由光瞳边界得到 CTF 边界
圆孔径光瞳在 ∣ x ∣ > D / 2 |x| > D/2 ∣ x ∣ > D / 2 ∣ − λ z f ∣ > D / 2 |-\lambda z f| > D/2 ∣ − λ z f ∣ > D / 2
∣ f ∣ ≤ D 2 λ z |f| \leq \frac{D}{2\lambda z}
∣ f ∣ ≤ 2 λ z D
即 CTF 的支持域是半径为 D / ( 2 λ z ) D/(2\lambda z) D / ( 2 λ z )
第三步:由 CTF 自相关得到 OTF 边界
由第 5 节,OTF 是 CTF 的自相关:H ( f ) = H c ( f ) ⋆ H c ( f ) H(f) = H_c(f) \star H_c(f) H ( f ) = H c ( f ) ⋆ H c ( f ) D / ( 2 λ z ) D/(2\lambda z) D / ( 2 λ z )
∣ f ∣ ≤ D 2 λ z + D 2 λ z = D λ z (1) |f| \leq \frac{D}{2\lambda z} + \frac{D}{2\lambda z} = \frac{D}{\lambda z}
\tag{1}
∣ f ∣ ≤ 2 λ z D + 2 λ z D = λ z D ( 1 )
式 (1) 即为 OTF 的严格截止频率 。因此,光学系统的物理截止频率为
f cutoff = D λ z f_{\text{cutoff}} = \frac{D}{\lambda z}
f cutoff = λ z D
下面代入本系统实际参数计算。为便于对照,先列出关键参量:
参数
符号
数值
激光波长
λ \lambda λ 530 530 5 3 0
光瞳直径
D D D 60 60 6 0
光瞳到 CCD 的等效焦距
z z z 6240.79 / 5 = 1248.16 6240.79 / 5 = 1248.16 6 2 4 0 . 7 9 / 5 = 1 2 4 8 . 1 6
CCD 像素间距
Δ t C C D \Delta t_{\mathrm{CCD}} Δ t C C D 4.5 4.5 4 . 5
FFT 尺寸(M4 计算)
N 2 N_2 N 2 400 400 4 0 0
第一步:计算物理截止频率
将上表参数直接代入式 (1):
f cutoff = D λ z = 0.06 530 × 1 0 − 9 × 1.24816 ≈ 9.07 × 1 0 4 cycles/m f_{\text{cutoff}} = \frac{D}{\lambda z} = \frac{0.06}{530 \times 10^{-9} \times 1.24816} \approx 9.07 \times 10^{4} \ \text{cycles/m}
f cutoff = λ z D = 5 3 0 × 1 0 − 9 × 1 . 2 4 8 1 6 0 . 0 6 ≈ 9 . 0 7 × 1 0 4 cycles/m
第二步:计算真实数据的空间频率分辨率
真实图像总宽度为 N 2 ⋅ Δ t C C D = 400 × 4.5 μ m = 1.8 N_2 \cdot \Delta t_{\mathrm{CCD}} = 400 \times 4.5\,\mu\text{m} = 1.8 N 2 ⋅ Δ t C C D = 4 0 0 × 4 . 5 μ m = 1 . 8
Δ f = 1 N 2 ⋅ Δ t C C D = 1 400 × 4.5 × 1 0 − 6 ≈ 555.6 cycles/m \Delta f = \frac{1}{N_2 \cdot \Delta t_{\mathrm{CCD}}} = \frac{1}{400 \times 4.5 \times 10^{-6}} \approx 555.6 \ \text{cycles/m}
Δ f = N 2 ⋅ Δ t C C D 1 = 4 0 0 × 4 . 5 × 1 0 − 6 1 ≈ 5 5 5 . 6 cycles/m
第三步:计算像素坐标下的截止半径
像素坐标下的截止半径等于物理截止频率与频率分辨率之比:
r cutoff = f cutoff Δ f = N 2 ⋅ Δ t C C D ⋅ D λ z = 400 × 4.5 × 1 0 − 6 × 0.06 530 × 1 0 − 9 × 1.24816 ≈ 163 px r_{\text{cutoff}} = \frac{f_{\text{cutoff}}}{\Delta f} = \frac{N_2 \cdot \Delta t_{\mathrm{CCD}} \cdot D}{\lambda z} = \frac{400 \times 4.5 \times 10^{-6} \times 0.06}{530 \times 10^{-9} \times 1.24816} \approx 163 \ \text{px}
r cutoff = Δ f f cutoff = λ z N 2 ⋅ Δ t C C D ⋅ D = 5 3 0 × 1 0 − 9 × 1 . 2 4 8 1 6 4 0 0 × 4 . 5 × 1 0 − 6 × 0 . 0 6 ≈ 1 6 3 px
关键结论 :在 400 × 400 400 \times 400 4 0 0 × 4 0 0 H ( f ) H(f) H ( f ) 163 163 1 6 3
1.6. 1.6.1. 相位多样性波前传感中的 M4 指标由论文 Eq.(12) 定义:
M 4 ( f ) = ∣ S o ( f ) ∣ 2 − ∣ S d ( f ) ∣ 2 ∣ S o ( f ) ∣ 2 + ∣ S d ( f ) ∣ 2 M_4(f) = \frac{|S_o(f)|^2 - |S_d(f)|^2}{|S_o(f)|^2 + |S_d(f)|^2}
M 4 ( f ) = ∣ S o ( f ) ∣ 2 + ∣ S d ( f ) ∣ 2 ∣ S o ( f ) ∣ 2 − ∣ S d ( f ) ∣ 2
其中 S o ( f ) S_o(f) S o ( f ) S d ( f ) S_d(f) S d ( f ) Q ( f ) Q(f) Q ( f ) I o b j ( t ) I_{\mathrm{obj}}(t) I o b j ( t ) Q ( f ) ≡ I ~ o b j ( f ) = F { I o b j ( t ) } Q(f) \equiv \tilde{I}_{\mathrm{obj}}(f) = \mathcal{F}\{I_{\mathrm{obj}}(t)\} Q ( f ) ≡ I ~ o b j ( f ) = F { I o b j ( t ) }
S o ( f ) = Q ( f ) H o ( f ) , S d ( f ) = Q ( f ) H d ( f ) S_o(f) = Q(f) H_o(f), \quad S_d(f) = Q(f) H_d(f)
S o ( f ) = Q ( f ) H o ( f ) , S d ( f ) = Q ( f ) H d ( f )
将 S o S_o S o S d S_d S d ∣ Q ( f ) ∣ 2 |Q(f)|^2 ∣ Q ( f ) ∣ 2
M 4 ( f ) = ∣ H o ( f ) ∣ 2 − ∣ H d ( f ) ∣ 2 ∣ H o ( f ) ∣ 2 + ∣ H d ( f ) ∣ 2 M_4(f) = \frac{|H_o(f)|^2 - |H_d(f)|^2}{|H_o(f)|^2 + |H_d(f)|^2}
M 4 ( f ) = ∣ H o ( f ) ∣ 2 + ∣ H d ( f ) ∣ 2 ∣ H o ( f ) ∣ 2 − ∣ H d ( f ) ∣ 2
核心结论 :M 4 ( f ) M_4(f) M 4 ( f ) OTF 幅度 决定,与景物内容 Q ( f ) Q(f) Q ( f )
重要前提:为什么 M4 的"去目标"要求非相干成像?
上述推导中 ∣ Q ∣ 2 |Q|^2 ∣ Q ∣ 2 非相干成像模型 S = Q ⋅ H S = Q \cdot H S = Q ⋅ H
U i m g = U o b j ∗ h c ⇒ I i m g = ∣ U i m g ∣ 2 = ∣ U o b j ∗ h c ∣ 2 U_{\mathrm{img}} = U_{\mathrm{obj}} * h_c \quad \Rightarrow \quad I_{\mathrm{img}} = |U_{\mathrm{img}}|^2 = |U_{\mathrm{obj}} * h_c|^2
U i m g = U o b j ∗ h c ⇒ I i m g = ∣ U i m g ∣ 2 = ∣ U o b j ∗ h c ∣ 2
对光强 I i m g I_{\mathrm{img}} I i m g Q ⋅ H Q \cdot H Q ⋅ H
F { I i m g } = ( U ~ o b j ⋅ H c ) ⋆ ( U ~ o b j ⋅ H c ) \mathcal{F}\{I_{\mathrm{img}}\} = (\tilde{U}_{\mathrm{obj}} \cdot H_c) \star (\tilde{U}_{\mathrm{obj}} \cdot H_c)
F { I i m g } = ( U ~ o b j ⋅ H c ) ⋆ ( U ~ o b j ⋅ H c )
即复振幅频谱的自相关 。此时景物信息 Q Q Q H c H_c H c 不再严格具备"目标无关性" 。
因此,M4 方法的经典应用场景是非相干成像 (如荧光显微镜、自然光成像等)。如果系统使用相干照明(如激光),需先确保成像过程满足非相干条件,或者采用其他波前传感策略。
1.6.2. 由上式可知,M 4 ( f ) M_4(f) M 4 ( f ) ∣ H o ( f ) ∣ |H_o(f)| ∣ H o ( f ) ∣ ∣ H d ( f ) ∣ |H_d(f)| ∣ H d ( f ) ∣ ∣ H ( f ) ∣ |H(f)| ∣ H ( f ) ∣
∣ H ( f ) ∣ = 0 |H(f)| = 0 ∣ H ( f ) ∣ = 0 r > r cutoff r > r_{\text{cutoff}} r > r cutoff ∣ H ( f ) ∣ |H(f)| ∣ H ( f ) ∣ r → 0 r \to 0 r → 0
因此,M4 的频域信息分布完全继承自 OTF 的频域信息分布 。要分析 M4 在哪些频段包含波前信息,等价于分析 OTF 的幅度在哪些频段对波前像差敏感。
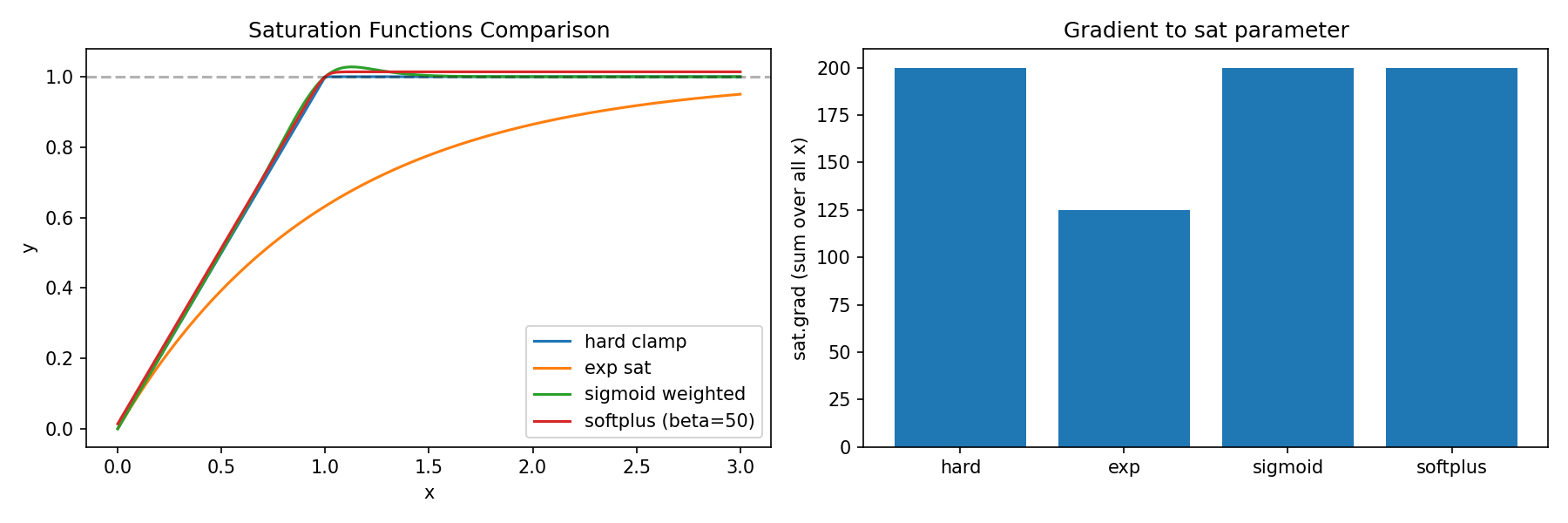
1.7. r < 4 r < 4 r < 4
术语说明 :DC 是 Direct Current(直流)的缩写。在信号处理中,DC 分量指零频率分量;在光学频域分析中,DC 对应空间频率 f = 0 f = 0 f = 0
1.7.1. f = 0 f = 0 f = 0 令 f = 0 f = 0 f = 0
H ( 0 ) ∝ ∬ P ( x ) P ∗ ( x ) d x = ∬ ∣ P ( x ) ∣ 2 d x = ∬ w 2 ( x ) d x H(0) \propto \iint P(x) P^*(x) \, \mathrm{d}x = \iint |P(x)|^2 \, \mathrm{d}x = \iint w^2(x) \, \mathrm{d}x
H ( 0 ) ∝ ∬ P ( x ) P ∗ ( x ) d x = ∬ ∣ P ( x ) ∣ 2 d x = ∬ w 2 ( x ) d x
对于无渐晕圆孔径,w ( x ) = 1 w(x) = 1 w ( x ) = 1
H ( 0 ) = const ⋅ ( 光瞳面积 ) H(0) = \text{const} \cdot (\text{光瞳面积})
H ( 0 ) = const ⋅ ( 光瞳面积 )
关键观察 :H ( 0 ) H(0) H ( 0 ) 几何面积 和振幅透射率 ,与相位畸变 ϕ ( x ) \phi(x) ϕ ( x ) 完全无关 。
因此,对于在焦和离焦系统(光瞳几何相同,仅相位不同):
H o ( 0 ) = H d ( 0 ) ⟹ M 4 ( 0 ) = H o 2 ( 0 ) − H d 2 ( 0 ) H o 2 ( 0 ) + H d 2 ( 0 ) = 0 H_o(0) = H_d(0) \implies M_4(0) = \frac{H_o^2(0) - H_d^2(0)}{H_o^2(0) + H_d^2(0)} = 0
H o ( 0 ) = H d ( 0 ) ⟹ M 4 ( 0 ) = H o 2 ( 0 ) + H d 2 ( 0 ) H o 2 ( 0 ) − H d 2 ( 0 ) = 0
物理诠释 :零频对应图像的总能量。根据 Parseval 能量守恒定理,在焦和离焦图像的总能量严格相等(假设光瞳透射率不变),因此 M4 在零频处恒为零,不携带任何像差信息。
1.7.2. 0 < r < 4 0 < r < 4 0 < r < 4 将 OTF 自相关表达式对像差做微扰展开 。设相位畸变为小量 ∣ ϕ ∣ ≪ 1 |\phi| \ll 1 ∣ ϕ ∣ ≪ 1
P ( x ) = exp [ i ϕ ( x ) ] ≈ 1 + i ϕ ( x ) − 1 2 ϕ 2 ( x ) + ⋯ P(x) = \exp[\mathrm{i}\phi(x)] \approx 1 + \mathrm{i}\phi(x) - \frac{1}{2}\phi^2(x) + \cdots
P ( x ) = exp [ i ϕ ( x ) ] ≈ 1 + i ϕ ( x ) − 2 1 ϕ 2 ( x ) + ⋯
代入 Hopkins 积分形式的 OTF:
H ( f ) ∝ ∫ P ( x ) P ∗ ( x + Δ ) d x , Δ = λ z f H(f) \propto \int P(x) \, P^*(x + \Delta) \, \mathrm{d}x, \quad \Delta = \lambda z f
H ( f ) ∝ ∫ P ( x ) P ∗ ( x + Δ ) d x , Δ = λ z f
其中 P ( x ) = exp [ i ϕ ( x ) ] P(x) = \exp[\mathrm{i}\phi(x)] P ( x ) = exp [ i ϕ ( x ) ]
P ( x ) P ∗ ( x + Δ ) = exp { i ϕ ( x ) } exp { − i ϕ ( x + Δ ) } = exp { i [ ϕ ( x ) − ϕ ( x + Δ ) ] } P(x) \, P^*(x + \Delta) = \exp\{\mathrm{i}\phi(x)\} \, \exp\{-\mathrm{i}\phi(x + \Delta)\} = \exp\{\mathrm{i}[\phi(x) - \phi(x + \Delta)]\}
P ( x ) P ∗ ( x + Δ ) = exp { i ϕ ( x ) } exp { − i ϕ ( x + Δ ) } = exp { i [ ϕ ( x ) − ϕ ( x + Δ ) ] }
于是:
H ( f ) ∝ ∬ overlap exp { i [ ϕ ( x ) − ϕ ( x + λ z f ) ] } d x H(f) \propto \iint_{\text{overlap}} \exp\{\mathrm{i}[\phi(x) - \phi(x + \lambda z f)]\} \, \mathrm{d}x
H ( f ) ∝ ∬ overlap exp { i [ ϕ ( x ) − ϕ ( x + λ z f ) ] } d x
1.7.3. 对指数函数做泰勒展开,只需要满足小频率假设 :∣ Δ ∣ = ∣ λ z f ∣ ≪ D |\Delta| = |\lambda z f| \ll D ∣ Δ ∣ = ∣ λ z f ∣ ≪ D
关键区分 :泰勒展开的条件是 ∣ δ ϕ ∣ ≪ 1 |\delta\phi| \ll 1 ∣ δ ϕ ∣ ≪ 1 δ ϕ = ϕ ( x ) − ϕ ( x + Δ ) \delta\phi = \phi(x) - \phi(x + \Delta) δ ϕ = ϕ ( x ) − ϕ ( x + Δ ) f → 0 f \to 0 f → 0 Δ → 0 \Delta \to 0 Δ → 0 ϕ ( x + Δ ) → ϕ ( x ) \phi(x + \Delta) \to \phi(x) ϕ ( x + Δ ) → ϕ ( x ) δ ϕ → 0 \delta\phi \to 0 δ ϕ → 0 这与像差本身的大小 ∣ ϕ ∣ |\phi| ∣ ϕ ∣ ——即使像差很大(如 RMS ∼ \sim ∼ f f f δ ϕ \delta\phi δ ϕ ∣ ∇ ϕ ∣ |\nabla\phi| ∣ ∇ ϕ ∣ f f f ∣ δ ϕ ∣ ≪ 1 |\delta\phi| \ll 1 ∣ δ ϕ ∣ ≪ 1
第一步:定义相位差
令平移量 Δ = λ z f \Delta = \lambda z f Δ = λ z f
δ ϕ ( x ; Δ ) = ϕ ( x ) − ϕ ( x + Δ ) \delta\phi(x; \Delta) = \phi(x) - \phi(x + \Delta)
δ ϕ ( x ; Δ ) = ϕ ( x ) − ϕ ( x + Δ )
对于光滑的波前 ϕ ( x ) \phi(x) ϕ ( x ) Δ → 0 \Delta \to 0 Δ → 0
ϕ ( x + Δ ) = ϕ ( x ) + Δ ⋅ ∇ ϕ ( x ) + O ( Δ 2 ) \phi(x + \Delta) = \phi(x) + \Delta \cdot \nabla\phi(x) + O(\Delta^2)
ϕ ( x + Δ ) = ϕ ( x ) + Δ ⋅ ∇ ϕ ( x ) + O ( Δ 2 )
因此:
δ ϕ ( x ; Δ ) = − Δ ⋅ ∇ ϕ ( x ) + O ( Δ 2 ) = O ( Δ ) \delta\phi(x; \Delta) = -\Delta \cdot \nabla\phi(x) + O(\Delta^2) = O(\Delta)
δ ϕ ( x ; Δ ) = − Δ ⋅ ∇ ϕ ( x ) + O ( Δ 2 ) = O ( Δ )
即相位差 δ ϕ \delta\phi δ ϕ ∣ Δ ∣ |\Delta| ∣ Δ ∣
第二步:指数函数的泰勒展开
由于 δ ϕ \delta\phi δ ϕ ∣ δ ϕ ∣ ≪ 1 |\delta\phi| \ll 1 ∣ δ ϕ ∣ ≪ 1 δ ϕ = 0 \delta\phi = 0 δ ϕ = 0
e i δ ϕ = 1 + i δ ϕ − 1 2 ( δ ϕ ) 2 + O ( ( δ ϕ ) 3 ) e^{\mathrm{i}\,\delta\phi} = 1 + \mathrm{i}\,\delta\phi - \frac{1}{2}(\delta\phi)^2 + O\bigl((\delta\phi)^3\bigr)
e i δ ϕ = 1 + i δ ϕ − 2 1 ( δ ϕ ) 2 + O ( ( δ ϕ ) 3 )
代入 Hopkins 积分:
H ( f ) ∝ ∬ overlap [ 1 + i δ ϕ − 1 2 ( δ ϕ ) 2 + ⋯ ] d x H(f) \propto \iint_{\text{overlap}} \left[ 1 + \mathrm{i}\,\delta\phi - \frac{1}{2}(\delta\phi)^2 + \cdots \right] \mathrm{d}x
H ( f ) ∝ ∬ overlap [ 1 + i δ ϕ − 2 1 ( δ ϕ ) 2 + ⋯ ] d x
= A overlap + i ∬ overlap δ ϕ d x ⏟ 一阶项 − 1 2 ∬ overlap ( δ ϕ ) 2 d x ⏟ 二阶项 + ⋯ = A_{\text{overlap}} + \mathrm{i} \underbrace{\iint_{\text{overlap}} \delta\phi \, \mathrm{d}x}_{\text{一阶项}} - \frac{1}{2} \underbrace{\iint_{\text{overlap}} (\delta\phi)^2 \, \mathrm{d}x}_{\text{二阶项}} + \cdots
= A overlap + i 一阶项 ∬ overlap δ ϕ d x − 2 1 二阶项 ∬ overlap ( δ ϕ ) 2 d x + ⋯
第三步:一阶项的严格分析
一阶项为:
I 1 = ∬ overlap [ ϕ ( x ) − ϕ ( x + Δ ) ] d x = ∬ overlap ϕ ( x ) d x − ∬ overlap ′ ϕ ( x ′ ) d x ′ I_1 = \iint_{\text{overlap}} [\phi(x) - \phi(x + \Delta)] \, \mathrm{d}x = \iint_{\text{overlap}} \phi(x) \, \mathrm{d}x - \iint_{\text{overlap}'} \phi(x') \, \mathrm{d}x'
I 1 = ∬ overlap [ ϕ ( x ) − ϕ ( x + Δ ) ] d x = ∬ overlap ϕ ( x ) d x − ∬ overlap ′ ϕ ( x ′ ) d x ′
其中第二个积分做了变量替换 x ′ = x + Δ x' = x + \Delta x ′ = x + Δ overlap ′ \text{overlap}' overlap ′ + Δ +\Delta + Δ
当 Δ → 0 \Delta \to 0 Δ → 0 f → 0 f \to 0 f → 0 overlap \text{overlap} overlap overlap ′ \text{overlap}' overlap ′ ∣ Δ ∣ |\Delta| ∣ Δ ∣ O ( Δ ) O(\Delta) O ( Δ )
更进一步,若像差由 Zernike 多项式构成(n > 0 n > 0 n > 0
∬ pupil Z n m ( x ) d A = 0 , ∀ n > 0 \iint_{\text{pupil}} Z_n^m(x) \, \mathrm{d}A = 0, \quad \forall\, n > 0
∬ pupil Z n m ( x ) d A = 0 , ∀ n > 0
(这是与常数项 Z 0 0 = 1 Z_0^0 = 1 Z 0 0 = 1
因此,除活塞(piston)外,所有像差模式的一阶项积分在 f → 0 f \to 0 f → 0 。
第四步:二阶项的标度行为
由第一步知 δ ϕ = O ( Δ ) = O ( f ) \delta\phi = O(\Delta) = O(f) δ ϕ = O ( Δ ) = O ( f )
( δ ϕ ) 2 = O ( f 2 ) (\delta\phi)^2 = O(f^2)
( δ ϕ ) 2 = O ( f 2 )
二阶项积分不为零,且随 f 2 f^2 f 2 f → 0 f \to 0 f → 0 f 2 f^2 f 2
总结 :
一阶项 i δ ϕ \mathrm{i}\,\delta\phi i δ ϕ f → 0 f \to 0 f → 0
二阶项 − 1 2 ( δ ϕ ) 2 -\frac{1}{2}(\delta\phi)^2 − 2 1 ( δ ϕ ) 2 f 2 f^2 f 2 δ ϕ ∝ f \delta\phi \propto f δ ϕ ∝ f
更高阶项以 f 3 , f 4 , … f^3, f^4, \dots f 3 , f 4 , …
定量结果 :通过数值微扰实验对本系统参数计算:对 0.1 waves 的 defocus 像差施加微扰,当 ∣ Δ M 4 ∣ |\Delta M_4| ∣ Δ M 4 ∣ r < 4 r < 4 r < 4 系统相关的经验值 ,依赖于像差大小与阈值选择,并非普适常数。M4 标准差在 DC 盲区内的统计占比详见"仿真路径对比"一节(路径1与路径3在截止频率外严格归零的结果佐证了 DC 盲区的物理本质)。
1.7.4. r < 4 r < 4 r < 4 上述 “4 px” 并非解析推导的结果,而是通过以下数值微扰实验得到的经验阈值 :
实验设置 :
参考臂(固定离焦) :在焦臂施加固定离焦 Z 2 0 = − 0.5 Z_2^0 = -0.5 Z 2 0 = − 0 . 5 理想在焦臂 :无额外像差(仅光瞳衍射极限)。微扰在焦臂 :在理想在焦臂上叠加 0.1 waves 的离焦微扰 Z 2 0 = + 0.1 Z_2^0 = +0.1 Z 2 0 = + 0 . 1 M4 计算 :M 4 = ∣ O T F in-focus ∣ 2 − ∣ O T F defocus ∣ 2 ∣ O T F in-focus ∣ 2 + ∣ O T F defocus ∣ 2 M_4 = \frac{|\mathrm{OTF}_{\text{in-focus}}|^2 - |\mathrm{OTF}_{\text{defocus}}|^2}{|\mathrm{OTF}_{\text{in-focus}}|^2 + |\mathrm{OTF}_{\text{defocus}}|^2}
M 4 = ∣ O T F in-focus ∣ 2 + ∣ O T F defocus ∣ 2 ∣ O T F in-focus ∣ 2 − ∣ O T F defocus ∣ 2
分别计算理想情况和微扰情况的 M 4 M_4 M 4 ∣ Δ M 4 ∣ = ∣ M 4 pert − M 4 ideal ∣ |\Delta M_4| = |M_4^{\text{pert}} - M_4^{\text{ideal}}| ∣ Δ M 4 ∣ = ∣ M 4 pert − M 4 ideal ∣ 环形平均 :对 ∣ Δ M 4 ∣ |\Delta M_4| ∣ Δ M 4 ∣ r r r s ( r ) s(r) s ( r ) 盲区判定 :从 r = 1 r = 1 r = 1 s ( r ) > 0.05 × s max s(r) > 0.05 \times s_{\max} s ( r ) > 0 . 0 5 × s max r dc r_{\text{dc}} r dc r < r dc r < r_{\text{dc}} r < r dc
为什么是 5% 阈值?
5% 是一个经验选择 ,目的是区分"有效信息区"和"噪声/无效区"。该阈值意味着:当某频率处的像差灵敏度低于峰值灵敏度的 5% 时,判定该频率对波前像差的响应已弱到可以忽略。选择 5% 而非 1% 或 10% 的理由:
1% 太严格 :会把一些仍有微弱信号的频段也划入盲区,损失信息;10% 太宽松 :会把一些灵敏度已显著衰减的区域仍保留为"信息区",引入噪声;5% 是一个工程折中 ,在信息保留和噪声抑制之间取得平衡。
为什么是 defocus 作为测试像差?
Defocus 是最常见的低阶像差,且:
它是中心对称 的(m = 0 m = 0 m = 0
在实际训练代码中,defocus 臂本身就是固定的参考臂,用 defocus 做微扰最贴近实际训练场景;
其他像差模式(tilt、coma、astigmatism)的灵敏度峰值位置不同(见后文),但它们的 DC 盲区边界都在 r < 5 r < 5 r < 5
结果复现 :运行 temp_report/analyze_three_paths_comparison.py 可得到三条路径的完整 M4 标准差统计,其中路径1与路径3在 f c f_c f c r dc ≈ 4 r_{\text{dc}} \approx 4 r dc ≈ 4
重要提醒 :4 px 是本系统参数下的经验值 。如果改变光学参数(波长、口径、焦距、CCD 像素间距)或 FFT 尺寸,该边界会变化。例如,若 FFT 尺寸从 400 改为 512,同样的物理频率对应的像素半径会按比例缩放。因此,在实际应用中应针对具体系统重新运行数值标定。
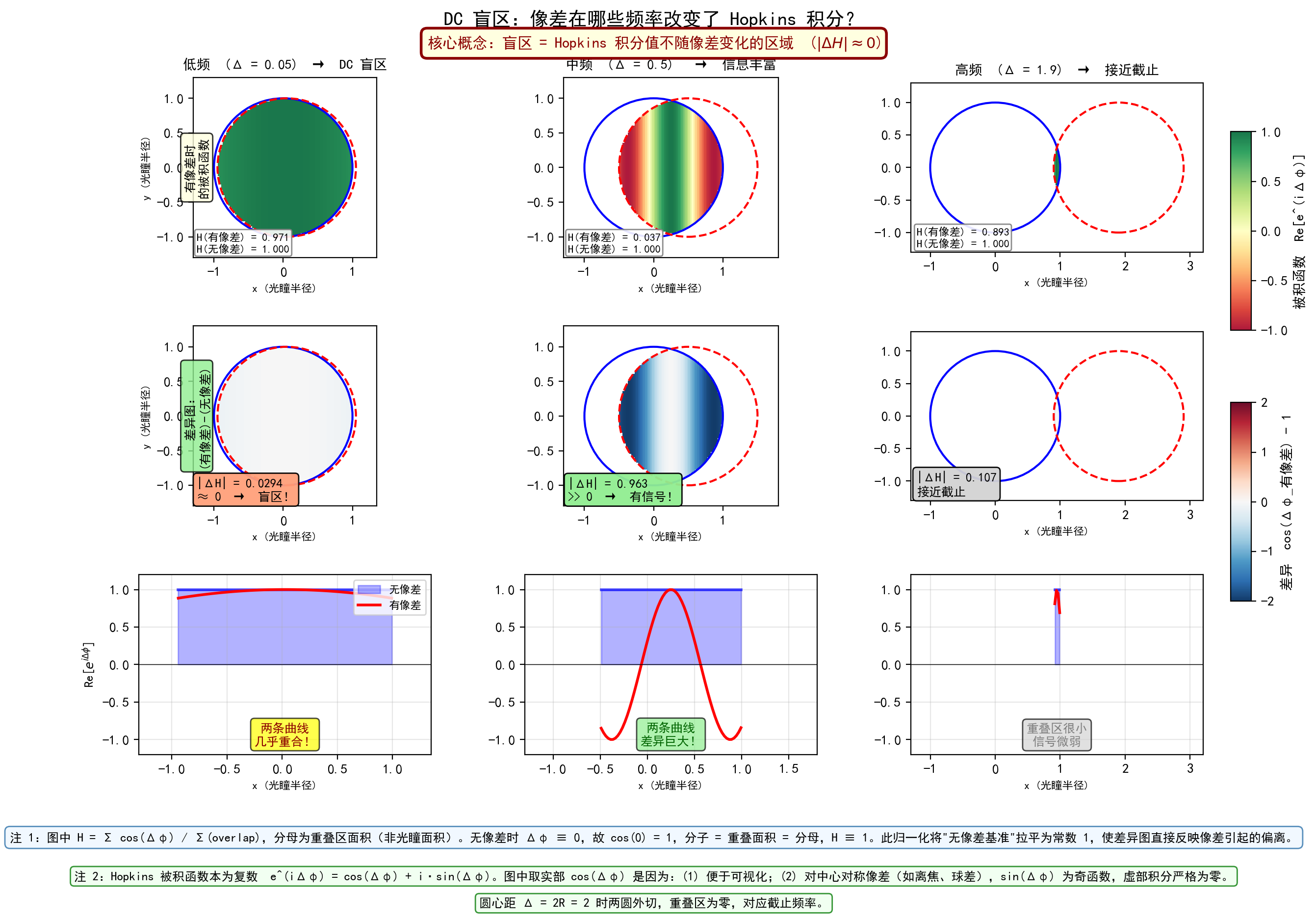
1.7.5. 下图以 Hopkins 积分的视角,展示了三个不同频率处的瞳面行为。核心对比是:有像差时 vs 无像差时,被积函数改变了多少 。如果改变像差后积分值几乎不变,该频率就是盲区。
1.7.5.1. 当频率极低时,光瞳平移量 Δ = λzf 很小。在本例中 Δ = 0.05(仅为光瞳半径的 5%),两个圆几乎完全重叠(overlap ≈ 97%)。此时:
相位差几乎为零 :Δφ(x) = φ(x) − φ(x+Δ)。由于 φ(x) 是光滑函数(Zernike 多项式),当 Δ → 0 时,Δφ → 0 处处成立,与像差大小无关:
Δ ϕ ( x ) = ϕ ( x ) − ϕ ( x + Δ ) ≈ − Δ ⋅ ∇ ϕ ( x ) → 0 ( Δ → 0 ) \Delta\phi(x) = \phi(x) - \phi(x+\Delta) \approx -\Delta \cdot \nabla\phi(x) \to 0 \quad (\Delta \to 0)
Δ ϕ ( x ) = ϕ ( x ) − ϕ ( x + Δ ) ≈ − Δ ⋅ ∇ ϕ ( x ) → 0 ( Δ → 0 )
被积函数几乎恒为 1 :e^(iΔφ) ≈ e^0 = 1,即 cos(Δφ) ≈ 1。图中有像差时的被积函数仍是均匀的绿色(≈1)。
Hopkins 积分几乎不变 :无论有像差还是无像差,分子都约等于重叠面积,分母也是重叠面积,H ≈ 1。差异图几乎空白,|ΔH| = 0.029 ≈ 0。
剖面曲线几乎重合 :沿 y = 0 的剖面显示,“有像差”(红线)与"无像差"(蓝线)几乎完全重叠——因为在这个频率下,像差几乎不影响 Hopkins 积分的值。
关键洞察 :DC 盲区的本质是 Δ → 0 导致 Δφ → 0 ,而非像差本身很小。即使像差很大(如本例中的 defocus + astigmatism),只要频率足够低,e^(iΔφ) 就恒等于 1,像差信息被完全"抹去"。
1.7.5.2. Δ = 0.5(光瞳半径的一半)时:
两个圆明显偏移,重叠区呈透镜形(overlap ≈ 69%)
相位差 Δφ 在重叠区内显著变化(红绿条纹),cos(Δφ) 剧烈振荡
像差改变了振荡模式,积分结果从 H = 1.000(无像差)暴跌到 H = 0.037(有像差)
|ΔH| = 0.963 >> 0,这是信息最丰富的区域
1.7.5.3. Δ = 1.9 接近截止条件 Δ = 2R = 2:
两个圆几乎外切,重叠区只剩一条细缝(overlap 极小)
虽然 Δφ 变化剧烈,但可积分区域太小
|ΔH| = 0.107,信号已大幅衰减
剖面图中红色 spike 只出现在极窄区间内,标注为"重叠区很小,信号微弱"
–
1.8. 4 ≤ r ≤ 152 4 \leq r \leq 152 4 ≤ r ≤ 1 5 2 1.8.1. 由 OTF 自相关表达式,OTF 在频率 f f f D D D Δ = λ z ∣ f ∣ \Delta = \lambda z |f| Δ = λ z ∣ f ∣
A overlap ( Δ ) = 2 ( D 2 ) 2 arccos ( Δ D ) − Δ ( D 2 ) 2 − Δ 2 ( 0 ≤ Δ ≤ D ) A_{\text{overlap}}(\Delta) = 2\left(\frac{D}{2}\right)^2 \arccos\!\left(\frac{\Delta}{D}\right) - \Delta \sqrt{\left(\frac{D}{2}\right)^2 - \Delta^2}
\quad (0 \leq \Delta \leq D)
A overlap ( Δ ) = 2 ( 2 D ) 2 arccos ( D Δ ) − Δ ( 2 D ) 2 − Δ 2 ( 0 ≤ Δ ≤ D )
当 Δ → 0 \Delta \to 0 Δ → 0 f → 0 f \to 0 f → 0 A overlap → π D 2 / 4 A_{\text{overlap}} \to \pi D^2/4 A overlap → π D 2 / 4 Δ ϕ → 0 \Delta\phi \to 0 Δ ϕ → 0
当 Δ → D \Delta \to D Δ → D f → f cutoff f \to f_{\text{cutoff}} f → f cutoff A overlap → 0 A_{\text{overlap}} \to 0 A overlap → 0
当 Δ ≈ 0.3 D – 0.7 D \Delta \approx 0.3D \text{–} 0.7D Δ ≈ 0 . 3 D – 0 . 7 D 0.5 – 0.8 0.5 \text{–} 0.8 0 . 5 – 0 . 8 Δ ϕ \Delta\phi Δ ϕ
1.8.2. 通过数值微扰分析(固定离焦,在焦臂施加 0.1 waves 单模式像差,计算 ∣ Δ M 4 ∣ |\Delta M_4| ∣ Δ M 4 ∣
像差模式
Zernike 符号
峰值灵敏度半径 r peak r_{\text{peak}} r peak
物理解释
Tilt
Z 1 ± 1 Z_1^{\pm 1} Z 1 ± 1 r ≈ 151 r \approx 151 r ≈ 1 5 1 倾斜导致像平移,PSF 平移在功率谱中产生高频干涉条纹,调制在接近截止频率处最强
Defocus
Z 2 0 Z_2^0 Z 2 0 r ≈ 8 r \approx 8 r ≈ 8 离焦为径向二次函数,在固定离焦臂参考下,低频差异最显著
Astigmatism
Z 2 ± 2 Z_2^{\pm 2} Z 2 ± 2 r ≈ 151 r \approx 151 r ≈ 1 5 1 与 tilt 类似,主要在接近截止频率处调制 OTF
Coma
Z 3 ± 1 Z_3^{\pm 1} Z 3 ± 1 r ≈ 8 r \approx 8 r ≈ 8 彗差的三次径向依赖使其在低频区域产生显著响应
Spherical
Z 4 0 Z_4^0 Z 4 0 r ≈ 150 r \approx 150 r ≈ 1 5 0 球差为四次径向函数,主要调制中高频 OTF
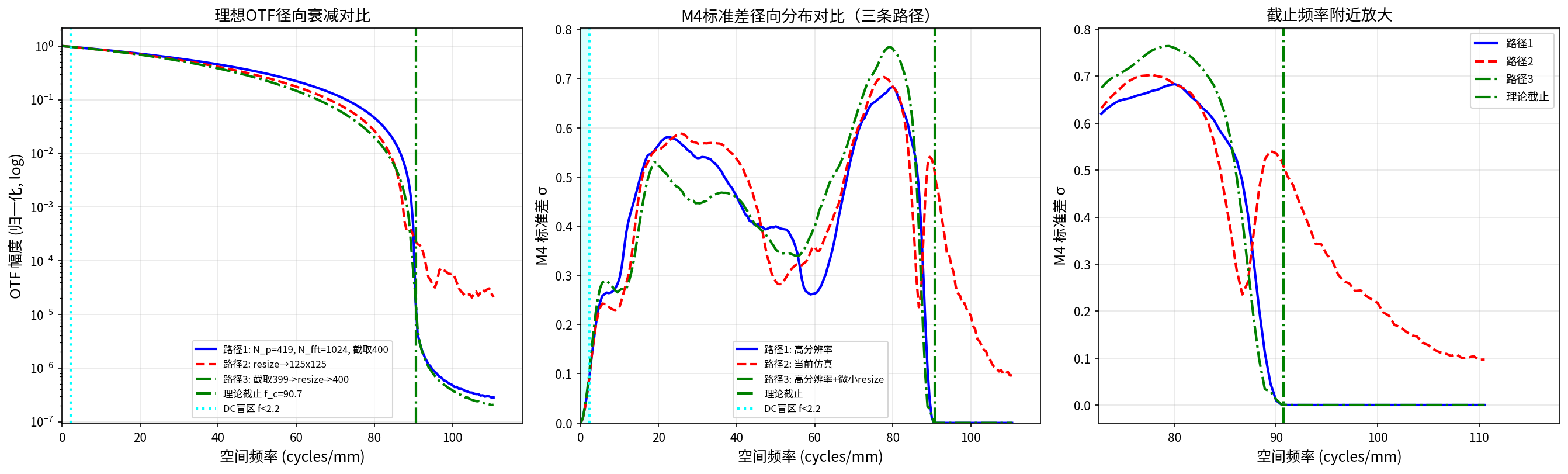
数据来源 :temp_report/analyze_three_paths_comparison.py 中对 5 种低阶 Zernike 模式独立施加 0.1λ 扰动,在固定离焦臂参考下计算 ∣ Δ M 4 ∣ |\Delta M_4| ∣ Δ M 4 ∣ 本系统参数下 的数值结果,不同光学系统的像差灵敏度分布会有所不同。各模式灵敏度峰值的图示详见"仿真路径对比"一节中的 fig_two_paths_comparison_physical_freq.png(左子图,理想OTF径向衰减对比)。
1.9. 前文通过 Hopkins 积分的严格推导得到了 OTF 的截止频率 f c = D / ( λ z ) f_c = D/(\lambda z) f c = D / ( λ z )
1.9.1. 路径1:高分辨率真实路径(开窗截取,像元近似匹配)
光瞳采样 :419 × 419 419 \times 419 4 1 9 × 4 1 9 零填充 :将 419 × 419 419 \times 419 4 1 9 × 4 1 9 1024 × 1024 1024 \times 1024 1 0 2 4 × 1 0 2 4 第一次 FFT(光瞳 → PSF) :对零填充后的 1024 × 1024 1024 \times 1024 1 0 2 4 × 1 0 2 4 1024 × 1024 1024 \times 1024 1 0 2 4 × 1 0 2 4 PSF → 400 × 400 400 \times 400 4 0 0 × 4 0 0 :从 1024 × 1024 1024 \times 1024 1 0 2 4 × 1 0 2 4 开窗截取 400 × 400 400 \times 400 4 0 0 × 4 0 0 Δ t 1 = λ z ⋅ 419 / ( 1024 ⋅ D ) ≈ 4.51 μ \Delta t_1 = \lambda z \cdot 419 / (1024 \cdot D) \approx 4.51\ \mu Δ t 1 = λ z ⋅ 4 1 9 / ( 1 0 2 4 ⋅ D ) ≈ 4 . 5 1 μ 4.5 μ 4.5\ \mu 4 . 5 μ 0.3% 第二次 FFT(PSF → OTF) :对截取的 400 × 400 400 \times 400 4 0 0 × 4 0 0 400 × 400 400 \times 400 4 0 0 × 4 0 0 截止像素 (400 坐标):r c , 1 = 400 × 419 / 1024 ≈ 163.7 r_{c,1} = 400 \times 419 / 1024 \approx 163.7 r c , 1 = 4 0 0 × 4 1 9 / 1 0 2 4 ≈ 1 6 3 . 7
路径2:当前仿真路径(resize 插值,像元精确匹配)
光瞳采样 :51 × 51 51 \times 51 5 1 × 5 1 零填充 :将 51 × 51 51 \times 51 5 1 × 5 1 256 × 256 256 \times 256 2 5 6 × 2 5 6 第一次 FFT(光瞳 → PSF) :对零填充后的 256 × 256 256 \times 256 2 5 6 × 2 5 6 256 × 256 256 \times 256 2 5 6 × 2 5 6 PSF → 400 × 400 400 \times 400 4 0 0 × 4 0 0 :通过 skimage.transform.resize 将 256 × 256 256 \times 256 2 5 6 × 2 5 6 125 × 125 125 \times 125 1 2 5 × 1 2 5 anti_aliasing=True),再将 125 × 125 125 \times 125 1 2 5 × 1 2 5 400 × 400 400 \times 400 4 0 0 × 4 0 0 Δ t 2 = λ z ⋅ 51 / ( 125 ⋅ D ) ≈ 4.50 μ \Delta t_2 = \lambda z \cdot 51 / (125 \cdot D) \approx 4.50\ \mu Δ t 2 = λ z ⋅ 5 1 / ( 1 2 5 ⋅ D ) ≈ 4 . 5 0 μ 精确匹配 CCD 像素间隔第二次 FFT(PSF → OTF) :对 400 × 400 400 \times 400 4 0 0 × 4 0 0 400 × 400 400 \times 400 4 0 0 × 4 0 0 截止像素 (400 坐标):r c , 2 = 400 × 51 / 125 ≈ 163.2 r_{c,2} = 400 \times 51 / 125 \approx 163.2 r c , 2 = 4 0 0 × 5 1 / 1 2 5 ≈ 1 6 3 . 2
路径3:高分辨率 + 微小 resize 补偿路径(像元严格匹配)
光瞳采样 :419 × 419 419 \times 419 4 1 9 × 4 1 9 零填充 :将 419 × 419 419 \times 419 4 1 9 × 4 1 9 1024 × 1024 1024 \times 1024 1 0 2 4 × 1 0 2 4 第一次 FFT(光瞳 → PSF) :对零填充后的 1024 × 1024 1024 \times 1024 1 0 2 4 × 1 0 2 4 1024 × 1024 1024 \times 1024 1 0 2 4 × 1 0 2 4 PSF → 400 × 400 400 \times 400 4 0 0 × 4 0 0 :从 1024 × 1024 1024 \times 1024 1 0 2 4 × 1 0 2 4 开窗截取 399 × 399 399 \times 399 3 9 9 × 3 9 9 resize 插值到 400 × 400 400 \times 400 4 0 0 × 4 0 0 400 / 399 ≈ 1.0025 400 / 399 \approx 1.0025 4 0 0 / 3 9 9 ≈ 1 . 0 0 2 5 Δ t 3 ≈ 4.500 μ \Delta t_3 \approx 4.500\ \mu Δ t 3 ≈ 4 . 5 0 0 μ 0.00% 第二次 FFT(PSF → OTF) :对 400 × 400 400 \times 400 4 0 0 × 4 0 0 400 × 400 400 \times 400 4 0 0 × 4 0 0 截止像素 (400 坐标):r c , 3 = 400 × 419 / 1024 ≈ 163.7 r_{c,3} = 400 \times 419 / 1024 \approx 163.7 r c , 3 = 4 0 0 × 4 1 9 / 1 0 2 4 ≈ 1 6 3 . 7
三条路径的核心差异在"PSF 如何得到 400 × 400 400 \times 400 4 0 0 × 4 0 0 开窗截取 (无插值,像元有 0.3% 误差),路径2通过大幅 resize (256→125,缩放因子 0.488),路径3通过开窗截取 + 微小 resize (399→400,缩放因子 1.0025,像元严格匹配)。
1.9.2. 由于三条路径的 PSF 像素间隔几乎相同(均约 4.5 μ 4.5\ \mu 4 . 5 μ
Δ f = 1 400 ⋅ Δ t ≈ 1 400 × 4.5 × 1 0 − 6 ≈ 555.6 cycles/m \Delta f = \frac{1}{400 \cdot \Delta t} \approx \frac{1}{400 \times 4.5 \times 10^{-6}} \approx 555.6\ \text{cycles/m}
Δ f = 4 0 0 ⋅ Δ t 1 ≈ 4 0 0 × 4 . 5 × 1 0 − 6 1 ≈ 5 5 5 . 6 cycles/m
像素半径 r r r f = r ⋅ Δ f f = r \cdot \Delta f f = r ⋅ Δ f
路径
PSF 像素间隔 Δ t \Delta t Δ t
400-FFT 频率分辨率 Δ f \Delta f Δ f
截止像素 r c r_c r c
r c r_c r c
路径1
≈ 4.51 μ \approx 4.51\ \mu ≈ 4 . 5 1 μ ≈ 555.6 \approx 555.6 ≈ 5 5 5 . 6 163.7 px
f c = 90.7 f_c = 90.7 f c = 9 0 . 7
路径2
≈ 4.50 μ \approx 4.50\ \mu ≈ 4 . 5 0 μ ≈ 555.6 \approx 555.6 ≈ 5 5 5 . 6 163.2 px
f c = 90.7 f_c = 90.7 f c = 9 0 . 7
路径3
≈ 4.50 μ \approx 4.50\ \mu ≈ 4 . 5 0 μ ≈ 555.6 \approx 555.6 ≈ 5 5 5 . 6 163.7 px
f c = 90.7 f_c = 90.7 f c = 9 0 . 7
理论截止频率(与路径无关):
f c = D λ z = 0.06 530 × 1 0 − 9 × 1.24816 ≈ 9.07 × 1 0 4 cycles/m = 90.7 cycles/mm f_c = \frac{D}{\lambda z} = \frac{0.06}{530 \times 10^{-9} \times 1.24816} \approx 9.07 \times 10^{4}\ \text{cycles/m} = 90.7\ \text{cycles/mm}
f c = λ z D = 5 3 0 × 1 0 − 9 × 1 . 2 4 8 1 6 0 . 0 6 ≈ 9 . 0 7 × 1 0 4 cycles/m = 9 0 . 7 cycles/mm
1.9.3. 对 100 个随机波前(低阶 Zernike 系数服从 N ( 0 , 0. 1 2 ) \mathcal{N}(0, 0.1^2) N ( 0 , 0 . 1 2 ) σ M 4 ( f ) \sigma_{M_4}(f) σ M 4 ( f )
物理频率 f f f
路径1 std
路径2 std
路径3 std
70 cycles/mm
0.560
0.575
0.609
80 cycles/mm
0.683
0.683
0.760
85 cycles/mm
0.568
0.438
0.617
90 cycles/mm
0.010 0.536 0.012
91 cycles/mm
5.4 × 1 0 − 5 5.4 \times 10^{-5} 5 . 4 × 1 0 − 5 0.487 8.7 × 1 0 − 5 8.7 \times 10^{-5} 8 . 7 × 1 0 − 5
92 cycles/mm
1.6 × 1 0 − 5 1.6 \times 10^{-5} 1 . 6 × 1 0 − 5 0.435 1.7 × 1 0 − 5 1.7 \times 10^{-5} 1 . 7 × 1 0 − 5
95 cycles/mm
4 × 1 0 − 6 4 \times 10^{-6} 4 × 1 0 − 6 0.320 3 × 1 0 − 6 3 \times 10^{-6} 3 × 1 0 − 6
数值来源与复现代码 :本节全部数值与图表由 temp_report/analyze_three_paths_comparison.py 生成。该脚本包含三条路径的完整实现(光瞳采样、零填充、FFT、PSF→400×400、OTF 计算、M4 标准差统计、绘图),直接运行即可复现结果:
1 cd temp_report && python3 analyze_three_paths_comparison.py
输出:
fig_three_paths_comparison.png(三条路径合一对比图)fig_three_paths_psf_otf_m4.png(相同 Zernike 系数下的 PSF/FFT Power/M4 可视化对比)
1.9.4. 为更直观地理解三条路径的差异,下面使用同一组 Zernike 系数(Z 1 1 = 0.10 Z_1^1=0.10 Z 1 1 = 0 . 1 0 Z 2 0 = 0.20 Z_2^0=0.20 Z 2 0 = 0 . 2 0 Z 2 − 2 = 0.15 Z_2^{-2}=0.15 Z 2 − 2 = 0 . 1 5 Z 3 1 = 0.10 Z_3^1=0.10 Z 3 1 = 0 . 1 0 Z 4 0 = 0.05 Z_4^0=0.05 Z 4 0 = 0 . 0 5 Z 2 0 = − 0.50 Z_2^0=-0.50 Z 2 0 = − 0 . 5 0 generative_M4_model.py 中的 defocus_coefficient_um = -0.5 \times 0.530$ μm 相对应(− 0.265 -0.265 − 0 . 2 6 5 − 0.50 -0.50 − 0 . 5 0 test_optical_param.py 中真实数据的显示方式完全一致:PSF 经 min-max 归一化后用 gray 线性显示,FFT Power 用 log1p + hot 显示,M4 用 coolwarm 显示且固定范围为 [ − 1 , 1 ] [-1, 1] [ − 1 , 1 ]
观察要点 :
PSF :三条路径的 PSF 均显示完整的 400 × 400 400 \times 400 4 0 0 × 4 0 0 125 × 125 125 \times 125 1 2 5 × 1 2 5 FFT Power :路径1 和路径3 的能量严格限制在圆形光瞳支持域内,截止频率外几乎完全为零;路径2 在截止频率外存在明显的环形噪声伪影。M4 :路径1 和路径3 的 M4 在截止频率外基本干净;路径2 在截止频率外出现清晰的径向条纹状伪影——这正是其在统计上产生虚假"信息含量"的直接来源。
1.9.5. 路径1和路径3验证了理论截止
在 f c = 90.7 f_c = 90.7 f c = 9 0 . 7 1 0 − 5 10^{-5} 1 0 − 5 ∣ f ∣ ≤ D / ( λ z ) |f| \leq D/(\lambda z) ∣ f ∣ ≤ D / ( λ z )
路径2的 resize 引入伪影——问题的根源是 resize 的缩放因子远离 1
路径2在 f c f_c f c resize 插值在 PSF 中注入了超出光瞳支持域的高频分量。
关键发现来自路径3 :路径3也使用了 resize,但缩放因子仅为 400 / 399 ≈ 1.0025 400/399 \approx 1.0025 4 0 0 / 3 9 9 ≈ 1 . 0 0 2 5
问题不在于"resize 本身",而在于"resize 的缩放因子远离 1" 。
resize(默认双线性插值)本质上是"重新采样 + 低通滤波"的组合。当缩放因子远离 1 时(如路径2的 0.488):
插值核需要在原始像素之间"创造"大量新像素,这些新像素的值是周围像素的加权平均;
加权平均的过程会引入原始 PSF 中不存在的频谱成分——尤其是超出物理截止频率的高频尾部被"泄漏"到 resize 后的图像中;
这些伪高频分量与随机像差耦合后,在 M4 计算的分母(∣ S o ∣ 2 + ∣ S d ∣ 2 + ε |S_o|^2 + |S_d|^2 + \varepsilon ∣ S o ∣ 2 + ∣ S d ∣ 2 + ε ε = 1 0 − 8 \varepsilon = 10^{-8} ε = 1 0 − 8
当缩放因子接近 1 时(如路径3的 1.0025),每个新像素几乎完全由最近邻的原始像素决定,插值核的频谱泄漏极小,伪影可以忽略。
对本项目的启示
当前训练代码(generative_M4_model.py)中的 F.interpolate(..., mode="area") 步骤与路径2的 resize 等价——都是从一个小尺寸的 PSF 大幅缩放(∼ 0.5 × \sim 0.5\times ∼ 0 . 5 × r > 152 r > 152 r > 1 5 2
后续改进可考虑两个方向:
提高光瞳采样分辨率 (如 419 × 419 419 \times 419 4 1 9 × 4 1 9 1024 × 1024 1024 \times 1024 1 0 2 4 × 1 0 2 4 在 M4 loss 中显式施加物理截止掩膜 ,屏蔽 f > f c f > f_c f > f c
1.10. 1.10.1. m4_loss 的全图等权重问题当前的实现(train_utils.py):
1 2 3 4 def m4_loss (sim_m4, real_m4, denoise_sigma=1.0 ): real_m4 = TVF.gaussian_blur(real_m4, kernel_size=5 , sigma=denoise_sigma) sim_m4 = TVF.gaussian_blur(sim_m4, kernel_size=5 , sigma=denoise_sigma) return F.smooth_l1_loss(sim_m4, real_m4)
该实现隐含地对 M4 图的所有频率像素赋予相等权重 。根据上述物理分析(400 坐标),这意味着:
约 0.04% 的像素(DC 盲区,r < 4 r < 4 r < 4 :在匹配一个理论上与像差无关、期望为零的量,浪费梯度;约 42.3% 的像素(超截止区,r > 152 r > 152 r > 1 5 2 :在匹配纯数值噪声或相机噪声,引入随机梯度干扰,甚至可能导致过拟合噪声伪影;仅约 **57.7% 的像素(中频带 4 ≤ r ≤ 152 4 \leq r \leq 152 4 ≤ r ≤ 1 5 2
1.10.2. 基于本项目的光学参数(N p = 51 N_p = 51 N p = 5 1 N 1 = 256 N_1 = 256 N 1 = 2 5 6 N 2 = 400 N_2 = 400 N 2 = 4 0 0 4.5 μ m 4.5\,\mu\text{m} 4 . 5 μ m 环形通带 :
M ( f ) = { 1 , 4 ≤ ∣ f ∣ ≤ 152 px 0 , otherwise \mathcal{M}(f) = \begin{cases}
1, & 4 \leq |f| \leq 152 \, \text{px} \\[6pt]
0, & \text{otherwise}
\end{cases}
M ( f ) = ⎩ ⎨ ⎧ 1 , 0 , 4 ≤ ∣ f ∣ ≤ 1 5 2 px otherwise
内径 4 px 屏蔽 DC 盲区(本系统参数下的数值实验结果),外径 152 px 为数值实现中的有效截止半径(理论严格截止为 163 px,实际仿真中因 resize 插值模糊导致 OTF 高频能量提前衰减)。
1.10.3. 论文第 10 页描述了实际 GRNN 训练时的关键处理:
“Only the center 256 x 256 pixels from each image were used to calculate M4… The elements contain either dc and low-frequency components that have no phase information or they are noise elements that are outside of the system cutoff frequency . By calculating the standard deviation of each element across the 343 arrays, we selected a subset of only the most significant elements. The 100 elements with the highest standard deviation were chosen from each array.”
这与数值分析完全一致:论文作者通过统计方法(跨样本标准差)自动发现了"中频信息带"的存在,并仅使用这 100 个元素作为神经网络输入。全图共 256 × 256 = 65536 256 \times 256 = 65536 2 5 6 × 2 5 6 = 6 5 5 3 6 绝大多数频率像素是无信息的 。
1.10.4. 1.10.4.1. M4 定义:
M 4 ( f ) = ∣ S o ( f ) ∣ 2 − ∣ S d ( f ) ∣ 2 ∣ S o ( f ) ∣ 2 + ∣ S d ( f ) ∣ 2 + ε M_4(f) = \frac{|S_o(f)|^2 - |S_d(f)|^2}{|S_o(f)|^2 + |S_d(f)|^2 + \varepsilon}
M 4 ( f ) = ∣ S o ( f ) ∣ 2 + ∣ S d ( f ) ∣ 2 + ε ∣ S o ( f ) ∣ 2 − ∣ S d ( f ) ∣ 2
在非相干成像模型下,焦面和离焦面 OTF 的支持域均严格限制在光学截止频率内:
H o ( f ) = H d ( f ) = 0 , ∣ f ∣ > f c = D λ z H_o(f) = H_d(f) = 0, \quad |f| > f_c = \frac{D}{\lambda z}
H o ( f ) = H d ( f ) = 0 , ∣ f ∣ > f c = λ z D
因此真实信号在超截止区满足:
∣ S o true ( f ) ∣ 2 = ∣ S d true ( f ) ∣ 2 = 0 , ∣ f ∣ > f c |S_o^{\text{true}}(f)|^2 = |S_d^{\text{true}}(f)|^2 = 0, \quad |f| > f_c
∣ S o true ( f ) ∣ 2 = ∣ S d true ( f ) ∣ 2 = 0 , ∣ f ∣ > f c
从而**
M 4 true ( f ) = 0 , ∣ f ∣ > f c M_4^{\text{true}}(f) = 0, \quad |f| > f_c
M 4 true ( f ) = 0 , ∣ f ∣ > f c
这是高频四角区域偏置估计的根本依据 :四角区域测得的任何非零 M 4 M_4 M 4
1.10.4.2. 设采集到的频谱包含加性噪声:
S o = S o true + N o , S d = S d true + N d S_o = S_o^{\text{true}} + N_o, \quad S_d = S_d^{\text{true}} + N_d
S o = S o true + N o , S d = S d true + N d
分子中的噪声 :
∣ S o ∣ 2 − ∣ S d ∣ 2 = ∣ S o true ∣ 2 − ∣ S d true ∣ 2 ⏟ 信号项 + ∣ N o ∣ 2 − ∣ N d ∣ 2 ⏟ 噪声功率差 + 2 Re ( S o true N o ∗ − S d true N d ∗ ) ⏟ 信号-噪声交叉项 |S_o|^2 - |S_d|^2 = \underbrace{|S_o^{\text{true}}|^2 - |S_d^{\text{true}}|^2}_{\text{信号项}} + \underbrace{|N_o|^2 - |N_d|^2}_{\text{噪声功率差}} + \underbrace{2\text{Re}\left(S_o^{\text{true}}N_o^* - S_d^{\text{true}}N_d^*\right)}_{\text{信号-噪声交叉项}}
∣ S o ∣ 2 − ∣ S d ∣ 2 = 信号项 ∣ S o true ∣ 2 − ∣ S d true ∣ 2 + 噪声功率差 ∣ N o ∣ 2 − ∣ N d ∣ 2 + 信号 - 噪声交叉项 2 Re ( S o true N o ∗ − S d true N d ∗ )
如果噪声零均值、独立同分布,噪声功率差与交叉项的期望均为零。因此分子中噪声在期望意义上相互抵消 。
分母中的噪声 :
∣ S o ∣ 2 + ∣ S d ∣ 2 = ∣ S o true ∣ 2 + ∣ S d true ∣ 2 ⏟ 信号功率和 + ∣ N o ∣ 2 + ∣ N d ∣ 2 ⏟ 噪声功率和 + 2 Re ( S o true N o ∗ + S d true N d ∗ ) ⏟ 交叉项 |S_o|^2 + |S_d|^2 = \underbrace{|S_o^{\text{true}}|^2 + |S_d^{\text{true}}|^2}_{\text{信号功率和}} + \underbrace{|N_o|^2 + |N_d|^2}_{\text{噪声功率和}} + \underbrace{2\text{Re}\left(S_o^{\text{true}}N_o^* + S_d^{\text{true}}N_d^*\right)}_{\text{交叉项}}
∣ S o ∣ 2 + ∣ S d ∣ 2 = 信号功率和 ∣ S o true ∣ 2 + ∣ S d true ∣ 2 + 噪声功率和 ∣ N o ∣ 2 + ∣ N d ∣ 2 + 交叉项 2 Re ( S o true N o ∗ + S d true N d ∗ )
交叉项期望仍为零,但噪声功率和期望不为零,而是累加 。这导致:
M 4 ( f ) = 信号差 信号和 + 噪声和 + ε M_4(f) = \frac{\text{信号差}}{\text{信号和} + \text{噪声和} + \varepsilon}
M 4 ( f ) = 信号和 + 噪声和 + ε 信号差
分母被噪声"撑大",把 M 4 M_4 M 4 b b b
1.10.4.3. 在超截止区 ∣ f ∣ > f c |f| > f_c ∣ f ∣ > f c
M 4 obs ( f ) = b + n ( f ) , ∣ f ∣ > f c M_4^{\text{obs}}(f) = b + n(f), \quad |f| > f_c
M 4 obs ( f ) = b + n ( f ) , ∣ f ∣ > f c
其中 b b b n ( f ) n(f) n ( f ) Ω c \Omega_c Ω c
b ^ = median f ∈ Ω c [ M 4 obs ( f ) ] \hat{b} = \underset{f \in \Omega_c}{\text{median}} \left[ M_4^{\text{obs}}(f) \right]
b ^ = f ∈ Ω c median [ M 4 obs ( f ) ]
扣除后的 M4 为:
M ~ 4 ( f ) = M 4 obs ( f ) − b ^ \tilde{M}_4(f) = M_4^{\text{obs}}(f) - \hat{b}
M ~ 4 ( f ) = M 4 obs ( f ) − b ^
工程实现:
1 2 3 4 5 6 7 8 9 10 def estimate_m4_bias (m4, corner=8 ): corners = torch.cat([ m4[..., :corner, :corner].flatten(start_dim=2 ), m4[..., :corner, -corner:].flatten(start_dim=2 ), m4[..., -corner:, :corner].flatten(start_dim=2 ), m4[..., -corner:, -corner:].flatten(start_dim=2 ), ], dim=2 ) bias = corners.median(dim=2 , keepdim=True )[0 ].view(-1 , 1 , 1 , 1 ) return bias
1.10.4.4. 有效的情况 :
全局/低频偏置占主导 :b b b 两臂噪声功率不平衡 :例如焦面与离焦面探测器增益不同,或 dataset.py 中逐样本 min-max 归一化破坏了对称性;超截止区干净 :没有 resize 插值泄漏等结构化 artifact,噪声统计近似平稳。
有限或无效的情况 :
偏置频率相关 :若噪声功率谱不是白谱,b ( f ) b(f) b ( f ) 超截止区被 resize 污染 :resize 插值会在 f > f c f > f_c f > f c 噪声极低 :SNR 很高时偏置本身很小,扣除收益有限;非高斯/非加性噪声 :读出噪声、光子噪声统计复杂,简单中位数估计可能不准确。
1.10.4.5. 必须严格区分超截止区非零值的两个不同来源,因为它们的处理方法完全不同。
来源一:噪声偏置(适合四角扣除)
真实数据中的相机噪声、读出噪声以及 dataset.py 中逐样本 min-max 归一化,会在 M4 分母中引入额外的功率项。如果焦面和离焦面两臂的噪声功率不完全平衡,就会产生一个近似加性、全局或低频变化 的偏置 b b b
不携带波前像差信息;
在超截止区近似均匀(白噪声功率谱近似常数);
通过高频四角估计并全局扣除后,中频带的物理信号不会被扭曲。
来源二:仿真频谱泄漏(不适合简单四角扣除)
仿真中的超截止区非零值往往来自光瞳边缘离散化、圆形孔径在矩形 FFT 网格上的采样、以及 Zernike 高阶模式在 pupil 边界处的截断。这些成分的共同特征是:
结构化 :呈现 sinc 旁瓣、径向条纹等模式,不是白噪声;与像差相关 :不同波前、不同像差组合下,泄漏 pattern 会变化;非均匀 :在超截止区内不是常数,而是随频率位置变化。
如果用四角中位数估计一个全局 b ^ \hat{b} b ^
判断标准 :
特征
噪声偏置
频谱泄漏
来源
真实数据相机噪声、归一化
仿真离散化、 pupil 边缘采样
空间分布
近似均匀/低频
结构化 sinc/条纹
与像差相关性
弱
强
对扣除的响应
安全有效
可能扭曲信号
正确处理方法
四角偏置扣除
增大 N p N_p N p
因此,在引入四角偏置扣除前,必须先确认仿真 M4 在超截止区足够干净 。如果仿真本身存在显著频谱泄漏,应优先修复仿真,而不是用扣除掩盖。
1.10.4.6. 这是一个关键问题。由于损失函数最终会对截止区外置零(频率掩膜),单独改善截止区外的 M 4 M_4 M 4
假设观测到的 M4 可写为:
M 4 obs ( f ) = M 4 true ( f ) + b ( f ) + n ( f ) M_4^{\text{obs}}(f) = M_4^{\text{true}}(f) + b(f) + n(f)
M 4 obs ( f ) = M 4 true ( f ) + b ( f ) + n ( f )
其中 b ( f ) b(f) b ( f ) n ( f ) n(f) n ( f ) b ^ \hat{b} b ^
M ~ 4 ( f ) = M 4 true ( f ) + ( b ( f ) − b ^ ) + n ( f ) \tilde{M}_4(f) = M_4^{\text{true}}(f) + (b(f) - \hat{b}) + n(f)
M ~ 4 ( f ) = M 4 true ( f ) + ( b ( f ) − b ^ ) + n ( f )
情况一:b ( f ) b(f) b ( f )
偏置扣除不改变仿真与真实数据的差值。Smooth L1 损失对常数偏置的梯度为零。因此偏置扣除完全不影响训练 ,没有必要。
情况二:b ( f ) b(f) b ( f )
例如真实数据有相机噪声偏置,仿真无偏置。此时损失函数会有一个常数偏移,但梯度仍不受影响。偏置扣除改善损失数值,不影响优化方向。
情况三:b ( f ) b(f) b ( f )
例如 dataset.py 中逐样本 min-max 归一化导致每个样本的偏置不同。此时偏置进入损失函数的梯度:
∂ L ∂ θ = 1 ∣ Ω mask ∣ ∑ f ∈ Ω mask sign ( M ~ 4 sim − M ~ 4 real ) ⋅ ∂ M ~ 4 sim ∂ θ \frac{\partial \mathcal{L}}{\partial \theta} = \frac{1}{|\Omega_{\text{mask}}|} \sum_{f \in \Omega_{\text{mask}}} \text{sign}\left(\tilde{M}_4^{\text{sim}} - \tilde{M}_4^{\text{real}}\right) \cdot \frac{\partial \tilde{M}_4^{\text{sim}}}{\partial \theta}
∂ θ ∂ L = ∣ Ω mask ∣ 1 f ∈ Ω mask ∑ sign ( M ~ 4 sim − M ~ 4 real ) ⋅ ∂ θ ∂ M ~ 4 sim
样本相关的偏置会随机改变 M ~ 4 real \tilde{M}_4^{\text{real}} M ~ 4 real 此时偏置扣除是必要的。
情况四:b ( f ) b(f) b ( f )
如前所述,频谱泄漏不是常数偏置。用四角中位数估计 b ^ \hat{b} b ^ 此时偏置扣除有害。
1.10.4.6.1.
场景
是否需要偏置扣除
原因
仅使用频率掩膜,无显著全局偏置
不需要
截止区外已被屏蔽,中频区不受影响
真实数据存在样本相关的全局偏置
需要
污染中频区梯度
真实数据存在严格常数偏置
可选
改善损失数值,不影响优化
仿真存在显著频谱泄漏
不应扣除
会扭曲中频信号
因此,偏置扣除不是改善截止区外,而是去除可能泄漏到中频区的样本相关偏置。 在已经使用频率掩膜的前提下,如果真实数据的预处理已经规范、样本间偏置稳定,偏置扣除的收益可能有限。
1.10.4.7. 四角偏置扣除不能替代 环形频率掩膜:
偏置扣除 :解决系统性偏移(bias),主要针对样本相关的真实数据噪声;频率掩膜 :解决随机噪声和伪影(variance),对仿真泄漏和真实噪声都适用。
最佳实践是先确保仿真无显著泄漏,再考虑扣除偏置,最后施加掩膜 。
1 2 3 4 5 6 7 8 9 def m4_loss (sim_m4, real_m4, mask, denoise_sigma=1.0 ): sim_m4 = sim_m4 - estimate_m4_bias(sim_m4) real_m4 = real_m4 - estimate_m4_bias(real_m4) real_m4 = TVF.gaussian_blur(real_m4, kernel_size=5 , sigma=denoise_sigma) sim_m4 = TVF.gaussian_blur(sim_m4, kernel_size=5 , sigma=denoise_sigma) return F.smooth_l1_loss(sim_m4 * mask, real_m4 * mask)
这样可以同时消除系统偏移和随机噪声干扰。
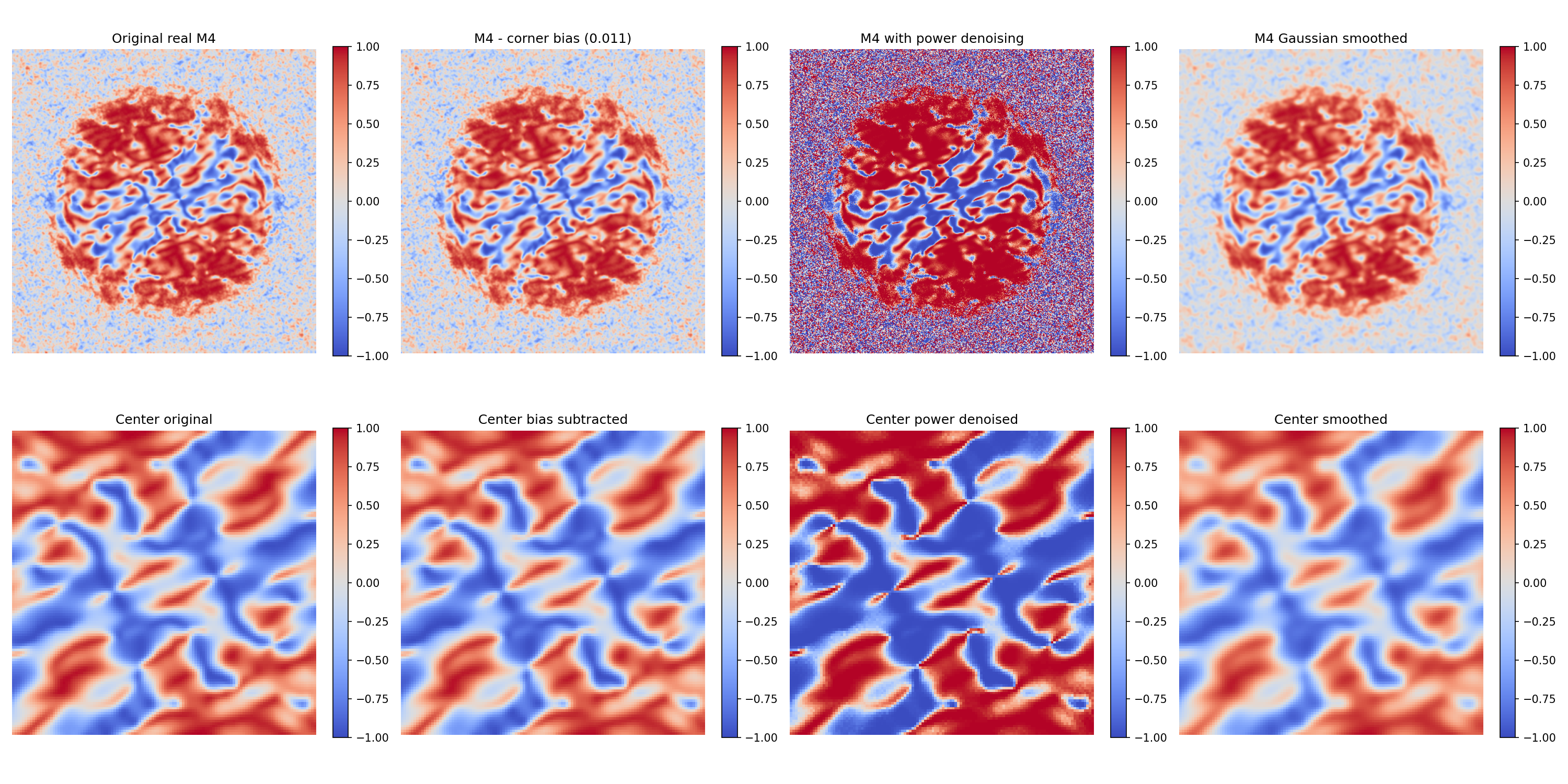
1.10.5. 为了验证上述理论分析,我们对 temp_m4_nosie/test_results_latest_temp/test/raw_data/ 中保存的仿真与真实 M4 进行了定量诊断。该目录包含同一组测试样本在三种状态下的输出:
*_m4_init.npy:训练后模型直接前向传播的仿真 M4;*_m4_real.npy:真实采集数据计算得到的 M4;*_m4_train.npy:经过端到端训练优化后的仿真 M4。
1.10.5.1. 取四角高频区域(每角 32 × 32 32 \times 32 3 2 × 3 2 4 × 3 2 2 = 4096 4 \times 32^2 = 4096 4 × 3 2 2 = 4 0 9 6
1.10.5.2. 表 1:M4 四角区域统计量(超截止区)
类型
corner mean
corner median
corner std
init(仿真)
+0.47 +0.48 0.01
real(真实)
-0.02
-0.02
0.20
train(优化后仿真)
-0.11
-0.14
0.23
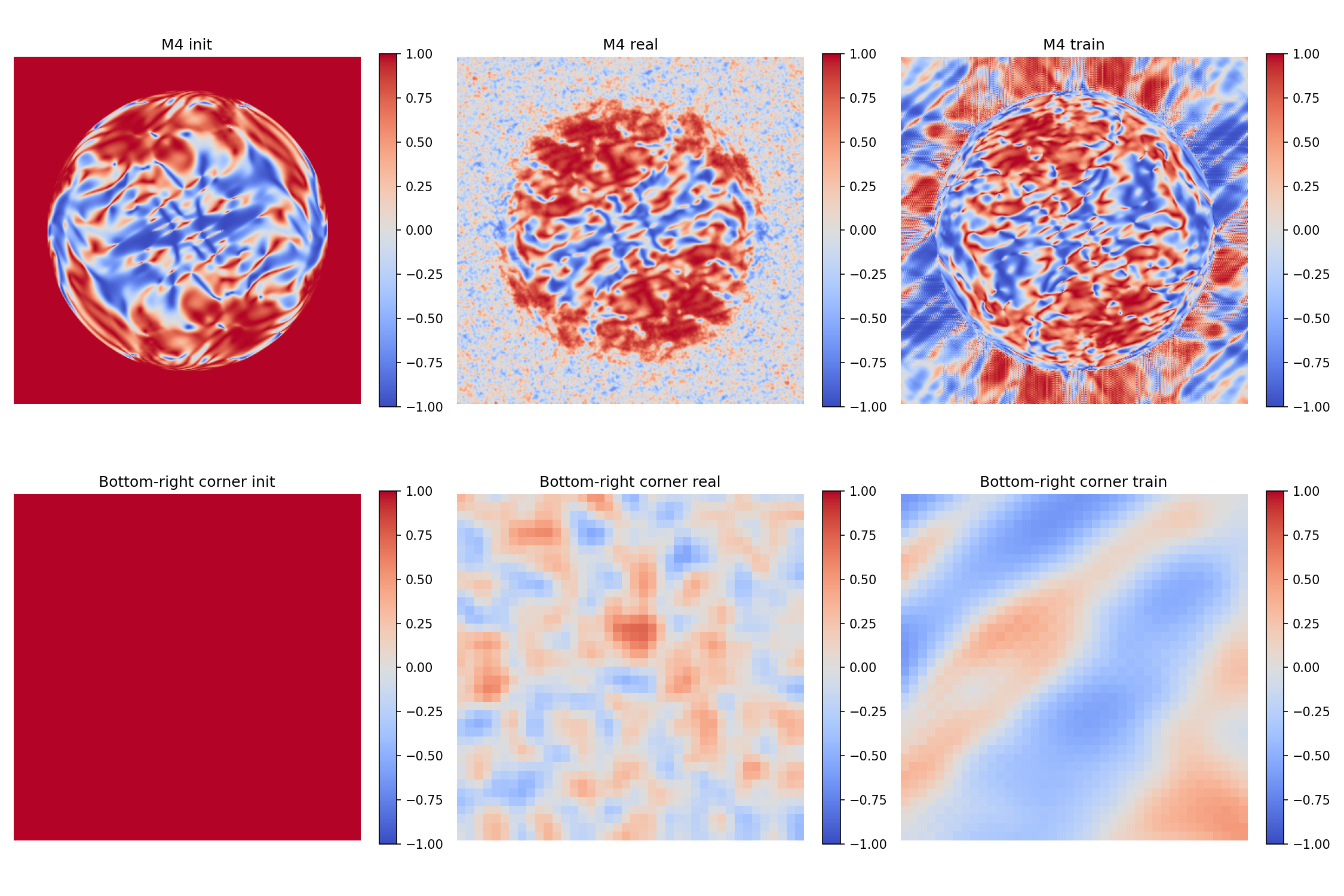
init 的四角值高度稳定(标准差仅 0.01),强烈表明它不是随机噪声,而是系统性 artifact 。
下图直观展示了这一现象。上行是三种 M4 的全图,可见 init 在截止频率外呈现均匀的红色(约 +1.0),而 real 和 train 的截止频率外接近零。下行是右下角 40 × 40 40 \times 40 4 0 × 4 0
图注 :batch_0000_sample_00 的 M4 全图(上行)与右下角放大(下行)。颜色范围固定为 [ − 1 , 1 ] [-1, 1] [ − 1 , 1 ]
表 2:四角区域焦面/离焦面 FFT power 对比
类型
焦面 ∣ S o ∣ 2 \vert S_o \vert^2 ∣ S o ∣ 2
离焦面 ∣ S d ∣ 2 \vert S_d \vert^2 ∣ S d ∣ 2
推得 M4
init
4.1 × 1 0 − 4 4.1 \times 10^{-4} 4 . 1 × 1 0 − 4 1.2 × 1 0 − 22 1.2 \times 10^{-22} 1 . 2 × 1 0 − 2 2 ≈ 1.0
real
2.4 × 1 0 − 2 2.4 \times 10^{-2} 2 . 4 × 1 0 − 2 2.2 × 1 0 − 2 2.2 \times 10^{-2} 2 . 2 × 1 0 − 2 ≈ 0.04
train
3.0 × 1 0 − 17 3.0 \times 10^{-17} 3 . 0 × 1 0 − 1 7 1.9 × 1 0 − 16 1.9 \times 10^{-16} 1 . 9 × 1 0 − 1 6 ≈ 0
1.10.5.3.
仿真 init 的超截止区 M4 接近 +1.0 ,原因是焦面 FFT power 在超截止区有 4.1 × 1 0 − 4 4.1 \times 10^{-4} 4 . 1 × 1 0 − 4 。根据 M4 定义:
M 4 = ∣ S o ∣ 2 − ∣ S d ∣ 2 ∣ S o ∣ 2 + ∣ S d ∣ 2 + ε ≈ 4.1 × 1 0 − 4 4.1 × 1 0 − 4 + 1 0 − 8 ≈ 1.0 M_4 = \frac{|S_o|^2 - |S_d|^2}{|S_o|^2 + |S_d|^2 + \varepsilon} \approx \frac{4.1 \times 10^{-4}}{4.1 \times 10^{-4} + 10^{-8}} \approx 1.0
M 4 = ∣ S o ∣ 2 + ∣ S d ∣ 2 + ε ∣ S o ∣ 2 − ∣ S d ∣ 2 ≈ 4 . 1 × 1 0 − 4 + 1 0 − 8 4 . 1 × 1 0 − 4 ≈ 1 . 0
真实数据的两臂功率量级相当 (都在 1 0 − 2 10^{-2} 1 0 − 2
训练后的仿真两臂功率都极低 (1 0 − 16 ∼ 1 0 − 17 10^{-16} \sim 10^{-17} 1 0 − 1 6 ∼ 1 0 − 1 7
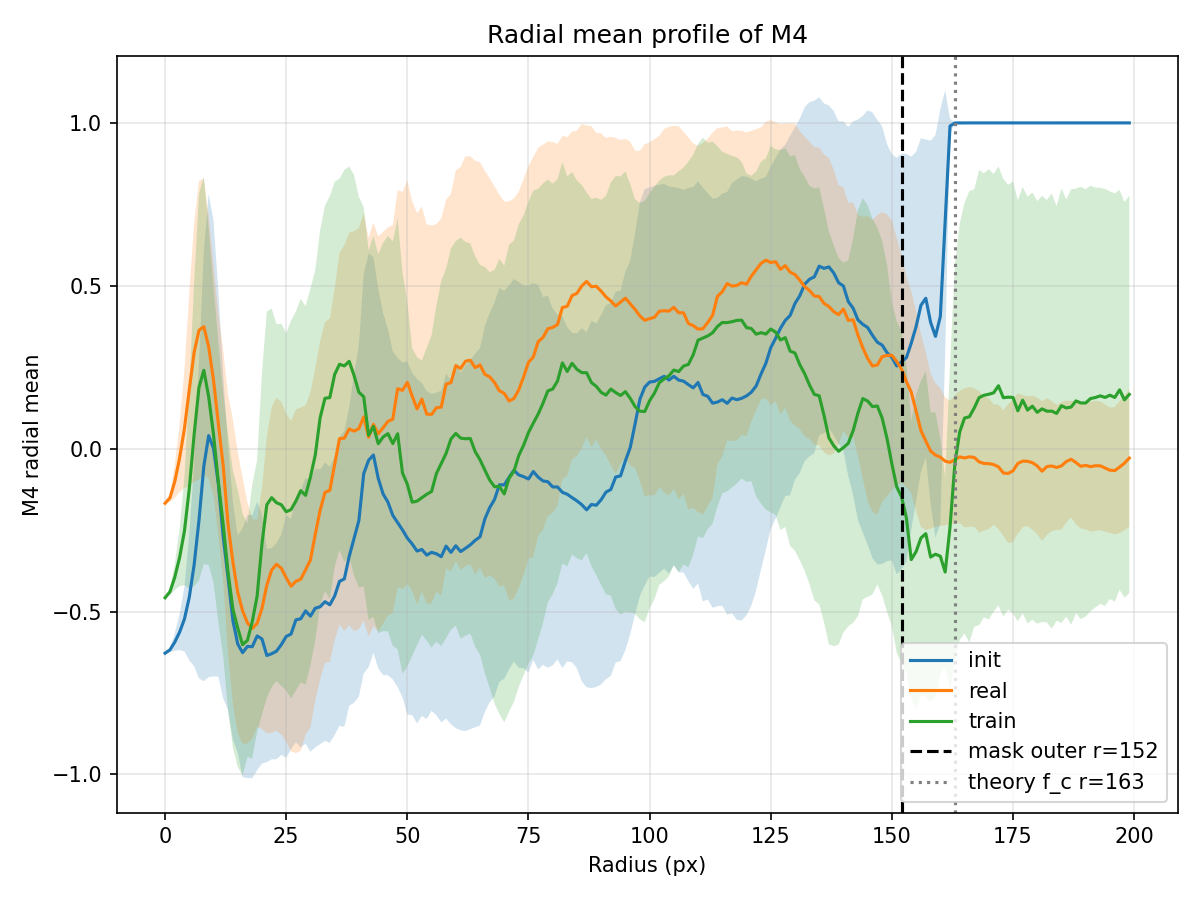
下图给出了径向平均分布,进一步验证上述结论。蓝色曲线(init)在 r ≈ 152 r \approx 152 r ≈ 1 5 2
图注 :三种 M4 的径向平均曲线(阴影为标准差)。虚线 r = 152 r=152 r = 1 5 2 r = 163 r=163 r = 1 6 3
1.10.5.4. 综合表 1 和表 2,仿真 init 的超截止区非零值不符合噪声偏置的特征 :
噪声应该是随机的、两臂功率相当的;
而这里表现为焦面单臂有稳定能量、离焦面几乎为零 ,这是焦面 PSF 的频谱泄漏 。
可能的泄漏来源包括:
逐样本、逐通道 min-max 归一化破坏了两臂能量比例;
detector 高斯核或软饱和参数 sat_focus/sat_defocus 不对称;grid_sample 空间仿射变换引入插值高频;光瞳边缘离散化导致的焦面 PSF ringing。
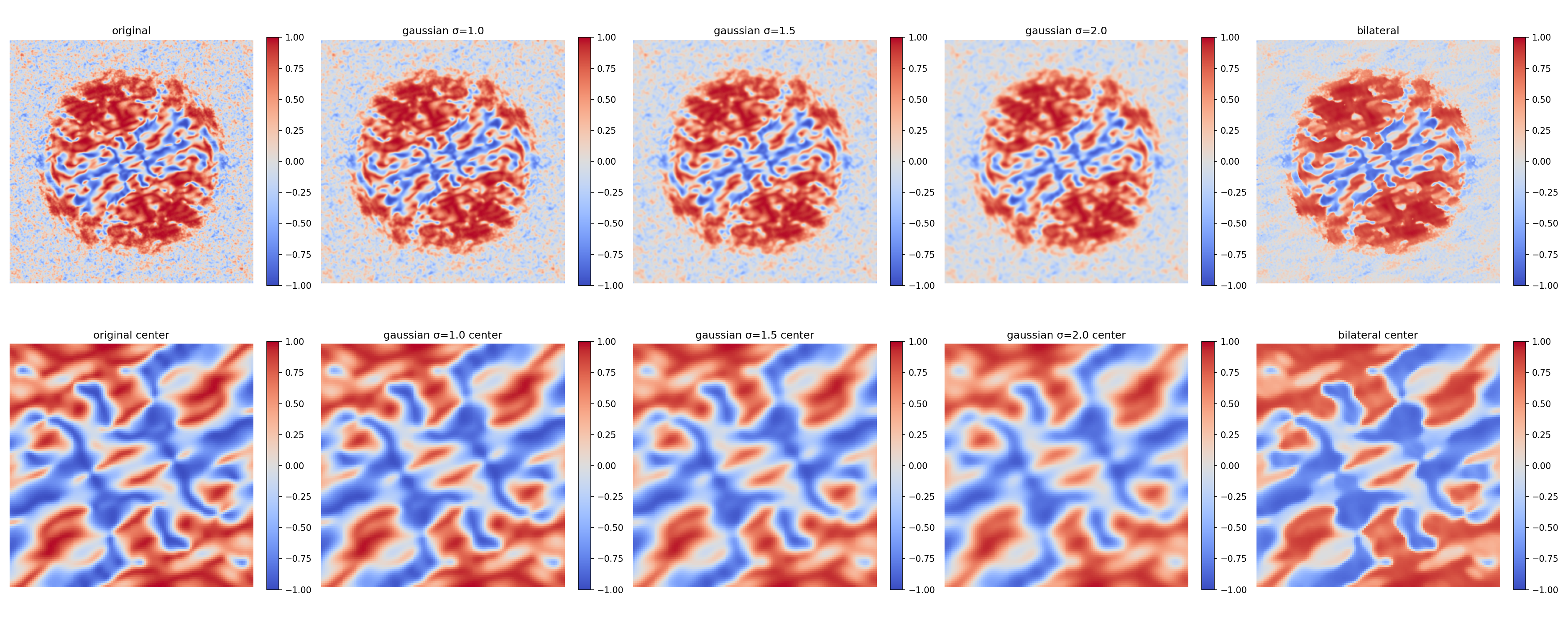
1.10.6. 除了对仿真泄漏的诊断,我们还定量测试了多种针对真实 M4 的去噪/扣除方法,目标是在不损失中频物理信号的前提下抑制噪声。
1.10.6.1. 以 batch_0000_sample_00 的真实 M4 为例,测试以下四种方法:
四角偏置扣除 :从 M4 全图减去四角中位数估计的偏置 b ^ \hat{b} b ^ FFT 功率谱扣除 :分别从焦面/离焦面功率谱中减去四角估计的噪声功率,再重新计算 M4;高斯平滑 :对 M4 做不同 σ \sigma σ 双边滤波 :保边去噪,作为高斯平滑的替代。
1.10.6.2. 对真实 M4 估计四角中位数:
b ^ = median ( M 4 real ( Ω c ) ) = 0.011 \hat{b} = \text{median}(M_4^{\text{real}}(\Omega_c)) = 0.011
b ^ = median ( M 4 real ( Ω c ) ) = 0 . 0 1 1
该偏置非常小。扣除后:
频段
原始 std
偏置扣除后 std
low (4–50 px)
0.593
0.593
mid (50–100 px)
0.573
0.573
high (100–152 px)
0.478
0.478
结论 :标准差完全不变,仅整体平移了 0.011。真实数据的四角偏置极小,全局扣除没有意义。
1.10.6.3. 从焦面和离焦面功率谱中分别减去四角估计的噪声功率:
∣ S o ′ ∣ 2 = max ( ∣ S o ∣ 2 − N ^ o , 0 ) , ∣ S d ′ ∣ 2 = max ( ∣ S d ∣ 2 − N ^ d , 0 ) \vert S_o' \vert^2 = \max(\vert S_o \vert^2 - \hat{N}_o, 0), \quad \vert S_d' \vert^2 = \max(\vert S_d \vert^2 - \hat{N}_d, 0)
∣ S o ′ ∣ 2 = max ( ∣ S o ∣ 2 − N ^ o , 0 ) , ∣ S d ′ ∣ 2 = max ( ∣ S d ∣ 2 − N ^ d , 0 )
再重新计算 M4:
频段
原始 std
功率谱扣除后 std
low (4–50 px)
0.593
0.789
mid (50–100 px)
0.573
0.735
high (100–152 px)
0.478
0.684
结论 :标准差反而增大。独立估计两路噪声功率并相减会引入额外方差,对本数据有害 。
1.10.6.4. 对真实 M4 做不同 σ \sigma σ
σ \sigma σ low std
mid std
high std
0(原始)
0.593
0.573
0.478
0.5
0.587
0.569
0.474
1.0
0.568
0.557
0.460
1.5 0.543 0.541 0.443
2.0
0.514
0.525
0.425
3.0
0.455
0.492
0.392
结论 :高斯平滑能有效降低各频段标准差,且均值保持不变。σ = 1.0 ∼ 1.5 \sigma = 1.0 \sim 1.5 σ = 1 . 0 ∼ 1 . 5
1.10.6.5. 双边滤波在抑制噪声的同时保留边缘:
频段
原始 std
双边滤波后 std
low (4–50 px)
0.593
0.569
mid (50–100 px)
0.573
0.556
high (100–152 px)
0.478
0.444
效果与 σ ≈ 1.0 ∼ 1.5 \sigma \approx 1.0 \sim 1.5 σ ≈ 1 . 0 ∼ 1 . 5
1.10.6.6. 下图对比了原始 M4、四角偏置扣除、功率谱扣除和高斯平滑(σ = 1.5 \sigma=1.5 σ = 1 . 5
图注 :真实 M4 的四种处理方法对比。上行全图,下行中心 120 × 120 120 \times 120 1 2 0 × 1 2 0
下图进一步对比了不同 σ \sigma σ
图注 :真实 M4 在不同高斯平滑参数和双边滤波下的效果。σ = 1.0 ∼ 1.5 \sigma=1.0 \sim 1.5 σ = 1 . 0 ∼ 1 . 5 σ = 2.0 \sigma=2.0 σ = 2 . 0
1.10.6.7.
真实数据的"噪声"主要表现为中频随机波动,不是全局偏置 。因此:
四角偏置扣除无效;
FFT 功率谱扣除有害;
高斯平滑是当前最合适的去噪手段 。
当前 m4_loss 中的 TVF.gaussian_blur(real_m4, kernel_size=5, sigma=denoise_sigma) 是合理的 。可将 denoise_sigma 从默认值 1.0 尝试调整到 1.5 ,在抑制噪声和保留细节之间取得更好平衡。
若计算资源允许 ,双边滤波可作为高斯平滑的替代,但收益有限,且需要引入 skimage 依赖。
根本解决方案 :改善真实数据采集质量(更长曝光、更低噪声相机)或增加训练样本数量,从数据源头降低噪声。
1.10.6.8. 简单用四角中位数估计全局偏置并扣除并不可取 。因为这会把这个结构性泄漏当作均匀偏置处理,可能扭曲中频区的物理信号。
可行做法 (按优先级):
优先修复仿真源头
检查 min-max 归一化:当前代码对每个样本、每个通道(焦/离焦)分别归一化,可能破坏能量比例。可改为联合归一化 或按总能量归一化。
检查 detector 参数:确保焦面和离焦面的高斯 sigma、软饱和阈值对称。
检查 grid_sample 引入的高频 artifact。
临时措施:收紧频率掩膜
如果暂时无法修复源头,可将环形掩膜外径从 152 px 降到 140~145 px ,避免使用截止区边缘可能被泄漏污染的区域。
若必须做偏置扣除
只对真实数据 做四角偏置扣除(因为真实数据的四角接近白噪声,存在样本间偏置),而不对仿真数据扣除 (因为仿真的是结构化泄漏)。但这也只能改善真实数据的基线,不能解决仿真泄漏问题。
1.11. M4 的频域信息分布并非均匀,而是由光学传递函数的数学结构 严格决定:
DC 盲区(r < 4 r < 4 r < 4 :Zernike 像差(除活塞外)在单位圆上的面积分为零,导致 OTF 在零频附近对像差不敏感。本系统的数值实验表明该区域 M4 标准差占比仅 0.21% 。注:DC 盲区的边界是系统相关的经验值,依赖于像差大小与阈值选择。
中频信息带(4 ≤ r ≤ 152 4 \leq r \leq 152 4 ≤ r ≤ 1 5 2 :光瞳自相关重叠区在此范围内既足够大(统计稳定)又充分展现相位差(像差调制显著),是 M 4 M_4 M 4 唯一有效区域 。本系统统计占比约 85.1% 。
超截止区(r > 152 r > 152 r > 1 5 2 :OTF 的能量在此区域已衰减至可忽略(数值实现中的有效截止)。理论严格截止为 163 px(见式 (1)),但实际仿真中因离散采样与 resize 插值模糊,152 px 以外已基本没有光学信号,仅剩数值噪声与相机噪声。本系统统计占比约 14.7% 。
工程实现 :m4_loss 引入环形频率掩膜 (内径 4 px,外径 152 px),可屏蔽 DC 盲区和超截止噪声区。否则模型将约 42% 的梯度浪费在拟合无物理意义的噪声上,这是 M4 Loss 收敛效率受限的重要原因之一。
1.12. N p N_p N p 1.12.1. resize 因子的作用,是补偿光瞳采样数 N p N_p N p N fft N_{\text{fft}} N fft
当 resize 因子等于 1 时,说明 N p N_p N p N fft N_{\text{fft}} N fft 不需要任何插值补偿 。
当 resize 因子不等于 1 时,说明 N p N_p N p N fft N_{\text{fft}} N fft
1.12.2. 在基于 FFT 的光学仿真中,光瞳平面用 N p × N p N_p \times N_p N p × N p N fft × N fft N_{\text{fft}} \times N_{\text{fft}} N fft × N fft
Δ t sim = λ z N p D N fft \Delta t_{\text{sim}} = \frac{\lambda z N_p}{D \, N_{\text{fft}}}
Δ t sim = D N fft λ z N p
其中:
λ \lambda λ z z z D D D N p N_p N p N fft N_{\text{fft}} N fft
这个公式的物理含义是:光瞳网格间隔为 D / N p D/N_p D / N p λ z \lambda z λ z
1.12.3. 真实 CCD 的像素间距为 Δ t CCD \Delta t_{\text{CCD}} Δ t CCD
α = Δ t sim Δ t CCD = λ z N p D N fft Δ t CCD \alpha = \frac{\Delta t_{\text{sim}}}{\Delta t_{\text{CCD}}} = \frac{\lambda z N_p}{D \, N_{\text{fft}} \, \Delta t_{\text{CCD}}}
α = Δ t CCD Δ t sim = D N fft Δ t CCD λ z N p
1.12.4. 当 α = 1 \alpha = 1 α = 1
N p N fft = D Δ t CCD λ z \frac{N_p}{N_{\text{fft}}} = \frac{D \, \Delta t_{\text{CCD}}}{\lambda z}
N fft N p = λ z D Δ t CCD
这意味着:
仿真 PSF 的像素间距 精确等于 CCD 像素间距;
仿真输出的 N fft × N fft N_{\text{fft}} \times N_{\text{fft}} N fft × N fft N psf × N psf N_{\text{psf}} \times N_{\text{psf}} N psf × N psf
不需要任何 resize 插值 。
因此,resize=1 是 N p N_p N p N fft N_{\text{fft}} N fft :N p N_p N p
1.12.5. 当 N p N_p N p N fft N_{\text{fft}} N fft α ≠ 1 \alpha \neq 1 α = 1
1.12.5.1. N p N_p N p α < 1 \alpha < 1 α < 1 Δ t sim < Δ t CCD \Delta t_{\text{sim}} < \Delta t_{\text{CCD}}
Δ t sim < Δ t CCD
仿真 PSF 的每个像素代表的真实尺寸比 CCD 像素小。为了与真实 CCD 图像比较,需要把仿真 PSF 放大 (upsample)。这就是 resize 的补偿作用。
1.12.5.2. N p N_p N p α > 1 \alpha > 1 α > 1 Δ t sim > Δ t CCD \Delta t_{\text{sim}} > \Delta t_{\text{CCD}}
Δ t sim > Δ t CCD
仿真 PSF 的每个像素代表的真实尺寸比 CCD 像素大。为了与真实 CCD 图像比较,需要把仿真 PSF 缩小 (downsample)。
1.12.5.3.
resize 因子
含义
N p N_p N p 需要的补偿
α = 1 \alpha = 1 α = 1 仿真像素尺度 = CCD 像素尺度
合适
无需补偿
α < 1 \alpha < 1 α < 1 仿真像素尺度 < CCD 像素尺度
N p N_p N p N fft N_{\text{fft}} N fft 放大(upsample)
α > 1 \alpha > 1 α > 1 仿真像素尺度 > CCD 像素尺度
N p N_p N p N fft N_{\text{fft}} N fft 缩小(downsample)
因此,resize 的本质就是对 N p N_p N p 。
1.12.6. N p N_p N p 虽然 resize 可以补偿 α ≠ 1 \alpha \neq 1 α = 1 不能补偿光瞳内的欠采样 。
当 N p N_p N p
光瞳内的连续波前被粗糙网格采样,高频成分丢失;
这些高频信息在采样时已经损失,后续的 resize 插值无法恢复;
仿真 PSF 会比真实 PSF 更光滑、缺少细节;
即使通过 resize 把尺度放大到 CCD 尺寸,丢失的高频信息也找不回来。
因此,N p N_p N p α = 1 \alpha = 1 α = 1
N p ≥ 2 ⋅ f max pupil N_p \geq 2 \cdot f_{\max}^{\text{pupil}}
N p ≥ 2 ⋅ f max pupil
其中 f max pupil f_{\max}^{\text{pupil}} f max pupil 模型中需要表示的最高光瞳空间频率 (cycles/pupil)。
重要说明 :f max pupil f_{\max}^{\text{pupil}} f max pupil 不是真实光路系统的物理限制 。真实连续光瞳波前 ϕ ( x ) \phi(x) ϕ ( x ) f max pupil f_{\max}^{\text{pupil}} f max pupil 建模假设 决定:
如果采用低阶 Zernike 展开,f max pupil f_{\max}^{\text{pupil}} f max pupil
如果采用 M4 的 HF phase 模型并假设最高 45 cycles/pupil,则 f max pupil = 45 f_{\max}^{\text{pupil}} = 45 f max pupil = 4 5
如果我们相信真实波前包含更高频率的成分,就需要相应提高 f max pupil f_{\max}^{\text{pupil}} f max pupil N p N_p N p
因此,N p ≥ 2 f max pupil N_p \geq 2 f_{\max}^{\text{pupil}} N p ≥ 2 f max pupil 我们的模型想表示多精细的光瞳波前? 答案决定了采样网格的密度。
1.12.7. N fft N_{\text{fft}} N fft N p N_p N p 1.12.7.1. N fft N_{\text{fft}} N fft 真实 PSF 的频率上限由光学系统物理参数决定:
f c = D λ z f_c = \frac{D}{\lambda z}
f c = λ z D
转换为 CCD 像素坐标下的截止半径:
r c = f c Δ f CCD = D N psf Δ t CCD λ z r_c = \frac{f_c}{\Delta f_{\text{CCD}}} = \frac{D \, N_{\text{psf}} \, \Delta t_{\text{CCD}}}{\lambda z}
r c = Δ f CCD f c = λ z D N psf Δ t CCD
为了让仿真 FFT 覆盖真实 PSF 频率,需要
N fft ≥ 2 r c N_{\text{fft}} \geq 2 \, r_c
N fft ≥ 2 r c
同时 N fft ≥ N psf N_{\text{fft}} \geq N_{\text{psf}} N fft ≥ N psf
1.12.7.2. N p N_p N p 令 α = 1 \alpha = 1 α = 1
N p = N fft ⋅ D Δ t CCD λ z = N fft ⋅ k N_p = N_{\text{fft}} \cdot \frac{D \, \Delta t_{\text{CCD}}}{\lambda z} = N_{\text{fft}} \cdot k
N p = N fft ⋅ λ z D Δ t CCD = N fft ⋅ k
其中
k = D Δ t CCD λ z k = \frac{D \, \Delta t_{\text{CCD}}}{\lambda z}
k = λ z D Δ t CCD
此时 N p N_p N p N fft N_{\text{fft}} N fft
1.12.7.2.1. k k k k k k
1. 光瞳采样点数与 FFT 网格尺寸之比
由 resize=1 条件直接得到:
N p N fft = k \frac{N_p}{N_{\text{fft}}} = k
N fft N p = k
即 FFT 网格中有比例为 k k k
2. CCD 像素间距与衍射极限特征尺度之比
由于 λ z / D \lambda z / D λ z / D 1.22 1.22 1 . 2 2 2.44 2.44 2 . 4 4
k = Δ t CCD λ z / D k = \frac{\Delta t_{\text{CCD}}}{\lambda z / D}
k = λ z / D Δ t CCD
即 k k k k k k
为便于直观理解:
艾里斑第一暗环半径 r Airy = 1.22 λ z / D r_{\text{Airy}} = 1.22 \, \lambda z / D r Airy = 1 . 2 2 λ z / D
艾里斑第一暗环直径 d Airy = 2.44 λ z / D d_{\text{Airy}} = 2.44 \, \lambda z / D d Airy = 2 . 4 4 λ z / D
当 k = 0.5 k = 0.5 k = 0 . 5 λ z / D = 2 Δ t CCD \lambda z / D = 2 \, \Delta t_{\text{CCD}} λ z / D = 2 Δ t CCD 2.44 × 2 = 4.88 2.44 \times 2 = 4.88 2 . 4 4 × 2 = 4 . 8 8
3. 光学截止频率与 CCD 奈奎斯特频率之比
光学截止频率为 f c = D / ( λ z ) f_c = D/(\lambda z) f c = D / ( λ z ) f max CCD = 1 / ( 2 Δ t CCD ) f_{\max}^{\text{CCD}} = 1/(2\Delta t_{\text{CCD}}) f max CCD = 1 / ( 2 Δ t CCD )
f c f max CCD = D / ( λ z ) 1 / ( 2 Δ t CCD ) = 2 ⋅ D Δ t CCD λ z = 2 k \frac{f_c}{f_{\max}^{\text{CCD}}} = \frac{D/(\lambda z)}{1/(2\Delta t_{\text{CCD}})} = 2 \cdot \frac{D \Delta t_{\text{CCD}}}{\lambda z} = 2k
f max CCD f c = 1 / ( 2 Δ t CCD ) D / ( λ z ) = 2 ⋅ λ z D Δ t CCD = 2 k
因此
k = 1 2 ⋅ f c f max CCD k = \frac{1}{2} \cdot \frac{f_c}{f_{\max}^{\text{CCD}}}
k = 2 1 ⋅ f max CCD f c
这说明 k k k
k = 0.5 k = 0.5 k = 0 . 5 f c = f max CCD f_c = f_{\max}^{\text{CCD}} f c = f max CCD k < 0.5 k < 0.5 k < 0 . 5 f c < f max CCD f_c < f_{\max}^{\text{CCD}} f c < f max CCD k > 0.5 k > 0.5 k > 0 . 5 f c > f max CCD f_c > f_{\max}^{\text{CCD}} f c > f max CCD
4. 判断系统是光学限制还是 CCD 限制的关键判据
综合以上三点,k k k k ≤ 0.5 k \leq 0.5 k ≤ 0 . 5 N psf ≫ 1 / k N_{\text{psf}} \gg 1/k N psf ≫ 1 / k
1.12.7.3. N p ≥ 2 ⋅ f max pupil N_p \geq 2 \cdot f_{\max}^{\text{pupil}}
N p ≥ 2 ⋅ f max pupil
若不满足,需要增大 N fft N_{\text{fft}} N fft N p N_p N p
1.12.8.
D = 60 mm D = 60 \ \text{mm} D = 6 0 mm λ = 530 nm \lambda = 530 \ \text{nm} λ = 5 3 0 nm z = 1248.16 mm z = 1248.16 \ \text{mm} z = 1 2 4 8 . 1 6 mm Δ t CCD = 4.5 μ m \Delta t_{\text{CCD}} = 4.5 \ \mu\text{m} Δ t CCD = 4 . 5 μ m N psf = 400 N_{\text{psf}} = 400 N psf = 4 0 0
1.12.8.1. N fft N_{\text{fft}} N fft f c = D λ z ≈ 9.07 × 1 0 4 cycles/m f_c = \frac{D}{\lambda z} \approx 9.07 \times 10^4 \ \text{cycles/m}
f c = λ z D ≈ 9 . 0 7 × 1 0 4 cycles/m
r c = D N psf Δ t CCD λ z = 60 × 1 0 − 3 × 400 × 4.5 × 1 0 − 6 530 × 1 0 − 9 × 1248.16 × 1 0 − 3 ≈ 163 px r_c = \frac{D \, N_{\text{psf}} \, \Delta t_{\text{CCD}}}{\lambda z} = \frac{60 \times 10^{-3} \times 400 \times 4.5 \times 10^{-6}}{530 \times 10^{-9} \times 1248.16 \times 10^{-3}} \approx 163 \ \text{px}
r c = λ z D N psf Δ t CCD = 5 3 0 × 1 0 − 9 × 1 2 4 8 . 1 6 × 1 0 − 3 6 0 × 1 0 − 3 × 4 0 0 × 4 . 5 × 1 0 − 6 ≈ 1 6 3 px
N fft ≥ max ( 2 r c , N psf ) = max ( 326 , 400 ) = 400 N_{\text{fft}} \geq \max(2 r_c, \ N_{\text{psf}}) = \max(326, \ 400) = 400
N fft ≥ max ( 2 r c , N psf ) = max ( 3 2 6 , 4 0 0 ) = 4 0 0
取 2 的幂次:
N fft = 512 N_{\text{fft}} = 512
N fft = 5 1 2
1.12.8.2. N p N_p N p k = D Δ t CCD λ z = 60 × 1 0 − 3 × 4.5 × 1 0 − 6 530 × 1 0 − 9 × 1248.16 × 1 0 − 3 ≈ 0.408 k = \frac{D \, \Delta t_{\text{CCD}}}{\lambda z} = \frac{60 \times 10^{-3} \times 4.5 \times 10^{-6}}{530 \times 10^{-9} \times 1248.16 \times 10^{-3}} \approx 0.408
k = λ z D Δ t CCD = 5 3 0 × 1 0 − 9 × 1 2 4 8 . 1 6 × 1 0 − 3 6 0 × 1 0 − 3 × 4 . 5 × 1 0 − 6 ≈ 0 . 4 0 8
N p = N fft ⋅ k = 512 × 0.408 ≈ 209 N_p = N_{\text{fft}} \cdot k = 512 \times 0.408 \approx 209
N p = N fft ⋅ k = 5 1 2 × 0 . 4 0 8 ≈ 2 0 9
此时 resize 因子
α = λ z N p D N fft Δ t CCD = N p N fft ⋅ k = 1 \alpha = \frac{\lambda z N_p}{D \, N_{\text{fft}} \, \Delta t_{\text{CCD}}} = \frac{N_p}{N_{\text{fft}} \cdot k} = 1
α = D N fft Δ t CCD λ z N p = N fft ⋅ k N p = 1
1.12.8.3.
63 个 Zernike 模式最高到 n = 10 n=10 n = 1 0 N p ≥ 20 N_p \geq 20 N p ≥ 2 0
HF phase 最高 45 cycles/pupil,要求 N p ≥ 90 N_p \geq 90 N p ≥ 9 0
当前 N p = 209 N_p = 209 N p = 2 0 9
1.12.9.
resize 因子的作用就是补偿 N p N_p N p N fft N_{\text{fft}} N fft ;resize=1 说明 N p N_p N p N fft N_{\text{fft}} N fft ,仿真 PSF 的像素尺度与 CCD 天然一致,无需插值;N p N_p N p 当前系统的 N p = 209 N_p = 209 N p = 2 0 9 N fft = 512 N_{\text{fft}} = 512 N fft = 5 1 2
1.12.10. N p N_p N p 一个自然的问题是:既然真实光学系统中也存在光瞳到焦平面的傅里叶变换,那么光瞳采样数 N p N_p N p
1.12.10.1. 在真实光学系统中:
光瞳是连续 的,直径为 D D D
CCD 是离散 的,像素间距为 Δ t CCD \Delta t_{\text{CCD}} Δ t CCD
聚焦透镜实现光瞳平面到焦平面的傅里叶变换。
1.12.10.1.1. 需要区分两类频率:
焦平面空间频率 f f f 光瞳面波前空间频率 u u u ϕ ( x ) \phi(x) ϕ ( x )
二者不是同一个概念。
1.12.10.1.2. 根据夫琅禾费衍射的对合性(正文第 3 节详细推导),存在两组对应关系:
区分要点在于:光瞳频率 对应焦平面位置 ,焦平面频率 对应光瞳位置 。二者通过傅里叶变换互相映射到对方的位置空间,而不是频率空间直接对应。
1.12.10.1.3. 光学截止频率 f c = D / ( λ z ) f_c = D/(\lambda z) f c = D / ( λ z ) 焦平面频率 ,它对应光瞳上的位置:
x c = − f c ⋅ λ z = − D x_c = -f_c \cdot \lambda z = -D
x c = − f c ⋅ λ z = − D
即光瞳边缘(负号表示方向)。
CCD 能分辨的最高焦平面频率 为
f max CCD = 1 2 Δ t CCD f_{\max}^{\text{CCD}} = \frac{1}{2 \Delta t_{\text{CCD}}}
f max CCD = 2 Δ t CCD 1
它对应光瞳上的位置:
x max CCD = f max CCD ⋅ λ z = λ z 2 Δ t CCD x_{\max}^{\text{CCD}} = f_{\max}^{\text{CCD}} \cdot \lambda z = \frac{\lambda z}{2 \Delta t_{\text{CCD}}}
x max CCD = f max CCD ⋅ λ z = 2 Δ t CCD λ z
这是光瞳上的一个位置坐标 ,不是光瞳波前的空间频率。
1.12.10.1.4. 二者之间没有直接的数值对应关系 :
焦平面频率上限由光学系统参数决定:f c = D / ( λ z ) f_c = D/(\lambda z) f c = D / ( λ z )
光瞳波前频率上限由真实像差决定,可能远高于或低于焦平面频率"对应"的光瞳位置尺度;
光瞳波前中的高频成分会使 PSF 能量在焦平面内重新分布,但不改变焦平面频率上限 f c f_c f c
1.12.10.1.5. 需要进一步区分两个概念:
光学截止频率 f c = D / ( λ z ) f_c = D/(\lambda z) f c = D / ( λ z ) CCD 奈奎斯特频率 f max CCD = 1 / ( 2 Δ t CCD ) f_{\max}^{\text{CCD}} = 1/(2\Delta t_{\text{CCD}}) f max CCD = 1 / ( 2 Δ t CCD )
实际系统的最高可探测频率是两者的最小值:
f system,max = min ( f c , f max CCD ) f_{\text{system,max}} = \min\left(f_c, \ f_{\max}^{\text{CCD}}\right)
f system,max = min ( f c , f max CCD )
哪个更小,哪个就是系统的实际瓶颈。
在当前系统中:
f c ≈ 9.07 × 1 0 4 cycles/m f_c \approx 9.07 \times 10^4 \ \text{cycles/m} f c ≈ 9 . 0 7 × 1 0 4 cycles/m f max CCD = 1 / ( 2 × 4.5 × 1 0 − 6 ) ≈ 1.11 × 1 0 5 cycles/m f_{\max}^{\text{CCD}} = 1/(2 \times 4.5 \times 10^{-6}) \approx 1.11 \times 10^5 \ \text{cycles/m} f max CCD = 1 / ( 2 × 4 . 5 × 1 0 − 6 ) ≈ 1 . 1 1 × 1 0 5 cycles/m
因此
f system,max = f c ≈ 9.07 × 1 0 4 cycles/m f_{\text{system,max}} = f_c \approx 9.07 \times 10^4 \ \text{cycles/m}
f system,max = f c ≈ 9 . 0 7 × 1 0 4 cycles/m
当前系统是光学系统限制 ,而不是 CCD 限制。这也说明 CCD 像素间距 4.5 μ m 4.5 \ \mu\text{m} 4 . 5 μ m
1.12.10.1.6. 由于上述原因,不能从 CCD 观测到的焦平面频率上限反推光瞳波前的最高频率 。光瞳波前中的高频成分会改变 PSF 内部能量分布,但不改变焦平面频率上限 f system,max f_{\text{system,max}} f system,max N p N_p N p
1.12.10.2. 在数值仿真中,我们用一个离散网格 N p × N p N_p \times N_p N p × N p
Δ u = D N p \Delta u = \frac{D}{N_p}
Δ u = N p D
经过 FFT 后,焦平面的采样间隔为
Δ t sim = λ z N fft Δ u = λ z N p D N fft \Delta t_{\text{sim}} = \frac{\lambda z}{N_{\text{fft}} \Delta u} = \frac{\lambda z N_p}{D N_{\text{fft}}}
Δ t sim = N fft Δ u λ z = D N fft λ z N p
为了让仿真中的焦平面离散采样与真实 CCD 的离散采样匹配,需要
Δ t sim = Δ t CCD \Delta t_{\text{sim}} = \Delta t_{\text{CCD}}
Δ t sim = Δ t CCD
这就导出
N p N fft = D Δ t CCD λ z = k \frac{N_p}{N_{\text{fft}}} = \frac{D \Delta t_{\text{CCD}}}{\lambda z} = k
N fft N p = λ z D Δ t CCD = k
因此,对于给定的 N fft N_{\text{fft}} N fft N p N_p N p
N p = N fft ⋅ k N_p = N_{\text{fft}} \cdot k
N p = N fft ⋅ k
1.12.10.3. N p N_p N p N p N_p N p
仿真中的离散化应该重现真实光路中光瞳与焦平面的尺度对应关系。
这个要求具体化为:
N fft N_{\text{fft}} N fft N fft ≥ 2 r c N_{\text{fft}} \geq 2 r_c N fft ≥ 2 r c N p N_p N p N fft N_{\text{fft}} N fft k k k N p N_p N p
在当前系统中:
N fft = 512 N_{\text{fft}} = 512 N fft = 5 1 2 k ≈ 0.408 k \approx 0.408 k ≈ 0 . 4 0 8 理想 N p = 512 × 0.408 ≈ 209 N_p = 512 \times 0.408 \approx 209 N p = 5 1 2 × 0 . 4 0 8 ≈ 2 0 9
这个 N p = 209 N_p = 209 N p = 2 0 9
1.12.10.4.
真实光瞳没有离散的 N p N_p N p
但仿真中引入的 N p N_p N p N p = N fft ⋅ k N_p = N_{\text{fft}} \cdot k N p = N fft ⋅ k
这个理想值使仿真 PSF 的像素尺度与 CCD 像素尺度一致,即 resize=1;
它本质上是在离散数值计算中重现真实光学系统的光瞳-焦平面尺度对应关系;
此外,N p N_p N p
1.12.11. 在上一节的完整流程中,我们列出了三个约束:
N fft ≥ 2 r c N_{\text{fft}} \geq 2 r_c N fft ≥ 2 r c N p = N fft ⋅ k N_p = N_{\text{fft}} \cdot k N p = N fft ⋅ k N p ≥ 2 f max pupil N_p \geq 2 f_{\max}^{\text{pupil}} N p ≥ 2 f max pupil
其中第三个约束看起来和前两个独立,因此需要讨论:在当前逻辑框架下,它是否多余?
1.12.11.1. 将约束 2 代入约束 3:
N p = N fft ⋅ k ≥ 2 f max pupil N_p = N_{\text{fft}} \cdot k \geq 2 f_{\max}^{\text{pupil}}
N p = N fft ⋅ k ≥ 2 f max pupil
得到
N fft ≥ 2 f max pupil k N_{\text{fft}} \geq \frac{2 f_{\max}^{\text{pupil}}}{k}
N fft ≥ k 2 f max pupil
而约束 1 要求
N fft ≥ 2 r c = 2 N psf k N_{\text{fft}} \geq 2 r_c = 2 N_{\text{psf}} k
N fft ≥ 2 r c = 2 N psf k
因此,如果
2 N psf k ≥ 2 f max pupil k 2 N_{\text{psf}} k \geq \frac{2 f_{\max}^{\text{pupil}}}{k}
2 N psf k ≥ k 2 f max pupil
即
f max pupil ≤ N psf k 2 f_{\max}^{\text{pupil}} \leq N_{\text{psf}} k^2
f max pupil ≤ N psf k 2
那么约束 1 已经比约束 3 更严格,约束 3 自动满足。
1.12.11.2. 当前系统:
N psf = 400 N_{\text{psf}} = 400 N psf = 4 0 0 k = 0.408 k = 0.408 k = 0 . 4 0 8 f max pupil = 45 f_{\max}^{\text{pupil}} = 45 f max pupil = 4 5
计算:
N psf k 2 = 400 × 0.40 8 2 ≈ 66.6 N_{\text{psf}} k^2 = 400 \times 0.408^2 \approx 66.6
N psf k 2 = 4 0 0 × 0 . 4 0 8 2 ≈ 6 6 . 6
因为 45 ≤ 66.6 45 \leq 66.6 4 5 ≤ 6 6 . 6 约束 3 确实是多余的 。
1.12.11.3. 虽然数学上可以被隐含,但约束 3 在物理上具有独立意义,原因如下:
第一,f max pupil f_{\max}^{\text{pupil}} f max pupil
CCD 只能观测到焦平面频率 f ≤ f c = D / ( λ z ) f \leq f_c = D/(\lambda z) f ≤ f c = D / ( λ z ) f c f_c f c
一个只含低阶 Zernike 像差的平滑波前;
一个包含子孔径内高频扰动的复杂波前。
两种情况在 CCD 上的频率上限都是 f c f_c f c 不能从 CCD 观测频率上限反推光瞳波前的最高频率 。
第二,约束 3 来自对真实波前的建模假设。
f max pupil f_{\max}^{\text{pupil}} f max pupil
如果模型只包含 63 个 Zernike 模式,则 f max pupil = 10 f_{\max}^{\text{pupil}} = 10 f max pupil = 1 0 N p ≥ 20 N_p \geq 20 N p ≥ 2 0
如果模型还包含 HF phase(45 cycles/pupil),则 f max pupil = 45 f_{\max}^{\text{pupil}} = 45 f max pupil = 4 5 N p ≥ 90 N_p \geq 90 N p ≥ 9 0
如果假设真实波前中有更高频成分,则需要更大的 N p N_p N p
第三,当模型假设改变时,约束 3 会独立起作用。
假设 HF phase 频率上限提高到 100 cycles/pupil:
f max pupil = 100 > N psf k 2 ≈ 66.6 f_{\max}^{\text{pupil}} = 100 > N_{\text{psf}} k^2 \approx 66.6
f max pupil = 1 0 0 > N psf k 2 ≈ 6 6 . 6
此时约束 1 给出 N fft ≥ 326 N_{\text{fft}} \geq 326 N fft ≥ 3 2 6 N p = 326 × 0.408 ≈ 133 N_p = 326 \times 0.408 \approx 133 N p = 3 2 6 × 0 . 4 0 8 ≈ 1 3 3 N p ≥ 200 N_p \geq 200 N p ≥ 2 0 0 N fft N_{\text{fft}} N fft
N fft ≥ 2 × 100 0.408 ≈ 490 N_{\text{fft}} \geq \frac{2 \times 100}{0.408} \approx 490
N fft ≥ 0 . 4 0 8 2 × 1 0 0 ≈ 4 9 0
取 N fft = 512 N_{\text{fft}} = 512 N fft = 5 1 2 N p = 512 × 0.408 ≈ 209 N_p = 512 \times 0.408 \approx 209 N p = 5 1 2 × 0 . 4 0 8 ≈ 2 0 9 N p ≥ 200 N_p \geq 200 N p ≥ 2 0 0 N fft = 512 N_{\text{fft}} = 512 N fft = 5 1 2 f max pupil f_{\max}^{\text{pupil}} f max pupil N fft ≥ 735 N_{\text{fft}} \geq 735 N fft ≥ 7 3 5 N p ≈ 418 N_p \approx 418 N p ≈ 4 1 8
1.12.11.4.
在当前系统参数和 HF phase=45 cycles/pupil 的假设下,约束 1+2 已经隐含了约束 3,此时约束 3 在数学上是多余的;
但约束 3 在物理上不是多余的,它体现了我们对真实波前频率内容的建模假设;
如果模型假设的波前频率更高,约束 3 会独立起作用,必须显式考虑。
因此,完整的严谨表述是:
N fft ≥ max ( 2 r c , 2 f max pupil k ) N_{\text{fft}} \geq \max\left(2 r_c, \ \frac{2 f_{\max}^{\text{pupil}}}{k}\right)
N fft ≥ max ( 2 r c , k 2 f max pupil )
N p = N fft ⋅ k N_p = N_{\text{fft}} \cdot k
N p = N fft ⋅ k
在当前系统中,由于 2 r c > 2 f max pupil / k 2 r_c > 2 f_{\max}^{\text{pupil}}/k 2 r c > 2 f max pupil / k N fft = 512 N_{\text{fft}} = 512 N fft = 5 1 2
1.12.12. 前文主要从仿真角度讨论了 N fft N_{\text{fft}} N fft N p N_p N p N psf N_{\text{psf}} N psf
1.12.12.1. 在真实实验中,CCD 记录 PSF 时也受到两条独立约束:
约束 A:CCD 像素间距必须满足采样定理
焦平面光强的最高空间频率为 f c = D / ( λ z ) f_c = D/(\lambda z) f c = D / ( λ z )
Δ t CCD ≤ 1 2 f c = λ z 2 D \Delta t_{\text{CCD}} \leq \frac{1}{2 f_c} = \frac{\lambda z}{2D}
Δ t CCD ≤ 2 f c 1 = 2 D λ z
代入 k = D Δ t CCD / ( λ z ) k = D \Delta t_{\text{CCD}} / (\lambda z) k = D Δ t CCD / ( λ z )
k ≤ 0.5 k \leq 0.5
k ≤ 0 . 5
如果违反,真实 CCD 本身就会欠采样,无论后续窗口多大、仿真多精细,都无法恢复被混叠掉的高频信息。
约束 B:PSF 窗口必须足够大,不能截断 PSF 能量
真实 PSF 在焦平面上能量主要集中在艾里斑主瓣和前几级环内,但理论上是无限延展的。CCD 窗口尺寸 N psf × N psf N_{\text{psf}} \times N_{\text{psf}} N psf × N psf
N psf Δ t CCD ≫ λ z D N_{\text{psf}} \Delta t_{\text{CCD}} \gg \frac{\lambda z}{D}
N psf Δ t CCD ≫ D λ z
即
N psf ≫ 1 k N_{\text{psf}} \gg \frac{1}{k}
N psf ≫ k 1
1.12.12.2. N fft ≥ 2 r c N_{\text{fft}} \geq 2 r_c N fft ≥ 2 r c 回顾仿真中的焦平面频率覆盖条件:
N fft ≥ 2 r c = 2 N psf k N_{\text{fft}} \geq 2 r_c = 2 N_{\text{psf}} k
N fft ≥ 2 r c = 2 N psf k
如果我们要求仿真网格至少覆盖真实 PSF 的全部频率内容,并且希望仿真参数与真实采集参数直接对应,那么最自然的取法是让仿真窗口等于真实 CCD 窗口,即 N fft = N psf N_{\text{fft}} = N_{\text{psf}} N fft = N psf
N psf ≥ 2 N psf k ⟺ k ≤ 0.5 N_{\text{psf}} \geq 2 N_{\text{psf}} k \iff k \leq 0.5
N psf ≥ 2 N psf k ⟺ k ≤ 0 . 5
这说明:仿真条件 N fft ≥ 2 r c N_{\text{fft}} \geq 2 r_c N fft ≥ 2 r c 当 CCD 满足采样定理时,N psf ≥ 2 r c N_{\text{psf}} \geq 2 r_c N psf ≥ 2 r c
1.12.12.3. 代入当前系统参数:
k = 0.408 ≤ 0.5 k = 0.408 \leq 0.5 k = 0 . 4 0 8 ≤ 0 . 5 1 / k ≈ 2.45 1/k \approx 2.45 1 / k ≈ 2 . 4 5 N psf = 400 ≫ 2.45 N_{\text{psf}} = 400 \gg 2.45 N psf = 4 0 0 ≫ 2 . 4 5 因此真实采集保留了光学系统的全部频率信息,没有因为采样或开窗而损失分辨率。
1.12.12.4. auto_sim_params 中通过
1 start_fft = max (min_fft or 0 , out_size)
保证 N fft ≥ N psf N_{\text{fft}} \geq N_{\text{psf}} N fft ≥ N psf k ≤ 0.5 k \leq 0.5 k ≤ 0 . 5 N fft ≥ 2 r c N_{\text{fft}} \geq 2 r_c N fft ≥ 2 r c
但如果将来修改系统参数,使得 k > 0.5 k > 0.5 k > 0 . 5 N fft ≥ N psf N_{\text{fft}} \geq N_{\text{psf}} N fft ≥ N psf f c f_c f c
1.12.12.4.1. 有人可能认为:只要让 N psf N_{\text{psf}} N psf N fft ≥ N psf N_{\text{fft}} \geq N_{\text{psf}} N fft ≥ N psf N fft ≥ 2 r c N_{\text{fft}} \geq 2 r_c N fft ≥ 2 r c
2 r c = 2 N psf k 2 r_c = 2 N_{\text{psf}} k
2 r c = 2 N psf k
当 k > 0.5 k > 0.5 k > 0 . 5 2 r c 2 r_c 2 r c N psf N_{\text{psf}} N psf N psf N_{\text{psf}} N psf 增大窗口无法解决 CCD 欠采样问题。 欠采样是硬件像素间距决定的,不是靠软件开窗能弥补的。
1.12.12.4.2. 需要特别强调的是,CCD 像素间距 Δ t CCD \Delta t_{\text{CCD}} Δ t CCD 硬件参数 ,仿真代码不能改变它。仿真的职责不是"修正"硬件,而是诚实地反映硬件的能力 。因此代码应该检查仿真假设是否与硬件能力一致。
更严谨的代码应该把问题拆成两层:
第一层:采样定理检查(与硬件对齐)
1 2 3 4 5 6 if k > 0.5 : raise ValueError( f"CCD pitch {ccd_pitch_m*1e6 :.2 f} um violates Nyquist " f"for lambda={wavelength_m*1e9 :.0 f} nm, z={focal_length_m*1e3 :.2 f} mm, " f"D={pupil_diameter_m*1e3 :.2 f} mm. k={k:.3 f} > 0.5." )
这一步不是限制代码功能,而是告诉用户:真实数据已经不可信了,仿真再精确也没用。 因为 CCD 像素间距不可改变,k > 0.5 k > 0.5 k > 0 . 5 f c = D / ( λ z ) f_c = D/(\lambda z) f c = D / ( λ z ) f max CCD = 1 / ( 2 Δ t CCD ) f_{\max}^{\text{CCD}} = 1/(2\Delta t_{\text{CCD}}) f max CCD = 1 / ( 2 Δ t CCD ) f c f_c f c
如果不想直接报错,也可以显式把仿真和损失函数中的有效截止频率降级为 f max CCD f_{\max}^{\text{CCD}} f max CCD f c f_c f c f c f_c f c N fft N_{\text{fft}} N fft
作为最低限度的安全机制,至少应该给出警告:
1 2 3 4 5 6 if k > 0.5 : warnings.warn( f"CCD is undersampled (k={k:.3 f} >0.5). " f"Effective cutoff is f_CCD={1 /(2 *ccd_pitch_m):.3 e} Hz/m, " f"not f_c={pupil_diameter_m/(wavelength_m*focal_length_m):.3 e} Hz/m." )
第二层:PSF 能量截断检查(可以用开窗下限解决)
开窗下限解决的是另一个独立问题:PSF 能量不要被矩形窗截断。艾里斑主瓣直径约为
d Airy ≈ 2.44 λ z D d_{\text{Airy}} \approx 2.44 \frac{\lambda z}{D}
d Airy ≈ 2 . 4 4 D λ z
工程上通常要求窗口覆盖 5 ∼ 10 5 \sim 10 5 ∼ 1 0
N psf ≥ 5 ∼ 10 k N_{\text{psf}} \geq \frac{5 \sim 10}{k}
N psf ≥ k 5 ∼ 1 0
代码中可以这样检查:
1 2 3 4 5 N_psf_min = int (np.ceil(10 / k)) if out_size < N_psf_min: warnings.warn( f"PSF window {out_size} may truncate PSF energy; suggest >= {N_psf_min} " )
1.12.12.4.3. 在当前系统中:
k = 0.408 ≤ 0.5 k = 0.408 \leq 0.5 k = 0 . 4 0 8 ≤ 0 . 5 10 / k ≈ 24.5 10/k \approx 24.5 1 0 / k ≈ 2 4 . 5 N psf = 400 ≫ 24.5 N_{\text{psf}} = 400 \gg 24.5 N psf = 4 0 0 ≫ 2 4 . 5
因此当前代码给出的 N fft = 512 N_{\text{fft}} = 512 N fft = 5 1 2 N p = 209 N_p = 209 N p = 2 0 9
2. 2.1. 本报告针对测试集中 Sample 70 样本,对比真实采集 PSF 与不同过曝(软饱和)配置下仿真 PSF 的差异,验证光学参数优化程序对过曝程度的学习效果。
测试样本从测试集中随机抽取,Zernike 系数为真实测量值。仿真过程完全复用训练和测试代码的 Zernike2M4_Model.forward 流程,仅通过临时替换 sat_focus / sat_defocus 参数来改变过曝程度,其余所有物理参数(gain、spatial_scale、blur_kernel、zernike_residual 等)均固定为训练后的最优值。
2.2. 下图展示了 Sample 70 在五种过曝配置下的仿真结果与真实数据的对比:
第 0 行 :真实采集数据(Real)第 1~5 行 :仿真结果,依次为 No Sat → Init Sat → Trained → Strong Sat → Extreme Sat列 :Focus PSF / Defocus PSF / Focus FFT / Defocus FFT / M4
2.3. 2.3.1. 真实数据呈现以下特征:
在焦 PSF(Real Focus) :中心亮斑并非理想衍射极限的尖锐艾里斑,而是一个有一定展宽、边缘略模糊的光斑,暗示采集时存在一定过曝或探测器非线性响应。离焦 PSF(Real Defocus) :呈较大弥散斑,能量分布相对均匀。频域(Real FFT) :在焦频谱中心能量集中但伴有明显旁瓣;离焦频谱因离焦模糊而高频衰减更显著。M4(Real M4) :在焦与离焦的频域功率比值呈现清晰的环状结构,红色(正值)区域偏外,蓝色(负值)区域偏内,这是该像差组合的特征指纹。
2.3.2.
在焦 PSF :仿真为一个极尖锐的小点,与真实采集的"有一定展宽的亮斑"差异明显。频域 :高频分量保留完整,中心亮度过高。M4 :环状结构与 Real M4 在细节上存在偏差,中心区域对比度过强。
结论 :无饱和假设下,仿真过于"理想化",未能复现真实相机采集时的非线性压缩效应。
2.3.3.
空间域 :与 No Sat 几乎无法区分。原因 :该样本在焦 PSF 经 detector gain(训练后 ≈9.28)放大后的实际峰值远低于 1.0,sat=1.0 的阈值并未真正"触碰到"信号,软饱和函数基本处于线性通过区。
结论 :初始值 sat=1.0 对该样本基本无效。
2.3.4.
在焦 PSF :亮斑尺寸与 Real Focus 高度吻合,不再像 No Sat 那样尖锐,而是呈现出与真实数据接近的"轻微弥散+中心平顶"特征。离焦 PSF :与 Real Defocus 几乎一致。频域 :Focus FFT 的中心能量集中度下降,旁瓣结构更接近 Real FFT;Defocus FFT 与真实匹配良好。M4 :环状结构、红蓝区域分布与 Real M4 的相似度显著提升,中心过冲被有效抑制。
结论 :训练后的饱和阈值(sat_focus=0.54)恰好落在该样本实际峰值附近,软饱和对中心峰值的轻微压缩使得仿真形状向真实数据靠拢。程序成功学习到了该样本对应的过曝程度 。
2.3.5.
在焦 PSF :中心亮斑进一步展宽,与 Real 相比开始"过度模糊"。频域 :中心低频能量被进一步压低,高频旁瓣相对抬升。M4 :环状结构开始扭曲,细节丢失。
结论 :饱和过度,能量重分布超出了真实数据的范围。
2.3.6.
在焦 PSF :中心严重展宽,亮斑变成一个较大的"光团",与真实数据差异极大。频域 :中心几乎被"削平",频谱形态发生质变。M4 :图案严重失真,环状结构几乎消失,整体趋向低对比度的"雾化"状态。
结论 :极端过曝下,仿真完全失真,验证了训练将饱和阈值收敛到合理区间(0.5~0.9 量级)的必要性。
2.4.
评价维度
No Sat
Init Sat
Trained Strong Sat
Extreme Sat
在焦 PSF 形状匹配
❌ 过锐
❌ 过锐
✅ 接近真实
⚠️ 偏模糊
❌ 严重失真
频域中心集中度
❌ 过高
❌ 过高
✅ 适中
⚠️ 偏低
❌ 过低
M4 结构保真
⚠️ 有偏差
⚠️ 有偏差
✅ 高度吻合
⚠️ 扭曲
❌ 严重失真
物理合理性
❌ 理想化
❌ 理想化
✅ 符合真实相机
⚠️ 过度
❌ 不真实
程序成功学习到了过曝程度 。sat_focus 从初始值 1.0 收敛到 0.539,不是无意义的参数漂移,而是对该样本(及训练集整体)真实过曝特性的有效拟合。
Trained 配置显著优于 No Sat 。在不引入饱和时,仿真 PSF 过于理想化(尖锐峰值);引入训练后的软饱和后,中心峰值被适度压缩,能量向周围重新分配,最终形状与真实采集数据高度一致。
过曝的引入是"恰到好处"的 。训练没有让饱和阈值掉落到 Strong/Extreme 区间(那样会过度失真),而是收敛到了一个微妙的平衡点——刚好能对峰值产生可感知的压缩,但又不破坏旁瓣结构。
频域和 M4 对过曝的敏感性高于空间域 。即使空间域 PSF 在 min-max 归一化后肉眼差异有限,频域的中心能量分布和 M4 的环状结构已经清晰展示了 Trained 与 No Sat 的区别,且 Trained 明显更接近 Real。
2.5.
无饱和仿真假设探测器是完美线性的,这在真实相机中不成立(CCD/CMOS 存在满阱容量限制)。
真实采集数据本身已经包含了相机的非线性响应(过曝)。
程序通过可学习的 sat_focus / sat_defocus,将"探测器的非线性过曝"这一物理效应显式地建模进了仿真流程。
结果是:Trained 仿真不仅复现了光学传播的物理过程,还复现了探测器的非线性响应 ,因此比"纯粹光学仿真 + 理想探测器"的 No Sat 版本更逼真。
3. 3.1. 本文分析光学仿真链路中**探测器增益(gain)与 饱和阈值(saturation)**的数学关系。
核心问题:
全局 gain + 全局 sat,在 min-max 归一化链路中是否冗余?
如果冗余,为什么还要两者都学?
hard clamp 的梯度问题在哪里?soft clamp 如何解决?
3.2. 3.2.1. 1 PSF_sim ──→ [× gain] ──→ [soft clamp / hard clamp] ──→ [min-max 归一化] ──→ [loss]
数学表达:
I det = g ⋅ I sim I_{\text{det}} = g \cdot I_{\text{sim}}
I det = g ⋅ I sim
I sat = clamp ( I det , max = s ) I_{\text{sat}} = \text{clamp}(I_{\text{det}},\; \max=s)
I sat = clamp ( I det , max = s )
I ~ = I sat − I sat , min I sat , max − I sat , min \tilde{I} = \frac{I_{\text{sat}} - I_{\text{sat},\min}}{I_{\text{sat},\max} - I_{\text{sat},\min}}
I ~ = I sat , max − I sat , min I sat − I sat , min
3.2.2.
类型
公式
特点
Hard clamp y = min ( x , s ) y = \min(x, s) y = min ( x , s ) 简单、物理直觉强,但梯度不连续
Soft clamp y = x − softplus ( x − s , β ) + ln 2 β y = x - \text{softplus}(x-s, \beta) + \frac{\ln 2}{\beta} y = x − softplus ( x − s , β ) + β ln 2 平滑过渡,梯度连续,参数 β \beta β
3.3. 3.3.1. 将 g g g s s s c > 0 c > 0 c > 0
g ′ = c ⋅ g , s ′ = c ⋅ s g' = c \cdot g, \quad s' = c \cdot s
g ′ = c ⋅ g , s ′ = c ⋅ s
探测器输出:
I det ′ = c ⋅ g ⋅ I = c ⋅ I det I'_{\text{det}} = c \cdot g \cdot I = c \cdot I_{\text{det}}
I det ′ = c ⋅ g ⋅ I = c ⋅ I det
饱和后(hard clamp 为例):
I sat ′ = min ( c ⋅ I det , c ⋅ s ) = c ⋅ min ( I det , s ) = c ⋅ I sat I'_{\text{sat}} = \min(c \cdot I_{\text{det}},\; c \cdot s) = c \cdot \min(I_{\text{det}},\; s) = c \cdot I_{\text{sat}}
I sat ′ = min ( c ⋅ I det , c ⋅ s ) = c ⋅ min ( I det , s ) = c ⋅ I sat
Min-max 归一化:
I ~ ′ = c ⋅ I sat − c ⋅ I sat , min c ⋅ I sat , max − c ⋅ I sat , min = I sat − I sat , min I sat , max − I sat , min = I ~ \tilde{I}' = \frac{c \cdot I_{\text{sat}} - c \cdot I_{\text{sat},\min}}{c \cdot I_{\text{sat},\max} - c \cdot I_{\text{sat},\min}} = \frac{I_{\text{sat}} - I_{\text{sat},\min}}{I_{\text{sat},\max} - I_{\text{sat},\min}} = \tilde{I}
I ~ ′ = c ⋅ I sat , max − c ⋅ I sat , min c ⋅ I sat − c ⋅ I sat , min = I sat , max − I sat , min I sat − I sat , min = I ~
定理 :( g , s ) (g, s) ( g , s ) 尺度等价的 。真正影响结果的不是它们的绝对值,而是比值 s / g s/g s / g (或者说"多少比例的像素达到饱和")。
3.3.2.
方案
有效自由度
是否等价
固定 g g g s s s
s / g s/g s / g ✓ 等价
固定 s s s g g g
s / g s/g s / g ✓ 等价
两者都学
s / g s/g s / g ✓ 等价
因此,从数学表达能力上,三种方案完全等价。
3.4. 虽然数学等价,但优化器(AdamW)在参数空间的几何形状 上有偏好。本节严格对比三种方案:
方案
可学习参数
有效自由度
等价性
A
固定 g g g s s s
s / g s/g s / g ✓ 等价
B
固定 s s s g g g
s / g s/g s / g ✓ 等价
C
两者都学
s / g s/g s / g ✓ 等价
3.4.1. 假设固定 g = 10 g = 10 g = 1 0 s true = 0.01 s_{\text{true}} = 0.01 s true = 0 . 0 1
s s s 1.0 1.0 1 . 0 需要下降 100 倍 才能到达目标
在到达目标之前的大部分迭代中,s ≫ g ⋅ p peak s \gg g \cdot p_{\text{peak}} s ≫ g ⋅ p peak 完全不饱和
Hard clamp 下 s s s ∼ 1 0 − 2 \sim 10^{-2} ∼ 1 0 − 2
优化器长时间在"死区"爬行
即使最终能收敛,s s s
3.4.2. 假设固定 s = 1.0 s = 1.0 s = 1 . 0 g true = 100 g_{\text{true}} = 100 g true = 1 0 0
g g g 10.0 10.0 1 0 . 0 需要上涨 10 倍 才能到达目标
在到达目标之前的大部分迭代中,g ⋅ p peak ≪ s g \cdot p_{\text{peak}} \ll s g ⋅ p peak ≪ s 完全不饱和
和方案 A 完全对称的问题:优化器在一维直线上搜索,长时间处于死区
反过来,如果真实需要的 gain 是 g true = 0.1 g_{\text{true}} = 0.1 g true = 0 . 1
g g g 所有样本从开始就严重过饱和
min-max 后的 PSF 形态被饱和"重塑",与真实数据不匹配
优化器很难从这种错误的状态中恢复
方案 A 和方案 B 是镜像问题 :固定任何一个参数,都会让另一个参数承担全部的量级调整负担,导致极端值和死区。
3.4.3. 优化器可以在二维 ( g , s ) (g, s) ( g , s ) 走对角线 :
g g g 10 10 1 0 1000 1000 1 0 0 0 s s s 1 1 1 10 10 1 0 比值 s / g = 0.01 s/g = 0.01 s / g = 0 . 0 1
但两个参数都停留在舒适的数量级(∼ 1 0 0 ∼ 1 0 3 \sim 10^0 \sim 10^3 ∼ 1 0 0 ∼ 1 0 3
避免了单个参数跨越多个数量级的痛苦漂移
这类似于线性回归中 y = w 1 x 1 + w 2 x 2 y = w_1 x_1 + w_2 x_2 y = w 1 x 1 + w 2 x 2 ( w 1 , w 2 ) (w_1, w_2) ( w 1 , w 2 )
左图 :固定 gain=10,只学 sat。优化器只能在一维直线上搜索,如果最优值在 sat=0.01,需要从 1.0 下降 100 倍,过程中长时间处于死区。
右图 :两者都学。等高线表示 loss 只依赖于比值 s / g s/g s / g s / g s/g s / g
3.4.4.
维度
固定 g g g s s s
固定 s s s g g g
两者都学
表达能力 等价
等价
等价
训练稳定性 差(参数可能漂到极端值)
差(同上)
好(参数保持在舒适区)
物理可解释性 s s s g g g g g g s s s
初始化敏感性 高(s s s
高(g g g
低(两者可相互补偿)
优化自由度 1 维
1 维
2 维(冗余 1 维)
结论 :
方案 A 和 B 是等价的,各自有相同的训练困难
方案 C 没有增加表达能力,但提供了训练舒适度
如果数据确实有饱和,推荐方案 C
如果数据基本无饱和,干脆去掉 gain 和 sat(最简单的方案)
3.5. 3.5.1. x x x y = min ( x , s ) y = \min(x, s)
y = min ( x , s )
∂ y ∂ x = { 1 x < s 0 x > s \frac{\partial y}{\partial x} = \begin{cases} 1 & x < s \\ 0 & x > s \end{cases}
∂ x ∂ y = { 1 0 x < s x > s
饱和区(x > s x > s x > s 这意味着:
过曝像素对前面所有层(mask、zernike 残差、blur kernel)的梯度贡献为 0
模型无法通过饱和区的像素来调整饱和形态
只能依赖未饱和区的像素间接影响
3.5.2. s s s ∂ y ∂ s = { 0 x < s (未饱和, s 不影响输出) 1 x > s (饱和, s 直接决定输出) \frac{\partial y}{\partial s} = \begin{cases} 0 & x < s \quad \text{(未饱和,$s$ 不影响输出)} \\ 1 & x > s \quad \text{(饱和,$s$ 直接决定输出)} \end{cases}
∂ s ∂ y = { 0 1 x < s (未饱和, s 不影响输出) x > s (饱和, s 直接决定输出)
问题 :
如果所有像素都未饱和(x < s x < s x < s s s s 0
如果所有像素都饱和(x > s x > s x > s s s s
这种"全有或全无"的梯度特性导致学习极不稳定
3.5.3. 如果 gain 固定,且初始化导致大部分样本永远不饱和 :
s s s 模型完全无法学习饱和阈值
3.6. 3.6.1. 我们希望一个函数 y ( x , s ) y(x, s) y ( x , s )
x ≪ s x \ll s x ≪ s y ≈ x y \approx x y ≈ x x ≫ s x \gg s x ≫ s y ≈ s y \approx s y ≈ s 过渡平滑,梯度连续
基于 softplus 的构造:
softplus ( z , β ) = 1 β ln ( 1 + e β z ) \text{softplus}(z, \beta) = \frac{1}{\beta} \ln(1 + e^{\beta z})
softplus ( z , β ) = β 1 ln ( 1 + e β z )
定义 soft clamp:
y = x − softplus ( x − s , β ) + ln 2 β y = x - \text{softplus}(x - s, \beta) + \frac{\ln 2}{\beta}
y = x − softplus ( x − s , β ) + β ln 2
为什么加 ln 2 β \frac{\ln 2}{\beta} β ln 2
当 x = s x = s x = s
softplus ( 0 , β ) = ln 2 β \text{softplus}(0, \beta) = \frac{\ln 2}{\beta}
softplus ( 0 , β ) = β ln 2
y = s − ln 2 β + ln 2 β = s y = s - \frac{\ln 2}{\beta} + \frac{\ln 2}{\beta} = s
y = s − β ln 2 + β ln 2 = s
修正项确保函数精确通过 饱和阈值点 ( s , s ) (s, s) ( s , s )
3.6.2. 对输入 x x x :
∂ y ∂ x = 1 − σ ( β ( x − s ) ) \frac{\partial y}{\partial x} = 1 - \sigma\bigl(\beta(x - s)\bigr)
∂ x ∂ y = 1 − σ ( β ( x − s ) )
其中 σ \sigma σ
区域
近似行为
梯度大小
x ≪ s x \ll s x ≪ s σ ≈ 0 \sigma \approx 0 σ ≈ 0 ≈ 1 \approx 1 ≈ 1
x = s x = s x = s σ = 0.5 \sigma = 0.5 σ = 0 . 5 = 0.5 = 0.5 = 0 . 5
x ≫ s x \gg s x ≫ s σ ≈ 1 \sigma \approx 1 σ ≈ 1 ≈ 0 \approx 0 ≈ 0
与 hard clamp 的关键区别:
Hard clamp:x > s x > s x > s 突变为 0
Soft clamp:x > s x > s x > s 指数衰减 到 1 0 − 7 ∼ 1 0 − 9 10^{-7} \sim 10^{-9} 1 0 − 7 ∼ 1 0 − 9
对饱和阈值 s s s :
∂ y ∂ s = σ ( β ( x − s ) ) \frac{\partial y}{\partial s} = \sigma\bigl(\beta(x - s)\bigr)
∂ s ∂ y = σ ( β ( x − s ) )
区域
梯度大小
x ≪ s x \ll s x ≪ s ≈ 0 \approx 0 ≈ 0
x = s x = s x = s = 0.5 = 0.5 = 0 . 5
x ≫ s x \gg s x ≫ s ≈ 1 \approx 1 ≈ 1
关键改进 :即使所有像素都未饱和(x < s x < s x < s s s s 微弱但非零 的梯度(约 0.01 ∼ 0.02 0.01 \sim 0.02 0 . 0 1 ∼ 0 . 0 2
3.6.3. 上述梯度分析看起来 soft clamp 比 hard clamp 好很多,但实际情况需要更诚实地审视。
定量对比 (β = 50 \beta = 50 β = 5 0
场景
hard clamp sat.grad
soft clamp sat.grad
差异
混合分布(部分饱和)
200.0
199.83
0.1%
全部饱和
100.0
99.99
0.01%
全部不饱和
0 0.018 唯一明显差异
输入梯度差异 > 0.1 的像素比例
—
—
仅 3%
结论 :
如果数据有明显饱和 (部分像素超过 sat,部分不超过):
hard clamp 和 soft clamp 几乎等价
差异只在边界过渡区(约 ± 0.06 \pm 0.06 ± 0 . 0 6
soft clamp 的优势非常有限
如果数据完全没有饱和 :
hard clamp:sat 完全不更新(梯度 = 0)
soft clamp:sat 有微弱漂移(梯度 ≈ 0.02 \approx 0.02 ≈ 0 . 0 2
这种漂移是好是坏不确定 ——可能帮助 sat 进入有效范围,也可能让 sat 无谓地乱飘
soft clamp 的真正价值可能是"打破僵局" :
训练初期如果全部不饱和,soft clamp 给 sat 一个微弱的下降信号
直到有像素开始触达饱和区,进入正常的学习状态
但一旦进入"正常"训练(部分饱和、部分不饱和),它和 hard clamp 几乎一样
真正决定 sat 能否学到的,不是 clamp 的类型,而是 :
gain 是否能把 PSF 峰值推到 sat 附近
参数初始化是否合适
数据中是否有足够的饱和样本
3.6.4. 上述理论分析指出 soft clamp 的优势有限。但在实际训练数据(相同模型、相同数据、仅 clamp 类型不同)中,观察到了一些有趣的差异。
实验设置 :
模型:Zernike2M4,deg=63,pad=256
数据:相同训练/测试集
唯一区别:temp_sigmoid/ 用 hard clamp,temp_gain_fix/ 用 soft clamp(β = 50 \beta=50 β = 5 0
其他所有超参数完全相同
测试 loss 逐 epoch 对比 :
epoch
hard clamp
soft clamp
差异(soft - hard)
1
0.2495
0.2478
-0.0017
2
0.2210
0.2138
-0.0072
3
0.2137
0.2070
-0.0067
4
0.2164
0.2009
-0.0155
5
0.2130
0.2020
-0.0110
6
0.2123
0.1991
-0.0132
7
0.2071
0.2073
+0.0002
8
0.2059
0.2154
+0.0095
9
0.2003
0.2005
+0.0002
10
0.2047
0.2067
+0.0020
11
0.2060
0.1957 -0.0104
12
0.2038
0.2147
+0.0109
13
0.2058
0.1992 -0.0066
14
0.1998
0.2053
+0.0055
统计汇总 (前 14 epoch):
指标
hard clamp
soft clamp
平均值
0.2099
0.2082
标准差
0.0103
0.0125
最小值
0.1998
0.1957
< 0.20 次数
1 次 3 次
< 0.205 次数
6 次
6 次
sat 参数最终值 (从 checkpoint 读取):
参数
hard clamp
soft clamp
sat_focus
0.4511
0.5194
sat_defocus
0.7629
0.8407
gain
7.9100
8.9933
关键发现 :
soft clamp 在训练中期(epoch 2~6)有明显优势
差距可达 0.013~0.015
这个阶段正好是 sat 快速下降的阶段(soft 中 sat_focus 从 1.0 → 0.55)
说明 soft clamp 提供的微弱梯度在 sat 尚未到位的阶段确实加速了收敛
hard clamp 的 sat 也在正常学习
sat_focus 从 1.0 降到 0.45,sat_defocus 降到 0.76
这推翻了"hard clamp 下 sat 完全学不到"的假设
优势不稳定
epoch 8、10、12 soft clamp 反而比 hard clamp 差
说明 soft clamp 不是系统性地更好,而是偶尔能撞到更好的局部最优
后期两者趋于一致
到 epoch 13~14,差距缩小到 ±0.005 以内
最终 M4 MAE 差异 < 2%
soft clamp 确实有可观察到的效果 ,主要体现在训练中期加速 sat 收敛但效果不稳定 ,不是系统性的精度提升
如果你只关心最终精度,两者差别不大
如果你关心训练过程的平滑度和收敛速度 ,soft clamp 有微弱优势
考虑到 soft clamp 增加了复杂度(公式、overshoot),这是一个边际收益 的选择
3.6.5. β \beta β β \beta β
β \beta β 过渡区宽度
特点
5 5 5 ± 0.6 \pm 0.6 ± 0 . 6 非常平滑,饱和区梯度较大
20 20 2 0 ± 0.15 \pm 0.15 ± 0 . 1 5 中等平滑
50 50 5 0 ± 0.06 \pm 0.06 ± 0 . 0 6 接近 hard clamp,但保留微弱梯度
200 200 2 0 0 ± 0.015 \pm 0.015 ± 0 . 0 1 5 几乎等价于 hard clamp,数值稳定性下降
选择 β = 50 \beta = 50 β = 5 0 :
过渡区宽度约 ± 0.06 \pm 0.06 ± 0 . 0 6
既保留了 hard clamp 的近似形态,又避免了梯度完全消失
PyTorch 的 F.softplus 内部有 threshold 保护,数值稳定
3.6.6. 当 x ≫ s x \gg s x ≫ s
softplus ( x − s , β ) ≈ x − s \text{softplus}(x - s, \beta) \approx x - s
softplus ( x − s , β ) ≈ x − s
y ≈ x − ( x − s ) + ln 2 β = s + ln 2 β y \approx x - (x - s) + \frac{\ln 2}{\beta} = s + \frac{\ln 2}{\beta}
y ≈ x − ( x − s ) + β ln 2 = s + β ln 2
饱和后的输出有一个固定 overshoot:
Δ y = ln 2 β ≈ 0.693 50 ≈ 0.014 \Delta y = \frac{\ln 2}{\beta} \approx \frac{0.693}{50} \approx 0.014
Δ y = β ln 2 ≈ 5 0 0 . 6 9 3 ≈ 0 . 0 1 4
影响评估 :
约 1.4 % 1.4\% 1 . 4 %
sat 是可学习参数,会自动补偿这个偏差(学到 s true − Δ y s_{\text{true}} - \Delta y s true − Δ y 对最终 PSF 形态的影响可忽略
3.7. 3.7.1. 左图 :四种饱和函数的输出形态。
hard clamp (蓝):x = 1 x=1 x = 1 exp sat (橙):sat * (1 - exp(-x/sat)),饱和极慢,x = 3 x=3 x = 3 sigmoid weighted (绿):非常接近 hard clamp,但有微小 overshoot(峰值到 1.02)softplus (beta=50) (红):最接近 hard clamp,过渡平滑无 overshoot
右图 :对 sat 参数的总梯度(所有像素求和)。
hard clamp、sigmoid weighted、softplus 的 sat 梯度都很大(~200)
exp sat 的 sat 梯度较小(~125),因为未饱和区"吸收"了部分梯度信号
3.7.2. x x x 左图 (线性坐标):
hard clamp(蓝):x < 1 x < 1 x < 1 x > 1 x > 1 x > 1 突变为 0
softplus(橙):x < 1 x < 1 x < 1 x > 1 x > 1 x > 1
右图 (对数坐标):
hard clamp:x > 1 x > 1 x > 1 1 0 − 10 10^{-10} 1 0 − 1 0
softplus:x > 1 x > 1 x > 1 永远不为 0 (x = 1.5 x=1.5 x = 1 . 5 1 0 − 7 10^{-7} 1 0 − 7 x = 2 x=2 x = 2 1 0 − 9 10^{-9} 1 0 − 9
4. 4.1. 本文严格分析光学仿真链路中**光瞳振幅掩模(pupil amplitude mask)**的参数化选择。核心问题是:
无界掩模 (如 M = exp ( m ) M = \exp(m) M = exp ( m ) 有界掩模 + 可学习增益 (如 M = σ ( m ) ∈ ( 0 , 1 ) M = \sigma(m) \in (0,1) M = σ ( m ) ∈ ( 0 , 1 ) g g g
结论 :
目标空间(min-max 后):两者严格等价。 任何无界 mask 产生的 PSF 形态,sigmoid+gain 都能复现。训练过程(梯度动态):两者不等价。 sigmoid 的硬边界约束能带来更稳定的训练、更好的物理解释性。
4.2.
符号
含义
P ( u , v ) P(u,v) P ( u , v ) 原始二元光瞳掩膜(圆形孔径,{ 0 , 1 } \{0,1\} { 0 , 1 }
M ( u , v ) M(u,v) M ( u , v ) 可学习的光瞳振幅修正因子
m ( u , v ) m(u,v) m ( u , v ) 网络直接优化的可学习参数(R \mathbb{R} R
A eff ( u , v ) A_{\text{eff}}(u,v) A eff ( u , v ) 有效光瞳振幅 = P ⋅ M = P \cdot M = P ⋅ M
ϕ ( u , v ) \phi(u,v) ϕ ( u , v ) 波前相位(Zernike 多项式描述)
U ( x , y ) U(x,y) U ( x , y ) 焦平面复振幅
I ( x , y ) I(x,y) I ( x , y ) 焦平面光强 $=
g g g 探测器增益
I det ( x , y ) I_{\text{det}}(x,y) I det ( x , y ) 探测器输出
I ~ ( x , y ) \tilde{I}(x,y) I ~ ( x , y ) min-max 归一化后的 PSF
F { ⋅ } \mathcal{F}\{\cdot\} F { ⋅ } 二维傅里叶变换
σ ( ⋅ ) \sigma(\cdot) σ ( ⋅ ) sigmoid 函数:σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1+e^{-x}} σ ( x ) = 1 + e − x 1
4.3. 4.3.1. 焦平面复振幅是光瞳复振幅的傅里叶变换:
U ( x , y ) = F { A eff ( u , v ) ⋅ e i ϕ ( u , v ) } U(x,y) = \mathcal{F}\{A_{\text{eff}}(u,v) \cdot e^{i\phi(u,v)}\}
U ( x , y ) = F { A eff ( u , v ) ⋅ e i ϕ ( u , v ) }
光强:
I ( x , y ) = ∣ U ( x , y ) ∣ 2 = ∣ F { P ⋅ M ⋅ e i ϕ } ∣ 2 I(x,y) = |U(x,y)|^2 = \left| \mathcal{F}\{P \cdot M \cdot e^{i\phi}\} \right|^2
I ( x , y ) = ∣ U ( x , y ) ∣ 2 = ∣ ∣ F { P ⋅ M ⋅ e i ϕ } ∣ ∣ 2
4.3.2. I det = g ⋅ I , I ~ = I det − I det , min I det , max − I det , min I_{\text{det}} = g \cdot I, \quad \tilde{I} = \frac{I_{\text{det}} - I_{\text{det},\min}}{I_{\text{det},\max} - I_{\text{det},\min}}
I det = g ⋅ I , I ~ = I det , max − I det , min I det − I det , min
对于背景已扣除、无负值的 PSF 图像,I det , min = 0 I_{\text{det},\min} = 0 I det , min = 0
I ~ = I det I det , max = g ⋅ I g ⋅ I max = I I max \tilde{I} = \frac{I_{\text{det}}}{I_{\text{det},\max}} = \frac{g \cdot I}{g \cdot I_{\max}} = \frac{I}{I_{\max}}
I ~ = I det , max I det = g ⋅ I max g ⋅ I = I max I
min-max 消去了 g g g
4.4. 4.4.1. 任意正的无界掩模 M A ( u , v ) = exp ( m A ( u , v ) ) > 0 M_A(u,v) = \exp(m_A(u,v)) > 0 M A ( u , v ) = exp ( m A ( u , v ) ) > 0
M A ( u , v ) = c ⋅ M ~ ( u , v ) M_A(u,v) = c \cdot \tilde{M}(u,v)
M A ( u , v ) = c ⋅ M ~ ( u , v )
其中:
c = max u , v M A ( u , v ) > 0 c = \max_{u,v} M_A(u,v) > 0 c = max u , v M A ( u , v ) > 0 M ~ ( u , v ) = M A ( u , v ) / c ∈ ( 0 , 1 ] \tilde{M}(u,v) = M_A(u,v) / c \in (0, 1] M ~ ( u , v ) = M A ( u , v ) / c ∈ ( 0 , 1 ]
代入夫琅禾费衍射,由 FFT 线性性:
F { P ⋅ M A ⋅ e i ϕ } = c ⋅ F { P ⋅ M ~ ⋅ e i ϕ } \mathcal{F}\{P \cdot M_A \cdot e^{i\phi}\} = c \cdot \mathcal{F}\{P \cdot \tilde{M} \cdot e^{i\phi}\}
F { P ⋅ M A ⋅ e i ϕ } = c ⋅ F { P ⋅ M ~ ⋅ e i ϕ }
光强:
I A = c 2 ⋅ ∣ F { P ⋅ M ~ ⋅ e i ϕ } ∣ 2 I_A = c^2 \cdot \left| \mathcal{F}\{P \cdot \tilde{M} \cdot e^{i\phi}\} \right|^2
I A = c 2 ⋅ ∣ ∣ ∣ F { P ⋅ M ~ ⋅ e i ϕ } ∣ ∣ ∣ 2
探测器输出(含增益 g g g
I det , A = g ⋅ c 2 ⋅ ∣ F { P ⋅ M ~ ⋅ e i ϕ } ∣ 2 I_{\text{det},A} = g \cdot c^2 \cdot \left| \mathcal{F}\{P \cdot \tilde{M} \cdot e^{i\phi}\} \right|^2
I det , A = g ⋅ c 2 ⋅ ∣ ∣ ∣ F { P ⋅ M ~ ⋅ e i ϕ } ∣ ∣ ∣ 2
min-max 后:
I ~ A = ∣ F { P ⋅ M ~ ⋅ e i ϕ } ∣ 2 max ∣ F { P ⋅ M ~ ⋅ e i ϕ } ∣ 2 \tilde{I}_A = \frac{\left| \mathcal{F}\{P \cdot \tilde{M} \cdot e^{i\phi}\} \right|^2}{\max \left| \mathcal{F}\{P \cdot \tilde{M} \cdot e^{i\phi}\} \right|^2}
I ~ A = max ∣ ∣ ∣ F { P ⋅ M ~ ⋅ e i ϕ } ∣ ∣ ∣ 2 ∣ ∣ ∣ F { P ⋅ M ~ ⋅ e i ϕ } ∣ ∣ ∣ 2
c c c g g g
4.4.2. 对于 sigmoid 参数化 M B ( u , v ) = σ ( m B ( u , v ) ) ∈ ( 0 , 1 ) M_B(u,v) = \sigma(m_B(u,v)) \in (0,1) M B ( u , v ) = σ ( m B ( u , v ) ) ∈ ( 0 , 1 )
只要选择 m B m_B m B σ ( m B ) = M ~ \sigma(m_B) = \tilde{M} σ ( m B ) = M ~ m B = σ − 1 ( M ~ ) m_B = \sigma^{-1}(\tilde{M}) m B = σ − 1 ( M ~ )
I ~ B = ∣ F { P ⋅ M ~ ⋅ e i ϕ } ∣ 2 max ∣ F { P ⋅ M ~ ⋅ e i ϕ } ∣ 2 = I ~ A \tilde{I}_B = \frac{\left| \mathcal{F}\{P \cdot \tilde{M} \cdot e^{i\phi}\} \right|^2}{\max \left| \mathcal{F}\{P \cdot \tilde{M} \cdot e^{i\phi}\} \right|^2} = \tilde{I}_A
I ~ B = max ∣ ∣ ∣ F { P ⋅ M ~ ⋅ e i ϕ } ∣ ∣ ∣ 2 ∣ ∣ ∣ F { P ⋅ M ~ ⋅ e i ϕ } ∣ ∣ ∣ 2 = I ~ A
由于 M ~ ∈ ( 0 , 1 ] \tilde{M} \in (0,1] M ~ ∈ ( 0 , 1 ] σ − 1 ( M ~ ) = ln ( M ~ / ( 1 − M ~ ) ) \sigma^{-1}(\tilde{M}) = \ln(\tilde{M}/(1-\tilde{M})) σ − 1 ( M ~ ) = ln ( M ~ / ( 1 − M ~ ) ) M ~ → 0 \tilde{M} \to 0 M ~ → 0 m B → − ∞ m_B \to -\infty m B → − ∞ M ~ = 1 \tilde{M} = 1 M ~ = 1 m B → + ∞ m_B \to +\infty m B → + ∞
4.4.3. 定理 :对于任意无界正掩模 M A ( u , v ) > 0 M_A(u,v) > 0 M A ( u , v ) > 0 M B ( u , v ) = σ ( m B ( u , v ) ) ∈ ( 0 , 1 ] M_B(u,v) = \sigma(m_B(u,v)) \in (0,1] M B ( u , v ) = σ ( m B ( u , v ) ) ∈ ( 0 , 1 ] g g g
I ~ A ≡ I ~ B \tilde{I}_A \equiv \tilde{I}_B
I ~ A ≡ I ~ B
证明要点 :
分解 M A = c ⋅ M ~ M_A = c \cdot \tilde{M} M A = c ⋅ M ~ M ~ ∈ ( 0 , 1 ] \tilde{M} \in (0,1] M ~ ∈ ( 0 , 1 ]
FFT 线性性将 c c c
光强的 ∣ ⋅ ∣ 2 |\cdot|^2 ∣ ⋅ ∣ 2 c c c c 2 c^2 c 2
min-max 归一化消去 c 2 c^2 c 2 g g g
Sigmoid 可以表示任意 M ~ ∈ ( 0 , 1 ] \tilde{M} \in (0,1] M ~ ∈ ( 0 , 1 ]
因此,在 min-max 后的目标空间中,无界 exp 和 sigmoid+gain 严格等价。
4.5. 4.5.1. 注意:以下问题不是 "min-max 后等价性"层面的,而是训练过程中 exp 参数化独有的病态。
4.5.1.1. Exp 参数化中:
M ( u , v ) = e m ( u , v ) = e m ˉ ⋅ e δ m ( u , v ) M(u,v) = e^{m(u,v)} = e^{\bar{m}} \cdot e^{\delta m(u,v)}
M ( u , v ) = e m ( u , v ) = e m ˉ ⋅ e δ m ( u , v )
全局缩放 c = e m ˉ c = e^{\bar{m}} c = e m ˉ e δ m e^{\delta m} e δ m 同一个参数向量的两个成分 ,无法独立控制。
这意味着:
模型为了让某个局部区域 M = 12 M = 12 M = 1 2 m m m
这会导致所有 区域的 M M M
结果就是:mask 参数向量整体漂移,局部相对分布被淹没在巨大的绝对值中
对比 sigmoid+gain :
Sigmoid 硬约束 M ∈ ( 0 , 1 ) M \in (0,1) M ∈ ( 0 , 1 )
全局能量放大由独立的 gain 参数承担
Mask 只负责"相对形状",不干扰全局尺度
4.5.1.2. 如果把无界 mask M M M M = c ⋅ M ~ M = c \cdot \tilde{M} M = c ⋅ M ~ c = max M c = \max M c = max M M ~ ∈ ( 0 , 1 ] \tilde{M} \in (0,1] M ~ ∈ ( 0 , 1 ] c c c 前向传播 上是等价的。
但两种参数化的反向传播 几何结构不同:
Exp
Sigmoid
映射
M = e m M = e^m M = e m M = σ ( m ) M = \sigma(m) M = σ ( m )
局部敏感度
∂ M / ∂ m = M \partial M/\partial m = M ∂ M / ∂ m = M ∂ M / ∂ m = M ( 1 − M ) ≤ 0.25 \partial M/\partial m = M(1-M) \leq 0.25 ∂ M / ∂ m = M ( 1 − M ) ≤ 0 . 2 5
M ≪ 1 M \ll 1 M ≪ 1 两者近似相等
两者近似相等
M → 1 M \to 1 M → 1 敏感度 $ o 1$
敏感度 → 0 \to 0 → 0
M > 1 M > 1 M > 1 敏感度 > 1 > 1 > 1
不可能发生
这导致 exp 的参数空间是一个扭曲的流形 :
m m m m m m 但优化器看到的梯度是这两者的耦合
Sigmoid 把参数空间分解 为:
mask 子空间:只学相对形状(M ∈ ( 0 , 1 ) M \in (0,1) M ∈ ( 0 , 1 )
gain 子空间:只学校正全局尺度(1 维)
这种分解让优化器更容易找到好的解。
4.5.1.3. Exp 参数化下,m ( u , v ) ∈ R m(u,v) \in \mathbb{R} m ( u , v ) ∈ R
某些区域 m = + 5 m = +5 m = + 5 M ≈ 148 M \approx 148 M ≈ 1 4 8
某些区域 m = − 5 m = -5 m = − 5 M ≈ 0.007 M \approx 0.007 M ≈ 0 . 0 0 7
这种极端动态范围(1 0 5 10^5 1 0 5
数值精度问题(float32 的有效位数约 7 位)
优化器步长难以统一(adam 的自适应学习率在不同参数上差异巨大)
对比 sigmoid+gain :
Sigmoid 把 m m m ( − 5 , + 5 ) (-5, +5) ( − 5 , + 5 )
参数值自然集中在合理范围
4.5.1.4.
M > 1 M > 1 M > 1 实际系统中,光瞳透过率不可能超过 100%
全局照明增强应该是 gain 的事,不是 mask 的事
4.5.1.5. 之前曾认为"exp 的 mask 梯度会爆炸,sigmoid 不会"。但这个说法夸大了差异 :
Sigmoid+gain 中 gain 也会放大整个网络的梯度 (gain=12 时,前面所有层梯度放大 12 倍)两者的全局能量参数都会通过反向传播影响整个网络 真正区分两者的不是"梯度数值",而是"参数空间的几何结构"
Exp 的问题不是"梯度更大",而是:
2601 个 mask 参数各自独立地缩放自己的梯度(非一致性)
全局缩放隐式分布在所有参数中(耦合)
参数可以无限漂移(无界)
Sigmoid+gain 中 gain 也会放大梯度,但:
放大是全局一致 的(所有参数同比例缩放,不改变相对方向)
全局缩放由单一参数 控制,可用梯度裁剪/weight decay 约束
Mask 参数自身有界,不会无限漂移
4.5.2. Sigmoid 把优化问题分解 为两个子空间:
子空间
参数
物理含义
维度
形状子空间
m B ( u , v ) m_B(u,v) m B ( u , v ) 光瞳相对透过率分布
2601
尺度子空间
g B g_B g B 相机增益/曝光量
1
饱和子空间
I sat I_{\text{sat}} I sat 满阱容量
1(或 2)
这种分离让优化器更容易处理:
mask 只负责"相对形状",不关心全局亮度
gain 只负责"全局尺度",不关心空间分布
两者不会互相干扰
4.5.3. 两种方案都存在"全局能量参数与饱和阈值的耦合":
Exp:c = e m ˉ c = e^{\bar{m}} c = e m ˉ
Sigmoid+gain:g B g_B g B
这不是 exp 独有的问题,而是任何全局能量参数 + 饱和阈值 都会出现的尺度等价性(见文档第 5.4 节)。
但 exp 的耦合更严重 :
c c c g g g
4.5.4.
维度
无界 exp + 可学习 gain
Sigmoid + 可学习 gain
参数空间结构 耦合(全局缩放隐式分布在 2601 个参数中)
解耦(shape / scale / sat 分离)
Mask 参数空间 无界(m ∈ R m \in \mathbb{R} m ∈ R
有效有界(σ \sigma σ ( − 5 , + 5 ) (-5,+5) ( − 5 , + 5 )
梯度一致性 非一致(各位置被各自 e m e^m e m
一致(gain 全局同比例缩放)
训练稳定性 差
好
物理可解释性 差(M M M
好(M ∈ ( 0 , 1 ) M \in (0,1) M ∈ ( 0 , 1 )
防止走捷径 否
是
饱和耦合 存在(且更严重)
存在(但 gain 单一可控)
4.5.5. 上表指出 sigmoid+可学习 gain 能"防止走捷径",但一个尖锐的问题:
既然 min-max 消掉了 gain,那 gain 为什么还要学?饱和阈值也是学的,它们不也是耦合的吗?
4.5.5.1. ( g , s ) (g, s) ( g , s ) 链路(含饱和):
I det = g ⋅ I , I sat = min ( g ⋅ I , s ) I_{\text{det}} = g \cdot I, \quad I_{\text{sat}} = \min(g \cdot I,\; s)
I det = g ⋅ I , I sat = min ( g ⋅ I , s )
同时缩放 g g g s s s c > 0 c > 0 c > 0
g ′ = c ⋅ g , s ′ = c ⋅ s g' = c \cdot g, \quad s' = c \cdot s
g ′ = c ⋅ g , s ′ = c ⋅ s
I sat ′ = min ( c ⋅ g ⋅ I , c ⋅ s ) = c ⋅ min ( g ⋅ I , s ) = c ⋅ I sat I'_{\text{sat}} = \min(c \cdot g \cdot I,\; c \cdot s) = c \cdot \min(g \cdot I,\; s) = c \cdot I_{\text{sat}}
I sat ′ = min ( c ⋅ g ⋅ I , c ⋅ s ) = c ⋅ min ( g ⋅ I , s ) = c ⋅ I sat
min-max 后:
I ~ ′ = c ⋅ I sat − c ⋅ I sat , min c ⋅ I sat , max − c ⋅ I sat , min = I ~ \tilde{I}' = \frac{c \cdot I_{\text{sat}} - c \cdot I_{\text{sat},\min}}{c \cdot I_{\text{sat},\max} - c \cdot I_{\text{sat},\min}} = \tilde{I}
I ~ ′ = c ⋅ I sat , max − c ⋅ I sat , min c ⋅ I sat − c ⋅ I sat , min = I ~
结论 :( g , s ) (g, s) ( g , s ) 尺度等价的 。真正起作用的是比值 s / g s/g s / g
4.5.5.2.
冗余来源
性质
是否影响 min-max 后结果
物理后果
mask 全局缩放 c c c
完全冗余
否 (无论有无饱和)无物理意义,导致梯度爆炸
gain 绝对值 g g g
与 s s s
否 (只影响结果的是 s / g s/g s / g 冗余但不"错误"
gain-saturation 比值 s / g s/g s / g
关键物理量
是 决定是否饱和、削顶程度
所以:
mask 的全局缩放 c c c :无论什么情况都是纯冗余,必须被约束掉(sigmoid)gain 的绝对值 :和 saturation 冗余耦合,可以容忍gain-saturation 比值 s / g s/g s / g :是关键物理量,必须保留
4.5.5.3. 如果要消除所有冗余自由度:
Mask :sigmoid 约束到 ( 0 , 1 ) (0,1) ( 0 , 1 ) c c c Gain :固定为常数(如 g = 1 g = 1 g = 1 Saturation :唯一可学习的能量相关参数
或者反过来固定 saturation、只学 gain。
但在实践中,两者都学也没问题——优化器只是多一个冗余方向,不会导致梯度爆炸(不像 e m e^m e m
gain 对应探测器增益/曝光量saturation 对应满阱容量
5. 5.1.
参数
符号
实际值
单位
探测器单边像素数
N 400 pixels
单个像素物理尺寸
p 4.5 μm
探测器总物理宽度
Np 400 × 4.5 = 1800
μm = 1.8 mm
探测器半宽(中心到边缘)
Np/2 1800 / 2 = 900
μm = 0.9 mm
激光波长
λ 530 nm
光瞳到CCD焦距
f 1.248 m
光瞳直径
D 60 mm
艾里斑半径
r_A = 1.22λf/D 13.45 μm
FOV (Field of View,视场)就是探测器在焦平面上能覆盖的物理范围。探测器是 400 × 400 像素,每个像素 4.5 μm,所以总宽度是 1.8 mm,以中心为原点,FOV 就是 [-0.9 mm, +0.9 mm] ,写作 [-Np/2, +Np/2] 。
5.2. 5.2.1. 波前相位 ϕ ( u ) \phi(\mathbf{u}) ϕ ( u ) 角谱法 。其核心思想是:
把任意波面看成无数个不同倾斜角度的平面波(角谱分量)的叠加。
空间频率低 → 平面波倾斜角小 → 光线偏折小
空间频率高 → 平面波倾斜角大 → 光线偏折大
具体关系:对于 pupil 上空间频率为 k k k
θ ≈ λ k ( 小角度近似, λ k ≪ 1 ) \theta \approx \lambda k \quad (\text{小角度近似,} \lambda k \ll 1)
θ ≈ λ k ( 小角度近似, λ k ≪ 1 )
经过焦距 f f f
x = f ⋅ θ = λ f ⋅ k x = f \cdot \theta = \lambda f \cdot k
x = f ⋅ θ = λ f ⋅ k
所以:pupil 上的空间频率 k k k x = λ f k x = \lambda f k x = λ f k
这就是后面所有推导的物理根源——也是角谱法的直接推论。
5.2.2. 光瞳平面上的复场 P ( u ) P(\mathbf{u}) P ( u ) f f f U ( x ) U(\mathbf{x}) U ( x ) P ( u ) P(\mathbf{u}) P ( u )
U ( x ) = 1 λ f ∬ P ( u ) exp ( − i 2 π λ f u ⋅ x ) d u U(\mathbf{x}) = \frac{1}{\lambda f} \iint P(\mathbf{u}) \exp\left(-i \frac{2\pi}{\lambda f} \mathbf{u} \cdot \mathbf{x}\right) d\mathbf{u}
U ( x ) = λ f 1 ∬ P ( u ) exp ( − i λ f 2 π u ⋅ x ) d u
这个式子告诉我们一件事:
焦平面上的坐标 x \mathbf{x} x
具体来说,如果我们定义光瞳域的空间频率为 k \mathbf{k} k
k = x λ f \mathbf{k} = \frac{\mathbf{x}}{\lambda f}
k = λ f x
那么焦平面复振幅就是光瞳复场在频率 k \mathbf{k} k
U ( x ) ∝ P ^ ( k = x λ f ) U(\mathbf{x}) \propto \hat{P}\left(\mathbf{k} = \frac{\mathbf{x}}{\lambda f}\right)
U ( x ) ∝ P ^ ( k = λ f x )
5.2.3. 探测器只能接收到焦平面上 x ∈ [ − N p / 2 , + N p / 2 ] x \in [-Np/2, +Np/2] x ∈ [ − N p / 2 , + N p / 2 ]
把 x m a x = N p / 2 = 900 μ m x_{max} = Np/2 = 900\ \mu\text{m} x m a x = N p / 2 = 9 0 0 μ m k = x / ( λ f ) \mathbf{k} = \mathbf{x}/(\lambda f) k = x / ( λ f )
k m a x = N p / 2 λ f = 900 × 1 0 − 6 530 × 1 0 − 9 × 1.248 ≈ 9 × 1 0 − 4 6.614 × 1 0 − 7 ≈ 1360 cycles/m k_{max} = \frac{Np/2}{\lambda f} = \frac{900\times 10^{-6}}{530\times 10^{-9} \times 1.248} \approx \frac{9\times 10^{-4}}{6.614\times 10^{-7}} \approx \mathbf{1360\ \text{cycles/m}}
k m a x = λ f N p / 2 = 5 3 0 × 1 0 − 9 × 1 . 2 4 8 9 0 0 × 1 0 − 6 ≈ 6 . 6 1 4 × 1 0 − 7 9 × 1 0 − 4 ≈ 1 3 6 0 cycles/m
这是以 cycles/m(每米多少周期)为单位。换算成更直观的 cycles/pupil (光瞳直径上有多少个周期):
n m a x = k m a x × D = 1360 × 0.06 ≈ 81.6 cycles/pupil n_{max} = k_{max} \times D = 1360 \times 0.06 \approx \mathbf{81.6\ \text{cycles/pupil}}
n m a x = k m a x × D = 1 3 6 0 × 0 . 0 6 ≈ 8 1 . 6 cycles/pupil
5.2.4. 角谱法分析的是光瞳复场 P ( u ) = A ( u ) e i ϕ ( u ) P(u) = A(u)e^{i\phi(u)} P ( u ) = A ( u ) e i ϕ ( u ) 。将它分解为不同空间频率的平面波成分 e i 2 π k u e^{i2\pi k u} e i 2 π k u
P ( u ) = ∫ P ^ ( k ) e i 2 π k u d k ⇒ U ( x ) = ∑ (艾里斑叠加) P(u) = \int \hat{P}(k) e^{i2\pi k u} dk \quad \Rightarrow \quad U(x) = \sum \text{(艾里斑叠加)}
P ( u ) = ∫ P ^ ( k ) e i 2 π k u d k ⇒ U ( x ) = ∑ ( 艾里斑叠加 )
关键物理图像 :
复场中空间频率为 k k k
聚焦位置 x = λ f k x = \lambda f k x = λ f k
换算成 cycles/pupil:n = k D n = kD n = k D x = n λ f / D x = n \lambda f / D x = n λ f / D
这就是 Pupil 频率 n n n
5.3. 5.3.1. 5.3.1.1. 一束理想平面波 以倾斜角 θ \theta θ f f f
x = f ⋅ tan θ ≈ f ⋅ θ ( 小角度 ) x = f \cdot \tan\theta \approx f \cdot \theta \quad (\text{小角度})
x = f ⋅ tan θ ≈ f ⋅ θ ( 小角度 )
5.3.1.2. 角谱法将光瞳复场 P ( u ) P(u) P ( u ) e i 2 π k u e^{i2\pi k u} e i 2 π k u k k k
θ = λ k \theta = \lambda k
θ = λ k
因此,角谱成分 k k k
x = λ f ⋅ k x = \lambda f \cdot k
x = λ f ⋅ k
换算成 cycles/pupil(n = k D n = kD n = k D
x = n ⋅ λ f D x = n \cdot \frac{\lambda f}{D}
x = n ⋅ D λ f
代入系统参数:
λ f D = 530 × 1 0 − 9 × 1.248 0.06 ≈ 11.0 μ m \frac{\lambda f}{D} = \frac{530\times 10^{-9} \times 1.248}{0.06} \approx 11.0\ \mu\text{m}
D λ f = 0 . 0 6 5 3 0 × 1 0 − 9 × 1 . 2 4 8 ≈ 1 1 . 0 μ m
物理图像非常直接 :角谱中每增加 1 cycle/pupil 的频率,对应成分就往焦平面两边各移动 11.0 μm。
5.3.1.3. 实际光瞳直径 D D D A ( u ) A(u) A ( u ) 艾里斑 ——形状由光瞳决定,但位置只由倾斜角(即角谱频率)决定 。
5.3.1.4. 探测器是 400 × 400 像素,像素尺寸 4.5 μm,所以总范围是:
FOV = 400 × 4.5 μ m = 1.8 mm \text{FOV} = 400 \times 4.5\ \mu\text{m} = 1.8\ \text{mm}
FOV = 4 0 0 × 4 . 5 μ m = 1 . 8 mm
半宽为 ±900 μm。角谱成分一旦聚焦到 ∣ x ∣ > 900 |x| > 900 ∣ x ∣ > 9 0 0 跑出探测器了 。
角谱频率 n n n
聚焦位置 x = ± n × 11.0 x = \pm n \times 11.0 x = ± n × 1 1 . 0
在探测器内吗?
10
±110 μm
✅
40
±440 μm
✅
80
±880 μm
✅ 靠近边缘
81.6 ±898 μm ✅ 刚好擦边
82
±902 μm
❌ 跑出边界
100
±1100 μm
❌
出界条件:
n ⋅ λ f D ≤ N p 2 n \cdot \frac{\lambda f}{D} \leq \frac{Np}{2}
n ⋅ D λ f ≤ 2 N p
整理得:
n m a x = N p D 2 λ f ≈ 81.6 n_{max} = \frac{NpD}{2\lambda f} \approx 81.6
n m a x = 2 λ f N p D ≈ 8 1 . 6
5.4. 5.4.1. 对探测器采集到的焦平面强度图 I ( x ) I(x) I ( x ) P ( u ) P(u) P ( u ) 自相关 (这是傅里叶光学的一个标准结论)。
所以:对焦平面强度做 DFT,本质上就是在 pupil 域上做分析。
5.4.2. 对 400 × 400 像素做 DFT,DFT 会输出 400 个频率分量。这些频率分量的「频率轴」并不是随便的——
根据角谱法的对应关系 x = λ f ⋅ k x = \lambda f \cdot k x = λ f ⋅ k x x x k k k 焦平面 DFT 的频率轴,经过缩放后,就是 pupil 上的位置轴。
具体来说:
焦平面的总采样长度:L = N p = 400 × 4.5 μ m = 1.8 L = Np = 400 \times 4.5\ \mu\text{m} = 1.8 L = N p = 4 0 0 × 4 . 5 μ m = 1 . 8
DFT 的频率分辨率(相邻两个频率 bin 的间隔):Δ k = 1 / L = 1 / ( N p ) \Delta k = 1/L = 1/(Np) Δ k = 1 / L = 1 / ( N p )
把频率分辨率换算回 pupil 坐标(乘以 λ f \lambda f λ f
Δ u = λ f ⋅ Δ k = λ f N p \Delta u = \lambda f \cdot \Delta k = \frac{\lambda f}{Np}
Δ u = λ f ⋅ Δ k = N p λ f
代入数字:
Δ u = 530 × 1 0 − 9 × 1.248 400 × 4.5 × 1 0 − 6 = 6.614 × 1 0 − 7 1.8 × 1 0 − 3 ≈ 0.367 m m \Delta u = \frac{530\times 10^{-9} \times 1.248}{400 \times 4.5\times 10^{-6}} = \frac{6.614\times 10^{-7}}{1.8\times 10^{-3}} \approx \mathbf{0.367\ mm}
Δ u = 4 0 0 × 4 . 5 × 1 0 − 6 5 3 0 × 1 0 − 9 × 1 . 2 4 8 = 1 . 8 × 1 0 − 3 6 . 6 1 4 × 1 0 − 7 ≈ 0 . 3 6 7 m m
物理意义:焦平面 DFT 的相邻两个频率 bin,对应 pupil 上相距 0.367 mm 的两个位置。
5.4.3. 光瞳直径 D = 60 D = 60 D = 6 0
N p u p i l = D Δ u = 60 0.367 ≈ 163.4 段 N_{pupil} = \frac{D}{\Delta u} = \frac{60}{0.367} \approx \mathbf{163.4\ \text{段}}
N p u p i l = Δ u D = 0 . 3 6 7 6 0 ≈ 1 6 3 . 4 段
这相当于: 400 像素探测器,在 pupil 直径方向上提供了约 163 个独立采样点 。
5.4.4. 根据奈奎斯特采样定理,163 个采样点能无混叠表示的最高空间频率为:
n m a x = N p u p i l 2 = 163.4 2 ≈ 81.7 cycles/pupil n_{max} = \frac{N_{pupil}}{2} = \frac{163.4}{2} \approx \mathbf{81.7\ \text{cycles/pupil}}
n m a x = 2 N p u p i l = 2 1 6 3 . 4 ≈ 8 1 . 7 cycles/pupil
5.4.5.
推导方法
核心思路
结果
探测器 FOV 限制 (第 3 节)角谱分量聚焦点跑出探测器边缘
81.6
采样定理法 (本节)400 像素 → pupil 上 163 个采样点 → 奈奎斯特极限
81.7
两种完全不同的思路,得到完全一样的数。这不是巧合,而是角谱法对偶性的必然结果。
5.5. 5.5.1. T m i n = D n m a x = 60 mm 81.6 ≈ 735 μ m ≈ 0.735 m m T_{min} = \frac{D}{n_{max}} = \frac{60\ \text{mm}}{81.6} \approx \mathbf{735\ \mu m} \approx \mathbf{0.735\ mm}
T m i n = n m a x D = 8 1 . 6 6 0 mm ≈ 7 3 5 μ m ≈ 0 . 7 3 5 m m
PSF光路,理论上能分辨的波前最短周期约为 0.735 毫米 。
5.5.2. 艾里斑半径 r A ≈ 13.45 r_A \approx 13.45 r A ≈ 1 3 . 4 5
角谱高频分量聚焦到探测器边缘时,离中心的距离是 900 μm,大约是 67 个艾里斑半径 。
这说明:PSF 对高频波前的感知,不是通过「改变中心艾里斑形状」,而是通过「在很远的地方产生微弱的角谱响应」来实现的。
5.6. 上面分析的是上限 (最高能探测到多少)。这一节分析下限 ——多低的频率还能被 PSF 感知?相邻两个频率模式之间的最小可分辨间隔是多少?
5.6.1. 5.6.1.1. 焦平面上相邻两个像素相距 p = 4.5 p = 4.5 p = 4 . 5 x = λ f ⋅ k x = \lambda f \cdot k x = λ f ⋅ k p p p 绝对频率间隔 :
Δ k = p λ f \Delta k = \frac{p}{\lambda f}
Δ k = λ f p
代入参数:
Δ k = 4.5 × 1 0 − 6 530 × 1 0 − 9 × 1.248 ≈ 6.8 cycles/m \Delta k = \frac{4.5\times 10^{-6}}{530\times 10^{-9} \times 1.248} \approx \mathbf{6.8\ \text{cycles/m}}
Δ k = 5 3 0 × 1 0 − 9 × 1 . 2 4 8 4 . 5 × 1 0 − 6 ≈ 6 . 8 cycles/m
这一步只和像素尺寸 p p p ,和口径 D D D
5.6.1.2. 前面的 0.41 cycles/pupil 只是像素采样层面的数字分辨率 ,但光学系统本身有衍射极限 (瑞利判据),两个相近的频率模式产生的角谱聚焦点可能因为艾里斑重叠而无法区分。
瑞利判据 :两个点光源刚好能被分辨时,其间距为艾里斑半径:
δ x R a y l e i g h = 1.22 λ f D ≈ 13.45 μ m \delta x_{Rayleigh} = 1.22 \frac{\lambda f}{D} \approx 13.45\ \mu\text{m}
δ x R a y l e i g h = 1 . 2 2 D λ f ≈ 1 3 . 4 5 μ m
5.6.1.3. 角谱法中,光瞳复场 P ( u ) P(u) P ( u ) e i 2 π k u e^{i2\pi k u} e i 2 π k u x = λ f k x = \lambda f k x = λ f k n = k D n = kD n = k D
x = n ⋅ λ f D x = n \cdot \frac{\lambda f}{D}
x = n ⋅ D λ f
代入系统参数:
λ f D = 530 × 1 0 − 9 × 1.248 0.06 ≈ 11.02 μ m \frac{\lambda f}{D} = \frac{530\times 10^{-9} \times 1.248}{0.06} \approx 11.02\ \mu\text{m}
D λ f = 0 . 0 6 5 3 0 × 1 0 − 9 × 1 . 2 4 8 ≈ 1 1 . 0 2 μ m
所以角谱频率为 n n n x = ± n × 11.02 x = \pm n \times 11.02 x = ± n × 1 1 . 0 2
5.6.1.4. 考虑角谱中两个相邻的频率 n n n n + Δ n n + \Delta n n + Δ n
频率 n n n x n = n × 11.02 x_n = n \times 11.02 x n = n × 1 1 . 0 2
频率 n + Δ n n + \Delta n n + Δ n x n + Δ n = ( n + Δ n ) × 11.02 x_{n+\Delta n} = (n + \Delta n) \times 11.02 x n + Δ n = ( n + Δ n ) × 1 1 . 0 2
两者间距:
Δ x = Δ n × 11.02 μ m = Δ n ⋅ λ f D \Delta x = \Delta n \times 11.02\ \mu\text{m} = \Delta n \cdot \frac{\lambda f}{D}
Δ x = Δ n × 1 1 . 0 2 μ m = Δ n ⋅ D λ f
5.6.1.5. 要作为独立光斑 分辨这两个聚焦点,它们的间距必须大于等于艾里斑半径:
Δ x ≥ δ x R a y l e i g h = 1.22 λ f D ≈ 13.45 μ m \Delta x \geq \delta x_{Rayleigh} = 1.22\frac{\lambda f}{D} \approx 13.45\ \mu\text{m}
Δ x ≥ δ x R a y l e i g h = 1 . 2 2 D λ f ≈ 1 3 . 4 5 μ m
代入 Δ x = Δ n × 11.02 \Delta x = \Delta n \times 11.02 Δ x = Δ n × 1 1 . 0 2
Δ n × 11.02 μ m ≥ 13.45 μ m \Delta n \times 11.02\ \mu\text{m} \geq 13.45\ \mu\text{m}
Δ n × 1 1 . 0 2 μ m ≥ 1 3 . 4 5 μ m
Δ n o p t ≥ 13.45 11.02 ≈ 1.22 \Delta n_{opt} \geq \frac{13.45}{11.02} \approx 1.22
Δ n o p t ≥ 1 1 . 0 2 1 3 . 4 5 ≈ 1 . 2 2
结论:仅考虑光学衍射极限,系统能分辨的最小频率间隔约为 1.22 cycles/pupil。
对比两个极限:
限制来源
物理含义
数值
系统是否受它限制?
像素采样 DFT 频率 bin 的间隔
0.41 cycles/pupil
❌ 不是瓶颈(像素够密)
光学衍射(瑞利判据) 两个角谱聚焦点作为独立光斑刚好可分辨
1.22 cycles/pupil ✅ 这是实际瓶颈
像素尺寸 p = 4.5 p = 4.5 p = 4 . 5 < r A = 13.45 < r_A = 13.45 < r A = 1 3 . 4 5 实际频率分辨率由光学衍射决定,约为 1.22 cycles/pupil ,而不是 0.41。
5.6.1.6. 在解释 n < 1.22 n < 1.22 n < 1 . 2 2 n > 1.22 n > 1.22 n > 1 . 2 2 艾里斑 和它的第一暗环 是什么。
5.6.1.6.1. 平行光经过圆形孔径 (直径 D D D f f f
I ( x ) = I 0 [ 2 J 1 ( π D ∣ x ∣ λ f ) π D ∣ x ∣ λ f ] 2 I(x) = I_0 \left[ \frac{2J_1\left( \frac{\pi D |x|}{\lambda f} \right)}{\frac{\pi D |x|}{\lambda f}} \right]^2
I ( x ) = I 0 ⎣ ⎡ λ f π D ∣ x ∣ 2 J 1 ( λ f π D ∣ x ∣ ) ⎦ ⎤ 2
其中 J 1 J_1 J 1
5.6.1.6.2. J 1 ( z ) J_1(z) J 1 ( z ) z ≈ 3.83 z \approx 3.83 z ≈ 3 . 8 3
π D r A λ f = 3.83 ⇒ r A = 3.83 π ⋅ λ f D = 1.22 λ f D \frac{\pi D r_A}{\lambda f} = 3.83 \quad \Rightarrow \quad r_A = \frac{3.83}{\pi} \cdot \frac{\lambda f}{D} = \mathbf{1.22 \frac{\lambda f}{D}}
λ f π D r A = 3 . 8 3 ⇒ r A = π 3 . 8 3 ⋅ D λ f = 1 . 2 2 D λ f
这就是瑞利判据 中那个著名的 1.22 的来源。
代入系统参数:
r A = 1.22 × 530 × 1 0 − 9 × 1.248 0.06 ≈ 13.45 μ m r_A = 1.22 \times \frac{530\times 10^{-9} \times 1.248}{0.06} \approx \mathbf{13.45\ \mu m}
r A = 1 . 2 2 × 0 . 0 6 5 3 0 × 1 0 − 9 × 1 . 2 4 8 ≈ 1 3 . 4 5 μ m
物理意义 :
第一暗环以内 (∣ x ∣ < 13.45 |x| < 13.45 ∣ x ∣ < 1 3 . 4 5 主瓣 ,集中了约 84% 的能量。第一暗环 (∣ x ∣ = 13.45 |x| = 13.45 ∣ x ∣ = 1 3 . 4 5 零 。第一暗环以外 (∣ x ∣ > 13.45 |x| > 13.45 ∣ x ∣ > 1 3 . 4 5
5.6.1.6.3. n = 1.22 n = 1.22 n = 1 . 2 2 角谱响应的聚焦位置是 x = n × 11.02 x = n \times 11.02 x = n × 1 1 . 0 2
频率 n n n
聚焦位置 x x x
与第一暗环 r A = 13.45 r_A = 13.45 r A = 1 3 . 4 5
n = 0.5 n = 0.5 n = 0 . 5 5.5 5.5 5 . 5 远在第一暗环内部
n = 1.0 n = 1.0 n = 1 . 0 11.0 11.0 1 1 . 0 在第一暗环内部
n = 1.22 n = 1.22 n = 1 . 2 2 13.45 13.45 1 3 . 4 5 刚好在第一暗环上
n = 2.0 n = 2.0 n = 2 . 0 22.0 22.0 2 2 . 0 跑出第一暗环外面
所以当 n < 1.22 n < 1.22 n < 1 . 2 2 整个主瓣都还在中心艾里斑的第一暗环以内 ,从外面看就是"淹没在中心亮斑里面",无法作为独立的结构被辨认出来。只有当 n > 1.22 n > 1.22 n > 1 . 2 2
5.6.1.7. 上面的 1.22 只适用于「角谱成分作为独立结构被分辨」的情况(n ≳ 1.22 n \gtrsim 1.22 n ≳ 1 . 2 2 n < 1.22 n < 1.22 n < 1 . 2 2
对于这类内部变形模式 ,相位恢复算法可以通过优化拟合整个强度场来区分相近的模式,其有效分辨率可以接近甚至突破瑞利判据(受信噪比限制)。
频率区间
分辨机制
有效频率分辨率
决定因素
n < 1.22 n < 1.22 n < 1 . 2 2 艾里斑内部形状变化
~0.4–1.0 cycles/pupil
像素采样 + 信噪比
n > 1.22 n > 1.22 n > 1 . 2 2 分离光斑的识别
~1.22 cycles/pupil 瑞利判据(衍射极限)
5.6.1.8. 如果估算"独立信息通道数",应该用采样定理 而非瑞利判据:
Pupil 直径上的等效采样点数:N p u p i l ≈ D / Δ u = 163 N_{pupil} \approx D / \Delta u = 163 N p u p i l ≈ D / Δ u = 1 6 3
奈奎斯特频率通道数:N c h a n n e l s = N p u p i l / 2 ≈ 81 N_{channels} = N_{pupil} / 2 \approx \mathbf{81} N c h a n n e l s = N p u p i l / 2 ≈ 8 1
这 81 个通道是信息论上限 ——假设有无限信噪比和完美算法,系统最多能区分约 81 个独立的频率成分。
5.6.1.9.
量
公式
物理意义
系统值
最大频率 n m a x = N p D / ( 2 λ f ) n_{max} = NpD/(2\lambda f) n m a x = N p D / ( 2 λ f ) 角谱聚焦点不跑出探测器的上限
81.6 cycles/pupil
采样频率分辨率
Δ n s a m p = p D / ( λ f ) \Delta n_{samp} = pD/(\lambda f) Δ n s a m p = p D / ( λ f ) DFT 频率 bin 间隔
0.41 cycles/pupil
光学频率分辨率 Δ n o p t = 1.22 \Delta n_{opt} = 1.22 Δ n o p t = 1 . 2 2 独立角谱聚焦点可分辨的最小间隔
1.22 cycles/pupil
信息论通道数
N p u p i l / 2 N_{pupil}/2 N p u p i l / 2 完美算法下的自由度上限
~81
5.6.2. 5.6.2.1. 对于 pupil 上均匀分布的相位偏移:
ϕ ( u ) = ϕ 0 ( 常数 ) \phi(u) = \phi_0 \quad (\text{常数})
ϕ ( u ) = ϕ 0 ( 常数 )
光瞳函数变为 P ( u ) = A ( u ) e i ϕ 0 P(u) = A(u) e^{i\phi_0} P ( u ) = A ( u ) e i ϕ 0
U ( x ) = e i ϕ 0 ⋅ F [ A ( u ) ] = e i ϕ 0 ⋅ Airy ( x ) U(x) = e^{i\phi_0} \cdot \mathcal{F}[A(u)] = e^{i\phi_0} \cdot \text{Airy}(x)
U ( x ) = e i ϕ 0 ⋅ F [ A ( u ) ] = e i ϕ 0 ⋅ Airy ( x )
强度:
I ( x ) = ∣ e i ϕ 0 ⋅ Airy ( x ) ∣ 2 = ∣ Airy ( x ) ∣ 2 I(x) = |e^{i\phi_0} \cdot \text{Airy}(x)|^2 = |\text{Airy}(x)|^2
I ( x ) = ∣ e i ϕ 0 ⋅ Airy ( x ) ∣ 2 = ∣ Airy ( x ) ∣ 2
全局 piston(零频)对强度完全没有影响。 这是所有相位恢复系统的基本局限。
5.6.2.2. 当空间频率 n n n
x = n × λ f D = n × 11.0 μ m x = n \times \frac{\lambda f}{D} = n \times 11.0\ \mu\text{m}
x = n × D λ f = n × 1 1 . 0 μ m
频率 n
角谱响应位置 x
与艾里斑半径对比
0.2
2.2 μm
远小于艾里斑半径 13.45 μm
0.5
5.5 μm
小于艾里斑半径
0.8
8.8 μm
小于艾里斑半径
1.0
11.0 μm
接近艾里斑半径
当 n < 1.22 n < 1.22 n < 1 . 2 2 完全淹没在艾里斑内部 (在第一暗环以内),无法作为独立结构被分辨。
但这不意味着低频信息丢失了 。相反,低频信息以另一种方式存在:改变艾里斑的中心形状 。具体来说:
n ≈ 0.2~0.5 (大尺度缓慢起伏):主要改变艾里斑的对称性、峰值位置和能量集中度。这些变化在图像中心区域(约 ±20 μm 内)非常显著。n → 0 (趋近于 piston):响应趋于零,因为任何常数相位偏移都不影响强度。
频率 n n n
偏移距离 x = n × 11.0 x = n \times 11.0 x = n × 1 1 . 0
与中心艾里斑的重叠
灵敏度
n ≈ 0 n \approx 0 n ≈ 0 ≈ 0 \approx 0 ≈ 0 完全重叠
最高
n < 1.22 n < 1.22 n < 1 . 2 2 < r A = 13.45 < r_A = 13.45 < r A = 1 3 . 4 5 大部分重叠(第一暗环内)
高
n ≈ 1.22 n \approx 1.22 n ≈ 1 . 2 2 ≈ r A \approx r_A ≈ r A 刚好擦边(第一暗环)
中等
n ≫ 1.22 n \gg 1.22 n ≫ 1 . 2 2 ≫ r A \gg r_A ≫ r A 几乎不重叠
很低
核心物理 :高频相位模式在 pupil 上变化快,产生的偏移艾里斑跑得很远,和中心艾里斑"搭不上边",所以对 PSF 中心区域的改变很微弱。低频模式产生的偏移很小,几乎全部"埋"在中心艾里斑里面,重叠大,影响也大。
5.6.2.2.1.
低频(n < 1.22 n < 1.22 n < 1 . 2 2 :灵敏度很高(艾里斑重叠大),但信息以「中心形状改变」的形式存在,而非「可分离的角谱响应」。中频(1.22 < n < 5 1.22 < n < 5 1 . 2 2 < n < 5 :角谱响应开始与中心分离,灵敏度下降,但仍可探测。高频(n > 5 n > 5 n > 5 :角谱响应完全分离,每个频率产生独立的焦平面结构,但单个响应强度较弱。
5.6.3. 综合以上分析, PSF 系统对不同频率的波前成分的探测能力可以总结为:
频率区间
探测机制
灵敏度
备注
n = 0 (piston)无
0 严格不可探测
0 < n < 0.5 改变艾里斑中心形状
高
大尺度起伏,容易探测
0.5 < n < 1.22 艾里斑内部变形
中高
角谱响应仍埋在艾里斑内
1.22 < n < 5 角谱响应开始分离
中
Hartmann 极限在此
5 < n < 15 独立角谱响应
中低
信息丰富但响应较弱
15 < n < 81.6 远场角谱响应
低
能量弱,需高信噪比
n > 81.6 跑出探测器
0 完全不可探测
5.6.4.
指标
Hartmann 10×10
PSF 双平面
最高频率
5 cycles/pupil
81.6 cycles/pupil
频率分辨率
~1 cycles/pupil(受子孔径数限制)
~0.41 cycles/pupil
零频响应
不可探测
不可探测
低频灵敏度(n < 1)
低(只能测平均斜率)
高(改变中心形状)
PSF 系统在频率分辨率和动态范围上全面优于 Hartmann。 但它的问题是:低频信息以「变形」而非「独立角谱响应」的形式存在,需要更精细的算法来提取。
5.7. 5.7.1. 从单幅 ∣ U ( x ) ∣ 2 |U(\mathbf{x})|^2 ∣ U ( x ) ∣ 2 ∣ P ^ ( k ) ∣ 2 |\hat{P}(\mathbf{k})|^2 ∣ P ^ ( k ) ∣ 2
孪生像问题 :正负频率无法区分艾里环零点问题 :某些 pupil 频率对应的线性灵敏度恰好为零
所以单幅图不能 完美恢复波前。
5.7.2. 离焦在光瞳上引入已知的二次相位:
ϕ d e f o c u s ( u , v ) = 2 π λ W 20 u 2 + v 2 ( D / 2 ) 2 \phi_{defocus}(u,v) = \frac{2\pi}{\lambda} W_{20} \frac{u^2 + v^2}{(D/2)^2}
ϕ d e f o c u s ( u , v ) = λ 2 π W 2 0 ( D / 2 ) 2 u 2 + v 2
这使得:
焦面上灵敏度为零的频率,在离焦面上可能灵敏度最大
两幅图互补,消除了相位歧义
根据相位多样性理论(Gonsalves 1982; Paxman & Fienup 1988):
适当离焦的双平面强度测量,在理论上可以唯一恢复光瞳上的波前相位。
因此,81.6 cycles/pupil 是双平面PSF系统理论上能够完整恢复的最高波前空间频率。
5.8.
方法
效果
系统怎么改?
增大探测器像素数 N N N n m a x ∝ N n_{max} \propto N n m a x ∝ N 换 800×800 面阵CCD → 上限翻倍到 163.2
增大像素尺寸 p p p n m a x ∝ p n_{max} \propto p n m a x ∝ p 换更大像素,或降低系统放大率
减小焦距 f f f n m a x ∝ 1 / f n_{max} \propto 1/f n m a x ∝ 1 / f 改光路设计,缩短焦距
增大光瞳直径 D D D n m a x ∝ D n_{max} \propto D n m a x ∝ D 受Hartmann光路约束,可能动不了
缩短波长 λ \lambda λ n m a x ∝ 1 / λ n_{max} \propto 1/\lambda n m a x ∝ 1 / λ 换更短波长光源
例如,换用 800×800 像素探测器(其他不变):
n m a x n e w = 81.6 × 800 400 = 163.2 cycles/pupil n_{max}^{new} = 81.6 \times \frac{800}{400} = \mathbf{163.2\ \text{cycles/pupil}}
n m a x n e w = 8 1 . 6 × 4 0 0 8 0 0 = 1 6 3 . 2 cycles/pupil
5.9. 前面分析的是 PSF 光路理论上 能探测到的最高频率(81.6 cycles/pupil)。但在实际仿真流程中,波前信息来自 10×10 哈特曼传感器测得的 63 项 Zernike 系数 。这套输入存在几个根本性的信息损失。
5.9.1. 核心矛盾 :
PSF 理论上能感知到 81.6 cycles/pupil
哈特曼 10×10 的奈奎斯特极限只有 5 cycles/pupil
这意味着:PSF 探测器能感知的中高频信息(5 ~ 81.6 cycles/pupil),哈特曼完全没有测量到。
频率区间
Hartmann 能否探测
PSF 能否探测
仿真是否包含
0 ~ 5 cycles/pupil
✅ 可以
✅ 可以
✅ Zernike 覆盖
5 ~ 15 cycles/pupil
❌ 不能
✅ 高度敏感
❌ 丢失
15 ~ 25 cycles/pupil
❌ 不能
✅ 可探测(翼部)
❌ 丢失
25 ~ 81.6 cycles/pupil
❌ 不能
✅ 可探测(弱角谱响应)
❌ 丢失
> 81.6 cycles/pupil
❌ 不能
❌ 跑出探测器
—
5.9.1.1. 根据角谱法 x = n ⋅ λ f / D x = n \cdot \lambda f / D x = n ⋅ λ f / D n n n
λ f D = 530 × 1 0 − 9 × 1.248 0.06 ≈ 11.02 μ m ≈ 2.45 p i x e l s \frac{\lambda f}{D} = \frac{530\times 10^{-9} \times 1.248}{0.06} \approx \mathbf{11.02\ \mu m \approx 2.45\ pixels}
D λ f = 0 . 0 6 5 3 0 × 1 0 − 9 × 1 . 2 4 8 ≈ 1 1 . 0 2 μ m ≈ 2 . 4 5 p i x e l s
Pupil 频率 n n n
焦平面位置 x x x
像素坐标
1
±11.0 μm
±2.4 pix
2
±22.0 μm
±4.9 pix
3
±33.1 μm
±7.3 pix
4
±44.1 μm
±9.8 pix
5(Hartmann 极限) ±55.1 μm ±12.2 pix
10
±110.2 μm
±24.5 pix
15
±165.4 μm
±36.7 pix
20
±220.5 μm
±49.0 pix
25
±275.6 μm
±61.2 pix
40
±441.0 μm
±98.0 pix
81.6(PSF 极限)
±899.6 μm
±199.9 pix
这意味着什么?
中心 0 ~ ±12 像素区域 :主要由 0~5 cycles/pupil 决定 → Hartmann + Zernike 可以描述 12 ~ 37 像素区域(第一环到第二环之间) :主要由 5~15 cycles/pupil 决定 → Hartmann 完全丢失,需要 HF 层补充 37 ~ 61 像素区域 :主要由 15~25 cycles/pupil 决定 → Hartmann 丢失 61 ~ 200 像素区域(翼部和外围) :主要由 25~81.6 cycles/pupil 决定 → Hartmann 丢失
后果 :仿真波前只有低频骨架,没有中高频"纹理"。即使后续叠加离焦,焦平面上也缺少真实系统应有的精细结构——尤其是距离中心 12 像素以外的区域,仿真和真实数据会有系统性偏差 。
5.9.2. 哈特曼每个子孔径尺寸为:
d s u b = D 10 = 60 mm 10 = 6 m m d_{sub} = \frac{D}{10} = \frac{60\ \text{mm}}{10} = \mathbf{6\ mm}
d s u b = 1 0 D = 1 0 6 0 mm = 6 m m
每个子孔径只输出一个平均斜率 。子孔径内部任何小于 6 mm 周期的波前起伏——比如局部凹陷、涟漪、边缘扰动——全部被抹平成单一数值。
物理图像 :哈特曼就像用 10×10 的「马赛克」去看波面,每个马赛克块内部细节全黑。
5.9.3. Zernike 多项式是定义在单位圆域 上的正交多项式,它有几个隐含假设:
圆域截断 :波前必须在 pupil 边界外严格为零。真实系统中,光瞳边缘可能存在衍射、渐晕、边界散射,Zernike 无法描述这些边界效应。
平滑性假设 :Zernike 是多项式,无限可微。真实波前可能包含局部奇点、划痕、灰尘颗粒引起的不连续相位跳变,多项式无法精确拟合。
基函数形状固定 :Zernike 的径向和角向模式形状是固定的(圆形、环状、扇形等)。真实光学系统的波前扰动频谱特性(比如 Kolmogorov 湍流谱)与 Zernike 基函数不匹配,用有限阶 Zernike 去逼近会产生频谱泄漏 ——高阶 Zernike 项被迫去「硬凑」高频能量,但这些高阶项在 10×10 采样下又测不准。
5.9.4. 哈特曼 10×10 采样,奈奎斯特极限 5 cycles/pupil。如果真实波前包含高于 5 cycles/pupil 的成分,这些高频会**混叠(alias)**到低频区域:
一个 7 cycles/pupil 的真实波前,在 10 点采样下,可能被误判为 3 cycles/pupil 的虚假低频信号。
这意味着:输入的 63 项 Zernike 系数中,某些「低频」成分可能并不是真实的低频,而是高频混叠后的伪影 。仿真用这些被污染的 Zernike 去生成 PSF,必然与真实 PSF 存在系统性偏差。
5.9.5. 5.9.5.1. 训练流程 optimize_the_optical_param_by_PSF.py 本质上在做端到端学习 :
绕过 Hartmann 的采样限制,直接用真实 PSF 图像来「监督」仿真,让网络同时优化物理参数和 Zernike 无法描述的那部分波前。
HighFrequencyPhaseLayer 是这个框架中的关键组件——它在 Zernike 波前基础上叠加一个由 Zernike 系数预测的高频相位屏 ,专门学习 5 ~ 15(或更高)cycles/pupil 的中频区。
当前问题 :代码里 min_freq=0, max_freq=45 在 51×51 网格上等价于全频域,既覆盖了目标高频,也侵入了 Zernike 负责的低频区建议修正 :min_freq=5, max_freq=15(或根据网格增大后相应提高)
此外,focus_defocus_um、defocus_coefficient_um、spatial_scale 等可学习物理参数,也在协同补偿 Hartmann-Zernike 信息缺失。
5.9.5.2. 51×51 网格的可靠表示上限约 12 cycles/pupil(4 点/周期准则),与 PSF 理论极限 81.6 严重不匹配。
网格尺寸
可靠上限(4点/周期)
奈奎斯特极限
是否匹配 81.6?
51×51
~12
25.5
❌ 差很远
128×128
~32
64
❌ 不够
256×256
~64
128
⚠️ 勉强
512×512
~128
256
✅ 足够
建议 :若计算资源允许,将仿真网格从 51×51 提升到 256×256 或 512×512 ,让 HighFrequencyPhaseLayer 的频谱设置(如 max_freq=80)有物理意义。
5.9.5.3.
子孔径数
奈奎斯特极限
子孔径尺寸
提升效果
10×10
5
6 mm
现状
20×20
10
3 mm
中频覆盖翻倍
40×40
20
1.5 mm
显著提升
代价:硬件改造、光学重新对准、成本增加。
6. 6.1. 6.1.1. 在光学成像系统中,我们考虑一个理想的衍射受限系统(或带有像差的系统):
光瞳掩模 M ( x , y ) M(x,y) M ( x , y ) 1 1 1 0 0 0
对于圆形光瞳,M ( x , y ) = { 1 , x 2 + y 2 ≤ R 2 0 , otherwise M(x,y) = \begin{cases} 1, & x^2+y^2 \leq R^2 \\ 0, & \text{otherwise} \end{cases} M ( x , y ) = { 1 , 0 , x 2 + y 2 ≤ R 2 otherwise
波前(像差) W ( x , y ) W(x,y) W ( x , y ) B B B λ \lambda λ 点扩散函数(PSF) I ( u , v ) I(u,v) I ( u , v )
6.1.2. 光瞳平面上的复振幅透过率函数 (简称光瞳函数)定义为:
P ( x , y ) = M ( x , y ) ⋅ e i k W ( x , y ) \boxed{P(x,y) = M(x,y) \cdot e^{i k W(x,y)}}
P ( x , y ) = M ( x , y ) ⋅ e i k W ( x , y )
其中:
k = 2 π λ k = \frac{2\pi}{\lambda} k = λ 2 π M ( x , y ) M(x,y) M ( x , y ) 0 0 0 1 1 1 e i k W ( x , y ) e^{i k W(x,y)} e i k W ( x , y )
注意 :波前 W ( x , y ) W(x,y) W ( x , y )
6.2. 6.2.1. 根据标量衍射理论 和夫琅禾费近似 ,像平面(焦平面)上的复振幅分布 U ( u , v ) U(u,v) U ( u , v ) P ( x , y ) P(x,y) P ( x , y )
U ( u , v ) = F { P ( x , y ) } = ∬ − ∞ + ∞ P ( x , y ) e − i 2 π ( x u + y v ) d x d y U(u,v) = \mathcal{F}\{P(x,y)\} = \iint_{-\infty}^{+\infty} P(x,y) \, e^{-i 2\pi (xu + yv)} \, dx \, dy
U ( u , v ) = F { P ( x , y ) } = ∬ − ∞ + ∞ P ( x , y ) e − i 2 π ( x u + y v ) d x d y
像平面上的强度分布 (即 PSF)为:
I ( u , v ) = ∣ U ( u , v ) ∣ 2 = U ( u , v ) ⋅ U ∗ ( u , v ) I(u,v) = |U(u,v)|^2 = U(u,v) \cdot U^*(u,v)
I ( u , v ) = ∣ U ( u , v ) ∣ 2 = U ( u , v ) ⋅ U ∗ ( u , v )
6.2.2. PSF 的总能量 (或总强度)定义为对整个像平面积分:
E PSF = ∬ − ∞ + ∞ I ( u , v ) d u d v = ∬ − ∞ + ∞ ∣ U ( u , v ) ∣ 2 d u d v E_{\text{PSF}} = \iint_{-\infty}^{+\infty} I(u,v) \, du \, dv = \iint_{-\infty}^{+\infty} |U(u,v)|^2 \, du \, dv
E PSF = ∬ − ∞ + ∞ I ( u , v ) d u d v = ∬ − ∞ + ∞ ∣ U ( u , v ) ∣ 2 d u d v
6.2.3. 傅里叶变换满足著名的帕塞瓦尔能量守恒定理 :
对于任意平方可积函数 f ( x , y ) f(x,y) f ( x , y ) F ( u , v ) = F { f ( x , y ) } F(u,v) = \mathcal{F}\{f(x,y)\} F ( u , v ) = F { f ( x , y ) }
∬ ∣ F ( u , v ) ∣ 2 d u d v = ∬ ∣ f ( x , y ) ∣ 2 d x d y \iint |F(u,v)|^2 \, du \, dv = \iint |f(x,y)|^2 \, dx \, dy
∬ ∣ F ( u , v ) ∣ 2 d u d v = ∬ ∣ f ( x , y ) ∣ 2 d x d y
将 P ( x , y ) P(x,y) P ( x , y ) f ( x , y ) f(x,y) f ( x , y ) U ( u , v ) U(u,v) U ( u , v ) F ( u , v ) F(u,v) F ( u , v )
E PSF = ∬ ∣ U ( u , v ) ∣ 2 d u d v = ∬ ∣ P ( x , y ) ∣ 2 d x d y E_{\text{PSF}} = \iint |U(u,v)|^2 \, du \, dv = \iint |P(x,y)|^2 \, dx \, dy
E PSF = ∬ ∣ U ( u , v ) ∣ 2 d u d v = ∬ ∣ P ( x , y ) ∣ 2 d x d y
6.2.4. ∣ P ( x , y ) ∣ 2 |P(x,y)|^2 ∣ P ( x , y ) ∣ 2 由于 P ( x , y ) = M ( x , y ) ⋅ e i k W ( x , y ) P(x,y) = M(x,y) \cdot e^{i k W(x,y)} P ( x , y ) = M ( x , y ) ⋅ e i k W ( x , y )
∣ P ( x , y ) ∣ 2 = P ( x , y ) ⋅ P ∗ ( x , y ) = M ( x , y ) ⋅ e i k W ( x , y ) ⋅ M ( x , y ) ⋅ e − i k W ( x , y ) |P(x,y)|^2 = P(x,y) \cdot P^*(x,y) = M(x,y) \cdot e^{i k W(x,y)} \cdot M(x,y) \cdot e^{-i k W(x,y)}
∣ P ( x , y ) ∣ 2 = P ( x , y ) ⋅ P ∗ ( x , y ) = M ( x , y ) ⋅ e i k W ( x , y ) ⋅ M ( x , y ) ⋅ e − i k W ( x , y )
由于 M ( x , y ) M(x,y) M ( x , y ) 0 0 0 1 1 1 M ∗ = M M^* = M M ∗ = M
∣ P ( x , y ) ∣ 2 = M 2 ( x , y ) ⋅ e i k W ⋅ e − i k W ⏟ = 1 = M 2 ( x , y ) = M ( x , y ) |P(x,y)|^2 = M^2(x,y) \cdot \underbrace{e^{i k W} \cdot e^{-i k W}}_{=1} = M^2(x,y) = M(x,y)
∣ P ( x , y ) ∣ 2 = M 2 ( x , y ) ⋅ = 1 e i k W ⋅ e − i k W = M 2 ( x , y ) = M ( x , y )
关键观察:相位项 e i k W ( x , y ) e^{i k W(x,y)} e i k W ( x , y ) 1 1 1 ∣ P ∣ 2 |P|^2 ∣ P ∣ 2
6.2.5. 代入得:
E PSF = ∬ M ( x , y ) d x d y = A pupil \boxed{E_{\text{PSF}} = \iint M(x,y) \, dx \, dy = A_{\text{pupil}}}
E PSF = ∬ M ( x , y ) d x d y = A pupil
其中 A pupil A_{\text{pupil}} A pupil 几何面积 。
对于圆形光瞳 :
E PSF = π R 2 E_{\text{PSF}} = \pi R^2
E PSF = π R 2
其中 R R R
6.3. 在实际仿真中,我们使用离散傅里叶变换(DFT/FFT)在有限网格上计算 PSF。
6.3.1. 设:
光瞳平面采样为 N × N N \times N N × N Δ x = Δ y = d \Delta x = \Delta y = d Δ x = Δ y = d
离散光瞳函数:P m , n = M m , n ⋅ e i k W m , n P_{m,n} = M_{m,n} \cdot e^{i k W_{m,n}} P m , n = M m , n ⋅ e i k W m , n m , n = 0 , 1 , … , N − 1 m,n = 0,1,\dots,N-1 m , n = 0 , 1 , … , N − 1
离散光瞳掩模:M m , n ∈ { 0 , 1 } M_{m,n} \in \{0, 1\} M m , n ∈ { 0 , 1 }
6.3.2. 像平面复振幅(DFT):
U k , l = ∑ m = 0 N − 1 ∑ n = 0 N − 1 P m , n ⋅ e − i 2 π N ( m k + n l ) U_{k,l} = \sum_{m=0}^{N-1} \sum_{n=0}^{N-1} P_{m,n} \cdot e^{-i \frac{2\pi}{N}(mk + nl)}
U k , l = m = 0 ∑ N − 1 n = 0 ∑ N − 1 P m , n ⋅ e − i N 2 π ( m k + n l )
PSF 强度:
I k , l = ∣ U k , l ∣ 2 I_{k,l} = |U_{k,l}|^2
I k , l = ∣ U k , l ∣ 2
6.3.3. 二维 DFT 满足离散帕塞瓦尔定理 :
∑ k = 0 N − 1 ∑ l = 0 N − 1 ∣ U k , l ∣ 2 = N 2 ∑ m = 0 N − 1 ∑ n = 0 N − 1 ∣ P m , n ∣ 2 \sum_{k=0}^{N-1} \sum_{l=0}^{N-1} |U_{k,l}|^2 = N^2 \sum_{m=0}^{N-1} \sum_{n=0}^{N-1} |P_{m,n}|^2
k = 0 ∑ N − 1 l = 0 ∑ N − 1 ∣ U k , l ∣ 2 = N 2 m = 0 ∑ N − 1 n = 0 ∑ N − 1 ∣ P m , n ∣ 2
归一化说明 :上式对应 numpy.fft.fft2 的默认定义(正变换无 1 / N 1/N 1 / N fftshift、ifft2 等其他归一化约定,比例常数会变化,但比例关系不变 。
6.3.4. ∣ P m , n ∣ 2 |P_{m,n}|^2 ∣ P m , n ∣ 2 同理:
∣ P m , n ∣ 2 = ∣ M m , n ∣ 2 ⋅ ∣ e i k W m , n ∣ 2 = M m , n 2 ⋅ 1 = M m , n |P_{m,n}|^2 = |M_{m,n}|^2 \cdot |e^{i k W_{m,n}}|^2 = M_{m,n}^2 \cdot 1 = M_{m,n}
∣ P m , n ∣ 2 = ∣ M m , n ∣ 2 ⋅ ∣ e i k W m , n ∣ 2 = M m , n 2 ⋅ 1 = M m , n
因为 M m , n ∈ { 0 , 1 } M_{m,n} \in \{0,1\} M m , n ∈ { 0 , 1 } M m , n 2 = M m , n M_{m,n}^2 = M_{m,n} M m , n 2 = M m , n
6.3.5. 设 N M N_M N M 1 1 1
N M = ∑ m = 0 N − 1 ∑ n = 0 N − 1 M m , n N_M = \sum_{m=0}^{N-1} \sum_{n=0}^{N-1} M_{m,n}
N M = m = 0 ∑ N − 1 n = 0 ∑ N − 1 M m , n
则:
∑ k , l ∣ U k , l ∣ 2 = N 2 ∑ m , n M m , n = N 2 ⋅ N M \sum_{k,l} |U_{k,l}|^2 = N^2 \sum_{m,n} M_{m,n} = N^2 \cdot N_M
k , l ∑ ∣ U k , l ∣ 2 = N 2 m , n ∑ M m , n = N 2 ⋅ N M
因此 PSF 总能量(像素强度之和)为:
E PSF, discrete = ∑ k = 0 N − 1 ∑ l = 0 N − 1 I k , l = N 2 ⋅ N M \boxed{E_{\text{PSF, discrete}} = \sum_{k=0}^{N-1} \sum_{l=0}^{N-1} I_{k,l} = N^2 \cdot N_M}
E PSF, discrete = k = 0 ∑ N − 1 l = 0 ∑ N − 1 I k , l = N 2 ⋅ N M
在仿真中,如果你固定网格大小 N N N M M M W m , n W_{m,n} W m , n PSF.sum() 恒等于 N 2 ⋅ N M N^2 \cdot N_M N 2 ⋅ N M
若考虑实际的物理单位(像素面积 Δ u ⋅ Δ v \Delta u \cdot \Delta v Δ u ⋅ Δ v
6.4. 6.4.1.
光瞳掩模 M M M 决定了有多少光 能通过系统,它是能量的"源头"。波前 W W W (相位)只是决定了这些光在像平面上如何干涉、如何重新分布 。
可以把光瞳想象成一个房间里的多盏灯:
M M M W W W
无论这些灯如何干涉,总功率不变 ,只是有的地方更亮、有的地方更暗。
6.4.2.
理想平面波 (W = 0 W=0 W = 0 离焦/像差 (W ≠ 0 W \neq 0 W = 0 随机相位 (强像差):PSF 变成散斑图样,能量极度分散。
但在以上所有情况下,对全像平面求和,总能量完全相同 。
6.5. 6.5.1. 如果 M ( x , y ) M(x,y) M ( x , y ) 0 < M < 1 0 < M < 1 0 < M < 1
E PSF = ∬ ∣ M ( x , y ) ∣ 2 d x d y E_{\text{PSF}} = \iint |M(x,y)|^2 \, dx \, dy
E PSF = ∬ ∣ M ( x , y ) ∣ 2 d x d y
只是此时 ∣ P ∣ 2 = ∣ M ∣ 2 |P|^2 = |M|^2 ∣ P ∣ 2 = ∣ M ∣ 2 M M M
6.5.2. 如果光瞳内存在非均匀的振幅衰减 A ( x , y ) A(x,y) A ( x , y )
P ( x , y ) = A ( x , y ) ⋅ M ( x , y ) ⋅ e i k W ( x , y ) P(x,y) = A(x,y) \cdot M(x,y) \cdot e^{i k W(x,y)}
P ( x , y ) = A ( x , y ) ⋅ M ( x , y ) ⋅ e i k W ( x , y )
此时:
∣ P ∣ 2 = ∣ A ∣ 2 ⋅ M |P|^2 = |A|^2 \cdot M
∣ P ∣ 2 = ∣ A ∣ 2 ⋅ M
总能量取决于 ∣ A ∣ 2 |A|^2 ∣ A ∣ 2 仍然与相位 W W W 。
6.5.3. 如果你在实际仿真中发现改变波前后 PSF.sum() 变化了,请检查:
可能原因
排查方法
PSF 被截断 增大计算网格 N N N
FFT 频谱泄漏 确保光瞳边缘在网格内清晰采样,避免混叠
归一化不一致 不同参数下使用了不同的常数因子乘在 PSF 上
数值下溢/上溢 检查是否有 float32 溢出,建议用 float64
光瞳定义变化 确认 M M M
6.6.
问题
答案
PSF 总能量由什么决定?
仅由光瞳掩模 M M M
波前 W W W
不影响 。无论 W W W
连续域表达式
E = ∬ M ( x , y ) d x d y = A pupil E = \displaystyle\iint M(x,y) \, dx \, dy = A_{\text{pupil}} E = ∬ M ( x , y ) d x d y = A pupil
离散域表达式
E = N 2 ∑ m , n M m , n E = N^2 \displaystyle\sum_{m,n} M_{m,n} E = N 2 m , n ∑ M m , n
物理本质
相位只重新分配能量空间分布,不改变总能量
6.7. 6.7.1. 为验证理论推导在实际采集数据中的适用性,我们从 dataset_split_txts/test.txt 中随机抽取了 2000 个样本 (先 Shuffle 再随机挑选,确保像差分布均匀)。
数据来源 :光学系统实测采集的 NPZ 文件(image + zernike)曝光条件 :采集期间曝光时间严格固定(WFS=500, PD1/PD2/PD3=50)能量计算 :直接读取 npz 原始数据,不经过 dataset.py 中的背景扣除和归一化预处理 ,分别计算:
在焦能量:E in = ∑ image [ : , : , 0 ] E_{\text{in}} = \sum \text{image}[:,:,0] E in = ∑ image [ : , : , 0 ]
离焦能量:E def = ∑ image [ : , : , 1 ] E_{\text{def}} = \sum \text{image}[:,:,1] E def = ∑ image [ : , : , 1 ]
总能量:E tot = E in + E def E_{\text{tot}} = E_{\text{in}} + E_{\text{def}} E tot = E in + E def
像差度量 :Zernike 多项式系数的 RMS 值
6.7.2.
注 :我们对 test.txt 中的 全部 39960 个样本 进行了扫描确认。该数据集的 63 维 Zernike 已经去除了 piston 和 tilt,全部为有效像差模式。
波前 RMS 计算 :对于正交归一的 Zernike 多项式,波前 RMS = ∑ i Z i 2 \sqrt{\sum_i Z_i^2} ∑ i Z i 2
统计量
波前 RMS sqrt(∑Z²)波前峰谷值 P-V
最大单项系数 max|Z_i|
最小值
0.0211
0.0136
0.0073
最大值
0.9255 0.8202 0.6239
均值
0.4295
0.3601
0.2776
P90
0.8898
—
—
P95
0.9093
—
—
P99
0.9199
—
—
6.7.3.
指标
在焦能量
离焦能量
总能量
均值 4793.56
4813.41
9606.97
标准差 4.80
2.19
5.62
变异系数 (CV) 0.10% 0.05% 0.06%
变异系数(CV = std/mean)是衡量相对波动性的关键指标。 总能量的 CV 仅为 0.06% ,说明在 2000 个不同像差样本中,总能量几乎恒定不变。
6.7.4.
能量类型
与波前 RMS sqrt(∑Z²) 的 Pearson 相关系数
在焦能量
+0.2184(弱正相关)
离焦能量
-0.8639 (强负相关)
总能量 -0.1501 (弱负相关,接近无关)
解读 :
离焦能量随像差增大而显著下降(能量从离焦面扩散/转移)。
但在焦能量有微弱上升,两者相互补偿 。
总能量与像差几乎无关 (r = − 0.15 r = -0.15 r = − 0 . 1 5
6.7.5.
像差等级
样本数
总能量均值
总能量标准差
CV
低像差(≤ \leq ≤
500
9604.21
7.97
0.08%
中像差(P25 ~ P75)
1000
9610.13
2.94
0.03%
高像差(≥ \geq ≥
500
9603.40
2.29
0.02%
高 vs 低相对差异 —
-0.008% —
—
在 test.txt 实际像差范围内(波前 RMS 从 0.02λ 到 0.93λ,动态范围约 43 倍 ),总能量变化不到 0.01% 。
6.7.6. 6.7.6.1.
左图:在焦能量随像差略有上升(r = 0.22 r=0.22 r = 0 . 2 2
中图:离焦能量随像差显著下降(r = − 0.86 r=-0.86 r = − 0 . 8 6
右图 :总能量基本水平,无系统性趋势(r = − 0.15 r=-0.15 r = − 0 . 1 5
6.7.6.2.
左图:总能量 vs 波前峰谷值 P-V(r = − 0.16 r = -0.16 r = − 0 . 1 6
右图:总能量 vs 最大单项系数(r = − 0.16 r = -0.16 r = − 0 . 1 6
两种辅助度量下,总能量均无系统性趋势。
6.7.6.3. 总能量呈极窄的分布,均值 9606.97,半高宽极小。
6.7.6.4. 低、中、高像差三组的能量中位数几乎重合,箱线高度差异极小。
6.7.7.
理论预测
实测结果
一致性
光瞳不变时,PSF 总能量与波前(像差)无关
2000 个样本,总能量 CV = 0.06%,与波前 RMS 相关系数仅 -0.15
✅ 完全符合
相位只改变能量空间分布
在焦能量↑,离焦能量↓,两者补偿
✅ 完全符合
曝光时间固定保证入射光量恒定
总能量在不同像差下差异 < 0.01%
✅ 得到验证
6.7.8. 理论上说,总能量应该与像差严格无关 (相关系数为 0)。但实测中我们发现:
在焦能量 随像差增大有微弱上升(r = + 0.22 r = +0.22 r = + 0 . 2 2 离焦能量 随像差增大显著下降(r = − 0.86 r = -0.86 r = − 0 . 8 6 两者相互补偿,使总能量保持恒定
这种"补偿"并非理论上的能量转移,而更可能是相机探测非线性 导致的测量效应:
6.7.8.1. 当像差很小时,PSF 能量高度集中在焦平面中心。如果中心像素的光强超过了相机的满阱容量(full well capacity),就会发生饱和/过曝 。过曝区域的像素值被截断在最大值(如 4095 for 12-bit),导致:
在焦图像测得的能量偏低 (真实的中心能量被截断了)随着像差增大,能量扩散,中心不再过曝,测得的在焦能量反而"回升"
这与我们观察到的"在焦能量随像差增大而上升"的趋势一致。
6.7.8.2. 当像差很大时,PSF 能量被严重稀释到更大的空间范围内,单位面积的光强显著下降。此时:
信号可能接近甚至低于相机的读出噪声 + 暗电流噪声 基线
即使做了背景扣除,弱信号区域的信噪比(SNR)仍然很低
离焦图像的能量更容易被噪声"吞没" ,导致测得的离焦能量偏低
这与我们观察到的"离焦能量随像差增大而显著下降"(r = − 0.86 r = -0.86 r = − 0 . 8 6
6.7.8.3.
像差大小
在焦通道
离焦通道
对总能量的影响
小像差 中心过曝 → 测得能量偏低
能量集中 → 测得正常
两者部分抵消
大像差 能量扩散 → 过曝消失,测得能量回升
能量极度扩散 → 被噪声淹没,测得能量偏低
两者再次抵消
这解释了为什么总能量能保持如此惊人的稳定(CV = 0.06%):不是物理上能量在在焦/离焦之间完美转移,而是两种非线性效应(过曝截断 vs 噪声淹没)恰好相互补偿了。
如果要更严格地验证理论,需要确保:
无过曝 :像差小时使用更短曝光或衰减片,避免中心饱和无噪声淹没 :像差大时延长曝光或提高增益,确保弱信号高于噪声基线或者使用具有更高动态范围(HDR)的探测器
光瞳是"量",波前是"形"。光瞳决定有多少光,波前决定光长什么样。只要光瞳不变,点扩散的总能量就永恒不变。
7. 7.1. 7.1.1. 哈特曼波前传感器(Hartmann WFS)是 10×10 的子孔径网格。我们先从一维理解:
在光瞳直径上,有 N_H = 10 个采样点(子孔径中心)
根据奈奎斯特采样定理,能无混叠地重建的最高空间频率为:
f N y q u i s t H a r t m a n n = N H 2 = 5 cycles/pupil f_{Nyquist}^{Hartmann} = \frac{N_H}{2} = 5 \text{ cycles/pupil}
f N y q u i s t H a r t m a n n = 2 N H = 5 cycles/pupil
这意味着:
频率 ≤ 5 c/pupil 的波前变化 → 哈特曼可以 分辨频率 > 5 c/pupil 的波前变化 → 哈特曼无法 分辨(混叠或丢失)
7.1.2. 1 2 3 4 5 6 7 8 9 光瞳(-1 ~ +1,归一化坐标) |----|----|----|----|----|----|----|----|----|----| s1 s2 s3 s4 s5 s6 s7 s8 s9 s10 ← 10个子孔径中心采样点 → 波前分量: 3 c/pupil (低频) : ~~~~ (哈特曼可以采) 8 c/pupil (中频) : ~~~~~~~~ (哈特曼混叠) 15 c/pupil (高频) : ~~~~~~~~~~~~~~~~ (完全丢失)
7.1.3. 在 51×51 的像素网格上做 FFT 时,频率与 FFT 索引的关系:
Centered 格式(零频在中间,可视化常用):
f ( k ) = k − 25 (cycles/pupil) f(k) = k - 25 \quad \text{(cycles/pupil)}
f ( k ) = k − 2 5 (cycles/pupil)
k = 20(距中心 5)→ 频率 = 5 c/pupil (哈特曼奈奎斯特极限)k = 15(距中心 10)→ 频率 = 10 c/pupil (SHFP中频目标)k = 10(距中心 15)→ 频率 = 15 c/pupil (SHFP高频上限)k = 0 或 k = 50 → 频率 = ±25 c/pupil (51网格奈奎斯特极限)
重要:必须理解 ifftshift 的作用
torch.fft.ifft2 要求输入频谱的零频在索引 (0,0),这是标准 FFT 格式 :
1 2 3 4 5 标准格式: [0, 1, 2, ..., 25, -25, ..., -2, -1] (实际频率) ↑零频 Centered格式:[ -25, ..., -2, -1, 0, 1, 2, ..., 25] ↑零频在中间
torch.fft.ifftshift 的作用就是将 “零频居中” 的可视化格式转换为 “零频在 (0,0)” 的标准格式。
对于 N=51,中心索引 k=25(距中心 0 像素)对应零频。索引 k=45 距中心 20 像素,但在标准格式中:
ifftshift 后,k=45 的位置会映射到标准格式的 (45 - 25 = 20),即 -6 c/pupil (因为 20 > 25.5,实际频率 = 20 - 51 = -6)不加 ifftshift,ifft2 会把 k=45 当成 +45 c/pupil (远超奈奎斯特极限),输出像素噪声
7.1.4.
区域
频率范围 (c/pupil)
Centered格式索引
物理意义
SHFP作用
低频
0 ~ 5
k = 20~30
哈特曼+Zernike已覆盖
不学
中频
5 ~ 15
k = 10~20, 30~40
哈特曼丢失,Zernike弱覆盖
主要学习目标
高频
15 ~ 25
k = 0~10, 40~50
接近网格奈奎斯特,信噪比差
谨慎学习
7.2. 7.2.1.
过曝的物理本质 :
大像差样本的灰圈/光晕是子孔径尺度 的动态效应
子孔径大小约 5 像素(51/10 ≈ 5.1),子孔径内的 1~2 个周期的相位变化对应全光瞳上的 5~10 c/pupil
这正是哈特曼完全丢失、Zernike 基函数难以精细表达的区域
为什么不学 >15 c/pupil?
51 网格的奈奎斯特是 25 c/pupil,但 15~25 区域已经接近像素极限
高频分量能量通常很小,且容易过拟合噪声
实验观察到的光晕展宽主要由中频分量(5~15)贡献
7.2.2.
Zernike 63 项(到第 10~11 径向阶)已经能很好地表示 0~5 c/pupil 的波前
SHFP 如果学习低频,会与 Zernike 发生参数冲突 (competing gradients)
之前的方形实现 n_freq=12 覆盖了 0~6 c/pupil,导致与 Zernike 重叠
改进后的环形实现只覆盖 5~15 c/pupil,与 Zernike 互补
7.3. 7.3.1. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 Centered 频谱(51×51,中心区域示意,距离按欧氏距离 √u²+v² 计算): v ↑ | ...RRRRRRRRRRRRRRRRRRR... | ..RRRRRRRRRRRRRRRRRRRRR.. | .RRRRRRRRRRRRRRRRRRRRRRR. | RRRRRRRRRRRRRRRRRRRRRRRRR | RRRRRRRRRRRRRRRRRRRRRRRRR | RRRRRRRRRRRRRRRRRRRRRRRRR | RRRRRRRRRRRRRRRRRRRRRRRRR | RRRRRRRRRRRRRRRRRRRRRRRRR | RRRRRRRRRRBBBBBRRRRRRRRRR <- dist=5(哈特曼奈奎斯特边界) | RRRRRRRRRBBBBBBBRRRRRRRRR | RRRRRRRRBBBBBBBBBRRRRRRRR | RRRRRRRRBBBBBBBBBRRRRRRRR 0-| RRRRRRRRBBBBBBBBBRRRRRRRR ←—— 零频 (u=0, v=0) | RRRRRRRRBBBBBBBBBRRRRRRRR | RRRRRRRRBBBBBBBBBRRRRRRRR | RRRRRRRRRBBBBBBBRRRRRRRRR | RRRRRRRRRRBBBBBRRRRRRRRRR | RRRRRRRRRRRRRRRRRRRRRRRRR | RRRRRRRRRRRRRRRRRRRRRRRRR | RRRRRRRRRRRRRRRRRRRRRRRRR | RRRRRRRRRRRRRRRRRRRRRRRRR | RRRRRRRRRRRRRRRRRRRRRRRRR | .RRRRRRRRRRRRRRRRRRRRRRR. | ..RRRRRRRRRRRRRRRRRRRRR.. | ...RRRRRRRRRRRRRRRRRRR... <- dist=15(SHFP高频边界) ←———————————————— u ———————————————→ 图例: B = 低频盲区(圆形,dist<5,Zernike已覆盖,SHFP不学) R = SHFP可学习区域(环形带,5≤dist≤15 c/pupil) . = 高频区(dist>15,接近网格奈奎斯特,不学习)
7.3.2. 在 PyTorch 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 N = 51 center = N // 2 y, x = torch.meshgrid(torch.arange(N), torch.arange(N), indexing='ij' ) dist = torch.sqrt((x - center)**2 + (y - center)**2 ) low_freq_mask = (dist >= 5 ).float () high_freq_mask = (dist <= 15 ).float () shfp_mask = low_freq_mask * high_freq_mask
7.3.3. 在有效环形区域内放置可学习的复数傅里叶系数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class HighFrequencyPhaseLayer (nn.Module ): def __init__ (self, grid_size=51 , min_freq=5 , max_freq=15 ): super ().__init__() self.grid_size = grid_size self.min_freq = min_freq self.max_freq = max_freq y, x = torch.meshgrid( torch.arange(grid_size), torch.arange(grid_size), indexing='ij' ) dist = torch.sqrt((x - grid_size//2 )**2 + (y - grid_size//2 )**2 ) self.register_buffer('ring_mask' , ((dist >= min_freq) & (dist <= max_freq)).float ()) self.amp_real = nn.Parameter( torch.zeros(grid_size, grid_size) * 0.01 ) self.amp_imag = nn.Parameter( torch.zeros(grid_size, grid_size) * 0.01 ) self.intensity_scale = nn.Parameter(torch.tensor(0.05 )) def forward (self, batch_size, device, complexity ): spectrum = torch.complex (self.amp_real, self.amp_imag) spectrum = spectrum * self.ring_mask full_spectrum = torch.fft.ifftshift(spectrum) phase_hf = torch.fft.ifft2(full_spectrum).real phase_hf = phase_hf / (phase_hf.std() + 1e-6 ) scale = torch.sigmoid(self.intensity_scale) * complexity.view(-1 , 1 , 1 ) * 0.1 return phase_hf.unsqueeze(0 ).expand(batch_size, -1 , -1 ) * scale
7.3.4. 1 2 3 4 5 6 7 8 9 10 11 wavefront_rad = zernike_wavefront / wavelength_m * 2 * torch.pi complexity = torch.norm(zernike_um, dim=1 , keepdim=True ) hf_phase = self.hf_phase_layer(batch_size, device, complexity) wavefront_rad = wavefront_rad + hf_phase
7.3.5. 1 2 3 4 5 6 pupil_complex = effective_amp * torch.exp(1j * wavefront_rad) psf_amplitude = torch.fft.fft2(pupil_complex) psf_intensity = torch.fft.fftshift(torch.abs (psf_amplitude)**2 )
7.4. zernike_residual 的互补性模型中已有 zernike_residual(63-D 可学习向量),它与 SHFP 层是否重叠?不重叠,是互补关系。
7.4.1. zernike_residual 的本质1 2 self.zernike_residual = nn.Parameter(torch.zeros(63 , dtype=torch.float32))
使用方式:zernike_um = zernike_um + self.zernike_residual
物理意义 :校正输入 Zernike 系数的全局系统误差 (如哈特曼标定偏差)表示空间 :Zernike 域(63 个系数)→ 通过 zernikePol 映射到 51×51 空间网格与输入关系 :固定偏移 ,所有样本加同一个 63 维向量
7.4.2.
“63 项 Zernike 在 51×51 网格上的频率上限只有 0~5 c/pupil,所以 zernike_residual 只覆盖低频。”
这个说法不对。 Zernike 多项式是连续正交多项式,高阶模式(如 n=10, m=10)在 51 点网格上采样后,空间振荡完全可以达到 10~20 c/pupil 。这些高频不是采样定理意义上的"可分辨频率",而是混叠后在离散网格上呈现的高频内容。
所以 zernike_residual 在空间域上的频率范围不限于 0~5 c/pupil。
7.4.3. zernike_residual 仍然替代不了 SHFP?核心区别在于自由度约束 和输入相关性 :
zernike_residualSHFP 层
自由度
63 个系数
640 个频谱像素
基函数形状
Zernike 多项式(全局、有固定解析形式)
傅里叶正弦/余弦(任意形状)
空间局部性
❌ 全局分布
✅ 可局部可全局
输入相关性
❌ 固定(所有样本相同)
✅ 自适应(大像差→大扰动)
物理约束
受 Zernike 正交性约束
自由(仅频率带限)
关键问题:Zernike 是"结构化"的基。
63 项 Zernike 只能生成 63 维子空间 中的波前。这个子空间包含径向多项式 × 角向三角函数的特定组合,不能 生成任意的子孔径尺度局部扰动。
具体例子 :假设过曝只在左上角第 (2,3) 个子孔径产生了局部相位畸变。Zernike 基函数无法单独"激活"一个子孔径——所有 Zernike 模式都是覆盖整个光瞳的。要用 63 个全局基去拟合一个局部特征,需要大量基函数的组合,且会引入不必要的全局副作用。
而 SHFP 是像素级自由 的。它可以直接在 (2,3) 子孔径位置生成局部扰动,不影响其他区域。
7.4.4. zernike_residual 是否已经吸收了部分过曝效应?有可能。 训练过程中,zernike_residual 会学习到"让平均 PSF 更接近真实"的方向。如果过曝导致的灰圈有一个固定的高频分量 (比如所有大像差样本都有类似的子孔径边缘模糊),zernike_residual 的高阶模式可能会部分吸收它。
但从实验现象看:
多跑 epoch 后模型自发全局加宽(blur_kernel/spatial_scale),大像差改善但小像差过拟合
这说明:
zernike_residual 不够用——如果它足够,模型不需要靠全局 blur 来补偿过曝效应主要是动态 的(大像差时有、小像差时无),不是固定的
全局参数无法区分"大像差需要宽 PSF、小像差不需要"
这正是引入 SHFP 的根本原因:提供一个输入相关 的、局部自由 的自由度。
7.4.5.
问题
答案
zernike_residual 有高频内容吗?✅ 有(高阶 Zernike 在 51 网格上可产生 >5 c/pupil)
它的自由度足够吗?
❌ 不够(只有 63 维,且受 Zernike 形状约束)
它能表示局部子孔径扰动吗?
❌ 不能(Zernike 是全局基)
它是输入相关的吗?
❌ 不是(固定偏移,所有样本相同)
它已经吸收了过曝效应吗?
可能部分吸收了固定的低频/全局分量
SHFP 还有必要吗?
✅ 有必要(处理动态的、局部的、Zernike 表示不了的分量)
8. 哈特曼-夏克(Hartmann-Shack)波前传感器通过子孔径焦斑阵列重构入射波前。传统上,子孔径光斑的质心位移 被用来解算相位斜率,从而重构波前相位 ϕ ( r ) \phi(\mathbf{r}) ϕ ( r ) 亮度差异 直接反映了瞳孔面上波前振幅 A ( r ) A(\mathbf{r}) A ( r )
8.1. 8.1.1. 哈特曼传感器将入射波前分割为 N × M N \times M N × M ( m , n ) (m,n) ( m , n )
h m , n ( ρ ) = ∣ F { P m , n ( r ) A ( r ) e i ϕ ( r ) } ( ρ ) ∣ 2 h_{m,n}(\boldsymbol{\rho}) = \left| \mathcal{F}\{ P_{m,n}(\mathbf{r}) \, A(\mathbf{r}) \, e^{i\phi(\mathbf{r})} \}(\boldsymbol{\rho}) \right|^2
h m , n ( ρ ) = ∣ ∣ ∣ F { P m , n ( r ) A ( r ) e i ϕ ( r ) } ( ρ ) ∣ ∣ ∣ 2
其中 r = ( x , y ) \mathbf{r}=(x,y) r = ( x , y ) ρ = ( u , v ) \boldsymbol{\rho}=(u,v) ρ = ( u , v ) P m , n ( r ) P_{m,n}(\mathbf{r}) P m , n ( r ) A ( r ) A(\mathbf{r}) A ( r ) ϕ ( r ) \phi(\mathbf{r}) ϕ ( r ) r , ρ \mathbf{r}, \boldsymbol{\rho} r , ρ r = ∣ r ∣ r=|\mathbf{r}| r = ∣ r ∣
传统波前重构算法仅提取 h m , n h_{m,n} h m , n 质心位移 ,反演局部相位斜率,从而得到相位图 ϕ ( r ) \phi(\mathbf{r}) ϕ ( r ) h m , n h_{m,n} h m , n
子孔径间光斑亮度差异 → 瞳孔面不同区域的平均振幅 A ( r ) A(\mathbf{r}) A ( r )
若将哈特曼测得的所有子孔径振幅值拼接,即可得到 pupil 面上的宏观振幅分布图 A ( r ) A(\mathbf{r}) A ( r )
U ( r ) = A ( r ) e i ϕ ( r ) (1) \boxed{
U(\mathbf{r}) = A(\mathbf{r}) \, e^{i\phi(\mathbf{r})}
}
\tag{1}
U ( r ) = A ( r ) e i ϕ ( r ) ( 1 )
其中 A ( r ) A(\mathbf{r}) A ( r )
8.1.2. 在自适应光学链路中,哈特曼测得的波前会被送入后续光学系统(如聚焦透镜)。根据傅里叶光学,透镜后焦面的光场正比于瞳孔面复光场的傅里叶变换:
U f ( ρ ) = F { U ( r ) } ( ρ ) = F { A ( r ) e i ϕ ( r ) } ( ρ ) U_f(\boldsymbol{\rho}) = \mathcal{F}\{ U(\mathbf{r}) \}(\boldsymbol{\rho}) = \mathcal{F}\{ A(\mathbf{r}) e^{i\phi(\mathbf{r})} \}(\boldsymbol{\rho})
U f ( ρ ) = F { U ( r ) } ( ρ ) = F { A ( r ) e i ϕ ( r ) } ( ρ )
聚焦**点扩散函数(PSF)**定义为焦面强度分布:
h ( ρ ) = ∣ F { A ( r ) e i ϕ ( r ) } ( ρ ) ∣ 2 (2) \boxed{
h(\boldsymbol{\rho}) = \left| \mathcal{F}\{ A(\mathbf{r}) e^{i\phi(\mathbf{r})} \}(\boldsymbol{\rho}) \right|^2
}
\tag{2}
h ( ρ ) = ∣ ∣ ∣ F { A ( r ) e i ϕ ( r ) } ( ρ ) ∣ ∣ ∣ 2 ( 2 )
式 (2) 建立了完整的物理链路:哈特曼子孔径间光斑亮度不均匀 → 表征为波前振幅 A ( r ) A(\mathbf{r}) A ( r ) e i ϕ e^{i\phi} e i ϕ
8.2. 8.2.1. 为剥离相位因素的干扰,考虑一种常见场景:相位已被哈特曼测得并完全校正 (或入射光本身为平面波,ϕ ( r ) = 0 \phi(\mathbf{r})=0 ϕ ( r ) = 0
h ( ρ ) = ∣ F { A ( r ) } ( ρ ) ∣ 2 (3) \boxed{
h(\boldsymbol{\rho}) = \left| \mathcal{F}\{ A(\mathbf{r}) \}(\boldsymbol{\rho}) \right|^2
}
\tag{3}
h ( ρ ) = ∣ F { A ( r ) } ( ρ ) ∣ 2 ( 3 )
式 (3) 是本文的核心结果:当相位恒定时,聚焦 PSF 完全由瞳孔振幅分布 A ( r ) A(\mathbf{r}) A ( r ) 这意味着,即使哈特曼测得"理想平面波"相位,只要子孔径间存在亮度不均匀(即 A ( r ) ≠ const A(\mathbf{r}) \neq \text{const} A ( r ) = const
8.2.2. 将 pupil 面划分为 M × M M \times M M × M A m , n A_{m,n} A m , n
A ( r ) = ∑ m , n A m , n P m , n ( r ) A(\mathbf{r}) = \sum_{m,n} A_{m,n} \, P_{m,n}(\mathbf{r})
A ( r ) = m , n ∑ A m , n P m , n ( r )
其中 P m , n ( r ) P_{m,n}(\mathbf{r}) P m , n ( r ) ( m , n ) (m,n) ( m , n )
h ( ρ ) = ∣ ∑ m , n A m , n F { P m , n } ( ρ ) ∣ 2 h(\boldsymbol{\rho}) = \left| \sum_{m,n} A_{m,n} \, \mathcal{F}\{P_{m,n}\}(\boldsymbol{\rho}) \right|^2
h ( ρ ) = ∣ ∣ ∣ ∣ ∣ m , n ∑ A m , n F { P m , n } ( ρ ) ∣ ∣ ∣ ∣ ∣ 2
对于尺寸为 d × d d \times d d × d F { P m , n } ∝ sinc ( u d ) sinc ( v d ) \mathcal{F}\{P_{m,n}\} \propto \text{sinc}(u d) \, \text{sinc}(v d) F { P m , n } ∝ sinc ( u d ) sinc ( v d ) A m , n A_{m,n} A m , n
物理意义 :
若所有 A m , n = A 0 A_{m,n}=A_0 A m , n = A 0
若 A m , n A_{m,n} A m , n 旁瓣能量泄漏 ;
若 A m , n A_{m,n} A m , n
8.2.3. 由帕塞瓦尔定理:
∫ ∣ A ( r ) ∣ 2 d r = ∫ h ( ρ ) d ρ = E total \int |A(\mathbf{r})|^2 d\mathbf{r} = \int h(\boldsymbol{\rho}) d\boldsymbol{\rho} = E_{\text{total}}
∫ ∣ A ( r ) ∣ 2 d r = ∫ h ( ρ ) d ρ = E total
总能量守恒。但振幅不均匀会在空间上重新分配能量:将中心主瓣的能量转移到旁瓣。
定义旁瓣能量占比 :
η = ∫ sidelobe h ( ρ ) d ρ E total \eta = \frac{\int_{\text{sidelobe}} h(\boldsymbol{\rho}) d\boldsymbol{\rho}}{E_{\text{total}}}
η = E total ∫ sidelobe h ( ρ ) d ρ
对于均匀振幅,理想情况下 η \eta η η \eta η
8.2.4.
子孔径振幅分布 A m , n A_{m,n} A m , n
哈特曼观测现象
对聚焦 PSF 的影响
全部相等(Uniform)
所有子孔径光斑亮度一致
理想衍射极限 PSF,旁瓣最低
随机起伏(Random)
子孔径光斑亮度无规则差异
不规则旁瓣,峰值强度下降
中心高、边缘低(Gaussian)
中心子孔径亮,边缘子孔径暗
主瓣略宽,旁瓣被压制
棋盘格交替(Checkerboard)
相邻子孔径亮度交替变化
强烈的周期性旁瓣,能量泄漏严重
部分子孔径丢失(Dropout)
部分子孔径完全无光
PSF 出现十字/星形旁瓣,类似稀疏孔径
8.3. 采用离散 FFT 模拟式 (3) 的物理过程。设 pupil 面采样为 N × N N \times N N × N 8 × 8 8 \times 8 8 × 8 r ≤ 0.9 r \le 0.9 r ≤ 0 . 9 A m , n A_{m,n} A m , n h = ∣ FFT2 { A } ∣ 2 h = |\text{FFT2}\{A\}|^2 h = ∣ FFT2 { A } ∣ 2
8.3.1. 对比五种典型子孔径振幅分布:
Uniform :所有子孔径 A m , n = 1 A_{m,n}=1 A m , n = 1 Random subap :每个子孔径随机振幅 0.2 ∼ 1.0 0.2 \sim 1.0 0 . 2 ∼ 1 . 0 Gaussian subap :子孔径振幅按高斯分布(中心亮、边缘暗)Checkerboard :相邻子孔径振幅 0.2 0.2 0 . 2 1.0 1.0 1 . 0 Partial dropout :随机 20% 子孔径振幅置零(模拟遮挡/坏点)
8.3.2. 下图从左至右依次展示了子孔径振幅分布 A ( r ) A(\mathbf{r}) A ( r )
观察结果 :
Uniform :所有子孔径等亮,焦面振幅为理想 sinc 包络,PSF 主瓣最尖锐,旁瓣最低。Random subap :子孔径亮度随机起伏破坏了相干相消,对数图中可见明显的无规则旁瓣。Gaussian subap :边缘子孔径被抑制,等效于对有限孔径做软边切趾(apodization),旁瓣能量被压到约 3%,为所有情况中最低。Checkerboard :相邻子孔径振幅反相交替,引入强高频分量,PSF 出现显著的周期性旁瓣,能量大量泄漏。Partial dropout :部分子孔径缺失,等效于稀疏孔径,PSF 出现十字形旁瓣结构,与干涉合成孔径的点扩散函数形态一致。
9. 推导为什么"在仿真中加 Zernike 离焦项"与"真实光路中移动相机"是完全等价的。
9.1. 先画一个简单的示意图:
1 2 3 4 光瞳平面 (Pupil Plane) 焦平面 (Focal Plane) 离焦平面 (Defocus Plane) ↓ ↓ ↓ [○] ←——— 距离 f ———→ [·] ←——— 距离 Δz ———→ [○] 圆形孔径 理想聚焦点 离焦光斑
光瞳平面 :Mask.mat 描述的圆孔,直径 D = 60 mm D = 60\,\text{mm} D = 6 0 mm 焦平面 :距离光瞳 f = 1248.158 mm f = 1248.158\,\text{mm} f = 1 2 4 8 . 1 5 8 mm 离焦平面 :你把相机往前或往后移动了 Δ z \Delta z Δ z
光瞳平面上的场 U p U_p U p
9.2. 9.2.1. 在仿真中,你的代码做了这样一件事:在原来的 Zernike 系数基础上,给离焦项额外加一个系数 C d C_d C d μ m \mu\text{m} μ m
于是光瞳上的波前(以长度为单位)变为:
W A ( ρ ) = C d ⋅ Z defocus ( ρ ) = C d ( c 2 ρ 2 + c 0 ) W_A(\rho) = C_d \cdot Z_{\text{defocus}}(\rho) = C_d \, (c_2 \rho^2 + c_0)
W A ( ρ ) = C d ⋅ Z defocus ( ρ ) = C d ( c 2 ρ 2 + c 0 )
对应的相位为:
ϕ A ( r ) = 2 π λ W A ( ρ ) \phi_A(r) = \frac{2\pi}{\lambda} \, W_A(\rho)
ϕ A ( r ) = λ 2 π W A ( ρ )
把 ρ = 2 r / D \rho = 2r/D ρ = 2 r / D
ϕ A ( r ) = 2 π λ C d ( c 2 ⋅ 4 r 2 D 2 + c 0 ) = 8 π c 2 λ D 2 C d r 2 ⏟ 随 r 变化的部分 + 2 π c 0 λ C d ⏟ 常数部分 \begin{aligned}
\phi_A(r) &= \frac{2\pi}{\lambda} \, C_d \left(c_2 \cdot \frac{4r^2}{D^2} + c_0\right) \\[8pt]
&= \underbrace{\frac{8\pi c_2}{\lambda D^2} \, C_d \, r^2}_{\text{随 } r \text{ 变化的部分}} + \underbrace{\frac{2\pi c_0}{\lambda} \, C_d}_{\text{常数部分}}
\end{aligned}
ϕ A ( r ) = λ 2 π C d ( c 2 ⋅ D 2 4 r 2 + c 0 ) = 随 r 变化的部分 λ D 2 8 π c 2 C d r 2 + 常数部分 λ 2 π c 0 C d
9.2.2. 上式中第二项 2 π c 0 λ C d \frac{2\pi c_0}{\lambda} C_d λ 2 π c 0 C d r r r
由于 PSF 的计算是取模平方:
PSF = ∣ F { A ⋅ e i ( ϕ + ϕ 0 ) } ∣ 2 = ∣ e i ϕ 0 ⋅ F { A ⋅ e i ϕ } ∣ 2 = ∣ F { A ⋅ e i ϕ } ∣ 2 \text{PSF} = \bigl|\mathcal{F}\{A \cdot e^{i(\phi + \phi_0)}\}\bigr|^2 = \bigl|e^{i\phi_0} \cdot \mathcal{F}\{A \cdot e^{i\phi}\}\bigr|^2 = \bigl|\mathcal{F}\{A \cdot e^{i\phi}\}\bigr|^2
PSF = ∣ ∣ F { A ⋅ e i ( ϕ + ϕ 0 ) } ∣ ∣ 2 = ∣ ∣ e i ϕ 0 ⋅ F { A ⋅ e i ϕ } ∣ ∣ 2 = ∣ ∣ F { A ⋅ e i ϕ } ∣ ∣ 2
常数相位 e i ϕ 0 e^{i\phi_0} e i ϕ 0 我们在比较两种方法时,只需要关心 r 2 r^2 r 2
9.3. 9.3.1. 想象你用放大镜聚焦阳光到一张纸上的一个小点。如果你把纸往上移一点(远离放大镜),光点就会变大变模糊。这就是离焦 。
在数学上,移动相机 Δ z \Delta z Δ z f + Δ z f + \Delta z f + Δ z f f f
9.3.2. 9.3.2.1. 核心问题:光从光瞳传播到像面,中间发生了什么?
荷兰物理学家惠更斯(Christiaan Huygens)在 1678 年提出了一个惊人的想法:
波前上的每一点,都可以看作是一个新的球面波的波源。这些次级球面波向四面八方传播,它们互相叠加,就形成了下一时刻的波前。
光从光瞳传播到像面的过程,本质上就是:光瞳上的每一点发出球面波,这些球面波在像面上叠加干涉。
你可能会问:如果每一点都向四面八方发球面波,平面波不就散开了吗?
这是一个非常经典的问题!答案是:球面波确实向四面八方扩散了,但它们在绝大多数方向上会互相抵消,只在特定方向上相干增强。
用排队扔石头来理解:
想象 100 个人站成一条直线(模拟平面波的波前),每个人同时扔一块石头到水里。每个人产生的波纹都是圆形,向四面八方扩散。
现在问你:在这些人正前方远处的水面上,波纹是什么样的?
答案是:还是一条直线形波纹(平面波)!
为什么?因为在正前方远处的某一点:
从左边第 1 个人传来的波纹走了最远的路,相位滞后最多
从中间第 50 个人传来的波纹走了最短的路,相位滞后最少
从右边第 100 个人传来的波纹走了最远的路,相位滞后最多
但这些波纹到达时,波峰恰好对齐 ——左边的波峰虽然出发早,但走得远;右边的波峰虽然出发晚,但走得近。最终所有波峰同时到达,叠加成一个更强的平面波。
而在侧向 (比如垂直于这条直线的方向):
左边的人和右边的人到侧向某点的距离不同
他们发出的球面波到达时,有的波峰、有的波谷
一正一负,互相抵消了
数学上的结果是: 无穷多个球面波的相干叠加,恰好重构出了原来的平面波。这正是惠更斯原理的精妙之处——它看起来让波"散开"了,但通过干涉,波实际上保持了原来的传播方向。
回到我们的系统: 光瞳不是一个完整的平面波前,而是一个被圆孔截断的平面波。圆孔内每一点都发出球面波:
在正前方(光轴方向),球面波相干增强,形成主光斑
在其他方向,由于圆孔边缘的限制,球面波不能完全抵消,形成了衍射环(Airy 环)
这就是光从光瞳传播到像面时产生 PSF 的本质。
9.3.2.2. 现在我们有了物理图像:光瞳上的每一点发出球面波,在像面上叠加。接下来我们需要把这个图像翻译成数学公式。
9.3.2.2.1. 在三维空间中,一个点波源发出的球面波,在距离它 R R R
球面波 ∝ e i k R R \text{球面波} \propto \frac{e^{ikR}}{R}
球面波 ∝ R e i k R
其中:
k = 2 π / λ k = 2\pi/\lambda k = 2 π / λ e i k R e^{ikR} e i k R λ \lambda λ 2 π 2\pi 2 π 1 / R 1/R 1 / R 4 π R 2 4\pi R^2 4 π R 2
9.3.2.2.2. 光瞳上的一点 ( x p , y p ) (x_p, y_p) ( x p , y p ) ( x , y ) (x, y) ( x , y ) R R R
R = ( x − x p ) 2 + ( y − y p ) 2 + z 2 R = \sqrt{(x-x_p)^2 + (y-y_p)^2 + z^2}
R = ( x − x p ) 2 + ( y − y p ) 2 + z 2
其中 z z z z = f z=f z = f z = f + Δ z z=f+\Delta z z = f + Δ z
9.3.2.2.3. 在我们的系统中,光瞳直径 D = 60 mm D = 60\,\text{mm} D = 6 0 mm f = 1248 mm f = 1248\,\text{mm} f = 1 2 4 8 mm D / ( 2 f ) ≈ 0.024 D/(2f) \approx 0.024 D / ( 2 f ) ≈ 0 . 0 2 4 ≈ 1.4 ° \approx 1.4° ≈ 1 . 4 °
这意味着我们可以做一个近似:( x − x p ) (x-x_p) ( x − x p ) ( y − y p ) (y-y_p) ( y − y p ) z z z R R R
R = z 1 + ( x − x p ) 2 + ( y − y p ) 2 z 2 ≈ z ( 1 + ( x − x p ) 2 + ( y − y p ) 2 2 z 2 ) = z + ( x − x p ) 2 + ( y − y p ) 2 2 z \begin{aligned}
R &= z\sqrt{1 + \frac{(x-x_p)^2 + (y-y_p)^2}{z^2}} \\[6pt]
&\approx z \left(1 + \frac{(x-x_p)^2 + (y-y_p)^2}{2z^2}\right) \\[6pt]
&= z + \frac{(x-x_p)^2 + (y-y_p)^2}{2z}
\end{aligned}
R = z 1 + z 2 ( x − x p ) 2 + ( y − y p ) 2 ≈ z ( 1 + 2 z 2 ( x − x p ) 2 + ( y − y p ) 2 ) = z + 2 z ( x − x p ) 2 + ( y − y p ) 2
这个近似叫做傍轴近似 ,它把复杂的球面波传播简化为一个二次函数。
9.3.2.2.4. 把 R ≈ z + ( x − x p ) 2 + ( y − y p ) 2 2 z R \approx z + \frac{(x-x_p)^2 + (y-y_p)^2}{2z} R ≈ z + 2 z ( x − x p ) 2 + ( y − y p ) 2
e i k R R ≈ e i k z z ⋅ exp [ i k 2 z ( ( x − x p ) 2 + ( y − y p ) 2 ) ] \frac{e^{ikR}}{R} \approx \frac{e^{ikz}}{z} \cdot \exp\!\left[i \frac{k}{2z}\bigl((x-x_p)^2 + (y-y_p)^2\bigr)\right]
R e i k R ≈ z e i k z ⋅ exp [ i 2 z k ( ( x − x p ) 2 + ( y − y p ) 2 ) ]
因为 k = 2 π / λ k = 2\pi/\lambda k = 2 π / λ k / ( 2 z ) = π / ( λ z ) k/(2z) = \pi/(\lambda z) k / ( 2 z ) = π / ( λ z )
e i k z z ⋅ exp [ i π λ z ( ( x − x p ) 2 + ( y − y p ) 2 ) ] \frac{e^{ikz}}{z} \cdot \exp\!\left[i \frac{\pi}{\lambda z}\bigl((x-x_p)^2 + (y-y_p)^2\bigr)\right]
z e i k z ⋅ exp [ i λ z π ( ( x − x p ) 2 + ( y − y p ) 2 ) ]
这就是从光瞳上一点到像面一点的球面波传播因子 。
9.3.2.2.5. 根据惠更斯原理,像面上 ( x , y ) (x, y) ( x , y ) 所有点 发出的球面波到达那里的叠加。
用积分表示:
U ( x , y , z ) = e i k z i λ z ∬ U p ( x p , y p ) exp [ i π λ z ( ( x − x p ) 2 + ( y − y p ) 2 ) ] d x p d y p U(x, y, z) = \frac{e^{ikz}}{i\lambda z} \iint U_p(x_p, y_p) \, \exp\!\left[i \frac{\pi}{\lambda z}\bigl((x-x_p)^2 + (y-y_p)^2\bigr)\right] dx_p dy_p
U ( x , y , z ) = i λ z e i k z ∬ U p ( x p , y p ) exp [ i λ z π ( ( x − x p ) 2 + ( y − y p ) 2 ) ] d x p d y p
这就是菲涅耳衍射公式 。逐项解释:
项
含义
e i k z i λ z \displaystyle \frac{e^{ikz}}{i\lambda z} i λ z e i k z 整体比例因子和相位偏移。e i k z e^{ikz} e i k z z z z i i i 90 ° 90° 9 0 ° 1 / ( λ z ) 1/(\lambda z) 1 / ( λ z )
U p ( x p , y p ) \displaystyle U_p(x_p, y_p) U p ( x p , y p ) 光瞳平面上的场(振幅 + 相位),也就是每个"次级波源"的强度
exp [ i π λ z ( ( x − x p ) 2 + ( y − y p ) 2 ) ] \displaystyle \exp\!\left[i \frac{\pi}{\lambda z}\bigl((x-x_p)^2 + (y-y_p)^2\bigr)\right] exp [ i λ z π ( ( x − x p ) 2 + ( y − y p ) 2 ) ] 从 ( x p , y p ) (x_p, y_p) ( x p , y p ) ( x , y ) (x, y) ( x , y ) ( x − x p ) 2 (x-x_p)^2 ( x − x p ) 2
∬ ⋯ d x p d y p \displaystyle \iint \cdots dx_p dy_p ∬ ⋯ d x p d y p 对光瞳上所有点积分——把所有球面波叠加起来
所以,公式里的平方项 exp [ i π λ z ( ⋯ ) 2 ] \exp[i\frac{\pi}{\lambda z}(\cdots)^2] exp [ i λ z π ( ⋯ ) 2 ] 每一点到每一点的距离不同,相位也就不同,所有不同的相位叠加在一起,就产生了衍射图案。
9.3.2.3. 现在我们有了菲涅耳衍射公式,接下来要做一件关键的数学操作:把指数里的平方项展开。这会让我们看到三个清晰的物理含义。
把指数项展开:
exp [ i π λ z ( ( x − x p ) 2 + ( y − y p ) 2 ) ] = exp [ i π λ z ( x 2 + y 2 ) ] ⋅ exp [ − i 2 π λ z ( x x p + y y p ) ] ⋅ exp [ i π λ z ( x p 2 + y p 2 ) ] \begin{aligned}
&\exp\!\left[i \frac{\pi}{\lambda z}\bigl((x-x_p)^2 + (y-y_p)^2\bigr)\right] \\[6pt]
=& \exp\!\left[i \frac{\pi}{\lambda z}(x^2 + y^2)\right] \cdot \exp\!\left[-i \frac{2\pi}{\lambda z}(xx_p + yy_p)\right] \cdot \exp\!\left[i \frac{\pi}{\lambda z}(x_p^2 + y_p^2)\right]
\end{aligned}
= exp [ i λ z π ( ( x − x p ) 2 + ( y − y p ) 2 ) ] exp [ i λ z π ( x 2 + y 2 ) ] ⋅ exp [ − i λ z 2 π ( x x p + y y p ) ] ⋅ exp [ i λ z π ( x p 2 + y p 2 ) ]
这三项分别代表:
exp [ i π λ z ( x 2 + y 2 ) ] \exp\!\left[i \frac{\pi}{\lambda z}(x^2 + y^2)\right] exp [ i λ z π ( x 2 + y 2 ) ] exp [ − i 2 π λ z ( x x p + y y p ) ] \exp\!\left[-i \frac{2\pi}{\lambda z}(xx_p + yy_p)\right] exp [ − i λ z 2 π ( x x p + y y p ) ] exp [ i π λ z ( x p 2 + y p 2 ) ] \exp\!\left[i \frac{\pi}{\lambda z}(x_p^2 + y_p^2)\right] exp [ i λ z π ( x p 2 + y p 2 ) ] 这就是菲涅耳衍射与夫琅禾费衍射的区别所在
9.3.2.4. 在我们的系统中,光瞳平面紧贴透镜 。透镜的作用是给光波增加一个二次相位:
ϕ lens ( r ) = − π λ f r 2 \phi_{\text{lens}}(r) = -\frac{\pi}{\lambda f} r^2
ϕ lens ( r ) = − λ f π r 2
为什么是负号?因为会聚透镜让光波向中心"收拢",相当于给边缘更多的相位延迟(或者说让中心的相位"超前")。
所以光瞳平面上的总场为:
U p ( x p , y p ) = A ( r ) ⋅ exp [ i ϕ aberration ( r ) ] ⋅ exp ( − i π λ f r 2 ) U_p(x_p, y_p) = A(r) \cdot \exp\!\left[i\phi_{\text{aberration}}(r)\right] \cdot \exp\!\left(-i\frac{\pi}{\lambda f}r^2\right)
U p ( x p , y p ) = A ( r ) ⋅ exp [ i ϕ aberration ( r ) ] ⋅ exp ( − i λ f π r 2 )
9.3.2.5. 现在我们做整个推导中最关键的一步:把透镜引入的二次相位 和菲涅耳衍射带来的二次相位 合并在一起。
9.3.2.5.1. 在光瞳平面上,有两个二次相位因子:
菲涅耳衍射带来的 (来自传播距离 z z z
exp [ i π λ z ( x p 2 + y p 2 ) ] \exp\!\left[i\frac{\pi}{\lambda z}(x_p^2 + y_p^2)\right]
exp [ i λ z π ( x p 2 + y p 2 ) ]
薄透镜带来的 (焦距 f f f
exp ( − i π λ f ( x p 2 + y p 2 ) ] \exp\!\left(-i\frac{\pi}{\lambda f}(x_p^2 + y_p^2)\right]
exp ( − i λ f π ( x p 2 + y p 2 ) ]
把它们相乘(合并):
exp ( − i π λ f ( x p 2 + y p 2 ) ) ⋅ exp ( i π λ z ( x p 2 + y p 2 ) ) = exp [ i π λ ( 1 z − 1 f ) ( x p 2 + y p 2 ) ] \exp\!\left(-i\frac{\pi}{\lambda f}(x_p^2 + y_p^2)\right) \cdot \exp\!\left(i\frac{\pi}{\lambda z}(x_p^2 + y_p^2)\right)
= \exp\!\left[i\frac{\pi}{\lambda}\left(\frac{1}{z} - \frac{1}{f}\right)(x_p^2 + y_p^2)\right]
exp ( − i λ f π ( x p 2 + y p 2 ) ) ⋅ exp ( i λ z π ( x p 2 + y p 2 ) ) = exp [ i λ π ( z 1 − f 1 ) ( x p 2 + y p 2 ) ]
9.3.2.5.2. z = f z = f z = f 当像面恰好在焦平面时,z = f z = f z = f
1 z − 1 f = 1 f − 1 f = 0 \frac{1}{z} - \frac{1}{f} = \frac{1}{f} - \frac{1}{f} = 0
z 1 − f 1 = f 1 − f 1 = 0
代入合并后的相位:
exp [ i π λ ⋅ 0 ⋅ ( x p 2 + y p 2 ) ] = exp ( 0 ) = 1 \exp\!\left[i\frac{\pi}{\lambda} \cdot 0 \cdot (x_p^2 + y_p^2)\right] = \exp(0) = 1
exp [ i λ π ⋅ 0 ⋅ ( x p 2 + y p 2 ) ] = exp ( 0 ) = 1
二次相位完全抵消了!
9.3.2.5.3. 让我们把 z = f z = f z = f
原始公式(回忆第二步):
U ( x , y , z ) = e i k z i λ z ∬ U p ( x p , y p ) exp [ i π λ z ( ( x − x p ) 2 + ( y − y p ) 2 ) ] d x p d y p U(x, y, z) = \frac{e^{ikz}}{i\lambda z} \iint U_p(x_p, y_p) \, \exp\!\left[i \frac{\pi}{\lambda z}\bigl((x-x_p)^2 + (y-y_p)^2\bigr)\right] dx_p dy_p
U ( x , y , z ) = i λ z e i k z ∬ U p ( x p , y p ) exp [ i λ z π ( ( x − x p ) 2 + ( y − y p ) 2 ) ] d x p d y p
我们已经把指数展开成了三项(第三步):
exp [ i π λ z ( x 2 + y 2 ) ] ⋅ exp [ − i 2 π λ z ( x x p + y y p ) ] ⋅ exp [ i π λ z ( x p 2 + y p 2 ) ] \exp\!\left[i \frac{\pi}{\lambda z}(x^2 + y^2)\right] \cdot \exp\!\left[-i \frac{2\pi}{\lambda z}(xx_p + yy_p)\right] \cdot \exp\!\left[i \frac{\pi}{\lambda z}(x_p^2 + y_p^2)\right]
exp [ i λ z π ( x 2 + y 2 ) ] ⋅ exp [ − i λ z 2 π ( x x p + y y p ) ] ⋅ exp [ i λ z π ( x p 2 + y p 2 ) ]
现在 z = f z = f z = f U p U_p U p
exp [ i π λ f ( x p 2 + y p 2 ) ] ⏟ 菲涅耳传播 ⋅ exp ( − i π λ f ( x p 2 + y p 2 ) ] ⏟ 透镜调制 = 1 \underbrace{\exp\!\left[i\frac{\pi}{\lambda f}(x_p^2 + y_p^2)\right]}_{\text{菲涅耳传播}} \cdot \underbrace{\exp\!\left(-i\frac{\pi}{\lambda f}(x_p^2 + y_p^2)\right]}_{\text{透镜调制}} = 1
菲涅耳传播 exp [ i λ f π ( x p 2 + y p 2 ) ] ⋅ 透镜调制 exp ( − i λ f π ( x p 2 + y p 2 ) ] = 1
它们精确抵消了!
剩下的部分:
U ( x , y , f ) = e i k f i λ f ⋅ exp [ i π λ f ( x 2 + y 2 ) ] ∬ U p 原始 ( x p , y p ) exp [ − i 2 π λ f ( x x p + y y p ) ] d x p d y p U(x, y, f) = \frac{e^{ikf}}{i\lambda f} \cdot \exp\!\left[i\frac{\pi}{\lambda f}(x^2 + y^2)\right] \iint U_p^{\text{原始}}(x_p, y_p) \, \exp\!\left[-i\frac{2\pi}{\lambda f}(xx_p + yy_p)\right] dx_p dy_p
U ( x , y , f ) = i λ f e i k f ⋅ exp [ i λ f π ( x 2 + y 2 ) ] ∬ U p 原始 ( x p , y p ) exp [ − i λ f 2 π ( x x p + y y p ) ] d x p d y p
其中 U p 原始 ( x p , y p ) = A ( r ) ⋅ exp [ i ϕ aberration ( r ) ] U_p^{\text{原始}}(x_p, y_p) = A(r) \cdot \exp[i\phi_{\text{aberration}}(r)] U p 原始 ( x p , y p ) = A ( r ) ⋅ exp [ i ϕ aberration ( r ) ]
现在看积分号里面的东西:
∬ U p 原始 ( x p , y p ) exp [ − i 2 π λ f ( x x p + y y p ) ] d x p d y p \iint U_p^{\text{原始}}(x_p, y_p) \, \exp\!\left[-i\frac{2\pi}{\lambda f}(xx_p + yy_p)\right] dx_p dy_p
∬ U p 原始 ( x p , y p ) exp [ − i λ f 2 π ( x x p + y y p ) ] d x p d y p
这正是二维傅里叶变换 的定义!
回忆傅里叶变换的标准形式:
F { g ( x p , y p ) } = ∬ g ( x p , y p ) e − i 2 π ( f x x p + f y y p ) d x p d y p \mathcal{F}\{g(x_p, y_p)\} = \iint g(x_p, y_p) \, e^{-i2\pi(f_x x_p + f_y y_p)} dx_p dy_p
F { g ( x p , y p ) } = ∬ g ( x p , y p ) e − i 2 π ( f x x p + f y y p ) d x p d y p
对比可得:
空间频率 f x = x λ f f_x = \dfrac{x}{\lambda f} f x = λ f x
空间频率 f y = y λ f f_y = \dfrac{y}{\lambda f} f y = λ f y
物理意义:
像面上位置 x x x f x f_x f x
这是因为从光瞳边缘发出的光(高频成分)会聚焦到像面的边缘
9.3.2.5.4. 历史上,夫琅禾费(Joseph von Fraunhofer)发现:当观察屏距离衍射孔足够远时(远场),衍射图案就是孔径函数的傅里叶变换。
在我们的系统中,透镜起到了"压缩距离"的作用:
没有透镜时,你需要让光传播到无穷远 才能看到夫琅禾费衍射图案
有了透镜,焦平面就是等效的无穷远 ——因为透镜把所有平行光(不同角度)聚焦到焦平面的不同位置
所以:焦平面上的场 = 光瞳场的傅里叶变换。
这正是你的代码中用 fft2 计算 PSF 的数学基础。
9.3.2.5.5. 为什么透镜相位和菲涅耳相位会抵消?
菲涅耳传播相位 ( + π λ z r 2 ) \left(+\dfrac{\pi}{\lambda z}r^2\right) ( + λ z π r 2 )
透镜相位 ( − π λ f r 2 ) \left(-\dfrac{\pi}{\lambda f}r^2\right) ( − λ f π r 2 )
当 z = f z = f z = f
透镜让波前弯曲了 − π λ f r 2 -\dfrac{\pi}{\lambda f}r^2 − λ f π r 2
传播恰好需要 + π λ f r 2 +\dfrac{\pi}{\lambda f}r^2 + λ f π r 2
两者一加一减,完美抵消,波前在焦平面上变成一个完美的点(理想情况下)
9.3.2.6. Δ z \Delta z Δ z 现在你把相机移动了 Δ z \Delta z Δ z z = f + Δ z z = f + \Delta z z = f + Δ z
计算:
1 z − 1 f = 1 f + Δ z − 1 f = f − ( f + Δ z ) f ( f + Δ z ) = − Δ z f ( f + Δ z ) \frac{1}{z} - \frac{1}{f} = \frac{1}{f+\Delta z} - \frac{1}{f} = \frac{f - (f+\Delta z)}{f(f+\Delta z)} = -\frac{\Delta z}{f(f+\Delta z)}
z 1 − f 1 = f + Δ z 1 − f 1 = f ( f + Δ z ) f − ( f + Δ z ) = − f ( f + Δ z ) Δ z
在傍轴近似下,Δ z ≪ f \Delta z \ll f Δ z ≪ f f + Δ z ≈ f f + \Delta z \approx f f + Δ z ≈ f
1 z − 1 f ≈ − Δ z f 2 \frac{1}{z} - \frac{1}{f} \approx -\frac{\Delta z}{f^2}
z 1 − f 1 ≈ − f 2 Δ z
代入相位表达式:
exp [ i π λ ( − Δ z f 2 ) r 2 ] = exp ( − i π Δ z λ f 2 r 2 ) \exp\!\left[i\frac{\pi}{\lambda}\left(-\frac{\Delta z}{f^2}\right)r^2\right] = \exp\!\left(-i\frac{\pi\Delta z}{\lambda f^2}r^2\right)
exp [ i λ π ( − f 2 Δ z ) r 2 ] = exp ( − i λ f 2 π Δ z r 2 )
9.3.2.7. 取指数中的相位部分,得到方法 B 的核心表达式:
ϕ B ( r ) = − π λ f 2 Δ z r 2 \boxed{
\phi_B(r) = -\frac{\pi}{\lambda f^2} \, \Delta z \, r^2
}
ϕ B ( r ) = − λ f 2 π Δ z r 2
物理意义再解释一遍:
当 Δ z > 0 \Delta z > 0 Δ z > 0 ϕ B ( r ) \phi_B(r) ϕ B ( r )
这意味着光瞳中心相对于边缘有额外的相位超前
直观理解:如果像面在焦点后方,光束到达那里时还没完全会聚,所以光瞳上的波前应该"更平一些"(相比理想会聚球面波)
透镜原本让波前非常弯曲(要会聚到焦点),现在像面远了,所以需要在光瞳上加一个"反弯曲"的相位来补偿
9.4. 9.4.1. 我们可以用一种直接的方式来证明等价性:
两种方法都是在光瞳平面上引入了一个二次相位因子,然后对同一个光瞳做完全相同的夫琅禾费衍射。如果这两个二次相位因子相同,那么像面场 U ( x , y , z ) U(x,y,z) U ( x , y , z )
让我分别写出两种方法的光瞳场,然后直接比较。
9.4.2. 方法 A 直接在光瞳的波前上叠加 Zernike 离焦项:
U p ( A ) ( x p , y p ) = A ( r ) ⋅ exp [ i ϕ base ( r ) ] ⋅ exp [ i ϕ A ( r ) ] U_p^{(A)}(x_p, y_p) = A(r) \cdot \exp\!\left[i\phi_{\text{base}}(r)\right] \cdot \exp\!\left[i\phi_A(r)\right]
U p ( A ) ( x p , y p ) = A ( r ) ⋅ exp [ i ϕ base ( r ) ] ⋅ exp [ i ϕ A ( r ) ]
其中:
A ( r ) A(r) A ( r ) Mask.mat 的二值圆孔)ϕ base ( r ) \phi_{\text{base}}(r) ϕ base ( r ) ϕ A ( r ) = 2 π λ C d Z defocus ( ρ ) = 8 π c 2 λ D 2 C d r 2 + const \phi_A(r) = \dfrac{2\pi}{\lambda} C_d \, Z_{\text{defocus}}(\rho) = \dfrac{8\pi c_2}{\lambda D^2} C_d \, r^2 + \text{const} ϕ A ( r ) = λ 2 π C d Z defocus ( ρ ) = λ D 2 8 π c 2 C d r 2 + const
9.4.3. 方法 B 中,光瞳平面上的原始场(不含额外离焦)为:
U p ( B , 原始 ) ( x p , y p ) = A ( r ) ⋅ exp [ i ϕ base ( r ) ] U_p^{(B,\text{原始})}(x_p, y_p) = A(r) \cdot \exp\!\left[i\phi_{\text{base}}(r)\right]
U p ( B , 原始 ) ( x p , y p ) = A ( r ) ⋅ exp [ i ϕ base ( r ) ]
光瞳紧贴透镜,透镜引入相位 − π λ f r 2 -\dfrac{\pi}{\lambda f}r^2 − λ f π r 2 z = f + Δ z z = f + \Delta z z = f + Δ z + π λ z r 2 +\dfrac{\pi}{\lambda z}r^2 + λ z π r 2
这两个二次相位合并后(见第五步推导):
exp ( − i π λ f r 2 ) ⋅ exp ( i π λ z r 2 ) = exp [ i π λ ( 1 z − 1 f ) r 2 ] \exp\!\left(-i\frac{\pi}{\lambda f}r^2\right) \cdot \exp\!\left(i\frac{\pi}{\lambda z}r^2\right)
= \exp\!\left[i\frac{\pi}{\lambda}\left(\frac{1}{z} - \frac{1}{f}\right)r^2\right]
exp ( − i λ f π r 2 ) ⋅ exp ( i λ z π r 2 ) = exp [ i λ π ( z 1 − f 1 ) r 2 ]
当 z = f + Δ z z = f + \Delta z z = f + Δ z Δ z ≪ f \Delta z \ll f Δ z ≪ f
1 z − 1 f ≈ − Δ z f 2 \frac{1}{z} - \frac{1}{f} \approx -\frac{\Delta z}{f^2}
z 1 − f 1 ≈ − f 2 Δ z
所以光瞳场上的总二次相位 为:
ϕ B ( r ) = − π λ f 2 Δ z r 2 \phi_B(r) = -\frac{\pi}{\lambda f^2} \, \Delta z \, r^2
ϕ B ( r ) = − λ f 2 π Δ z r 2
因此方法 B 的等效光瞳场为:
U p ( B ) ( x p , y p ) = A ( r ) ⋅ exp [ i ϕ base ( r ) ] ⋅ exp [ i ϕ B ( r ) ] U_p^{(B)}(x_p, y_p) = A(r) \cdot \exp\!\left[i\phi_{\text{base}}(r)\right] \cdot \exp\!\left[i\phi_B(r)\right]
U p ( B ) ( x p , y p ) = A ( r ) ⋅ exp [ i ϕ base ( r ) ] ⋅ exp [ i ϕ B ( r ) ]
9.4.4. 对比 U p ( A ) U_p^{(A)} U p ( A ) U p ( B ) U_p^{(B)} U p ( B )
U p ( A ) = A ( r ) ⋅ e i ϕ base ⋅ exp ( i 8 π c 2 λ D 2 C d r 2 + i const ) U p ( B ) = A ( r ) ⋅ e i ϕ base ⋅ exp ( − i π λ f 2 Δ z r 2 ) \begin{aligned}
U_p^{(A)} &= A(r) \cdot e^{i\phi_{\text{base}}} \cdot \exp\!\left(i\frac{8\pi c_2}{\lambda D^2} C_d \, r^2 + i\,\text{const}\right) \\[8pt]
U_p^{(B)} &= A(r) \cdot e^{i\phi_{\text{base}}} \cdot \exp\!\left(-i\frac{\pi}{\lambda f^2} \Delta z \, r^2\right)
\end{aligned}
U p ( A ) U p ( B ) = A ( r ) ⋅ e i ϕ base ⋅ exp ( i λ D 2 8 π c 2 C d r 2 + i const ) = A ( r ) ⋅ e i ϕ base ⋅ exp ( − i λ f 2 π Δ z r 2 )
两者具有完全相同的结构 :
相同的光瞳振幅 A ( r ) A(r) A ( r )
相同的基础相位 ϕ base \phi_{\text{base}} ϕ base
都乘以一个关于 r 2 r^2 r 2
唯一的区别是二次项的系数。如果我们选择合适的 Δ z \Delta z Δ z
8 π c 2 λ D 2 C d = − π λ f 2 Δ z \frac{8\pi c_2}{\lambda D^2} \, C_d = -\frac{\pi}{\lambda f^2} \, \Delta z
λ D 2 8 π c 2 C d = − λ f 2 π Δ z
两边约去 π / λ \pi/\lambda π / λ
8 c 2 D 2 C d = − 1 f 2 Δ z \frac{8 c_2}{D^2} \, C_d = -\frac{1}{f^2} \, \Delta z
D 2 8 c 2 C d = − f 2 1 Δ z
解得:
Δ z = − 8 f 2 c 2 D 2 C d \boxed{
\Delta z = -\frac{8 f^2 c_2}{D^2} \, C_d
}
Δ z = − D 2 8 f 2 c 2 C d
9.4.5. 当 Δ z \Delta z Δ z C d C_d C d
U p ( A ) ( x p , y p ) = U p ( B ) ( x p , y p ) ⋅ e i const U_p^{(A)}(x_p, y_p) = U_p^{(B)}(x_p, y_p) \cdot e^{i\,\text{const}}
U p ( A ) ( x p , y p ) = U p ( B ) ( x p , y p ) ⋅ e i const
两者相差一个全局常数相位 (来自 Zernike 离焦项的 piston c 0 c_0 c 0
由于两种方法的光瞳场完全相同(允许全局相位差),它们经过完全相同的 夫琅禾费衍射过程后,必然得到完全相同的 像面场 U ( x , y , z ) U(x,y,z) U ( x , y , z ) 完全相同的 PSF。
这就严格证明了两种方法的等价性。
9.5. 9.5.1. 我们写了一个 Python 程序 compare_defocus_methods_v2.py,严格按照用户代码中的参数进行仿真:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 """ 对比两种离焦仿真方式(修正版): 方式A:加Zernike离焦项(用户现有代码逻辑) 方式B:移动相机 —— 在光瞳上乘以菲涅耳二次相位因子(傍轴近似下严格等价于移动相机), 然后做夫琅禾费衍射得到离焦PSF。 核心问题:真实光路中通过前后移动相机得到离焦,是否等价于在仿真中直接加Zernike离焦项? """ import numpy as npimport matplotlib.pyplot as pltfrom scipy.io import loadmatimport oszernikePol = loadmat("../ReconMatrix_C.mat" )["ReconMatrix_C" ][:, 2 :].astype(np.float64) Wx = loadmat("../Mask.mat" )["Mask" ].astype(np.float64) Wx[np.isnan(Wx)] = 0.0 H, W = Wx.shape valid_mask = Wx > 0 valid_idx = valid_mask.flatten().nonzero()[0 ] N_valid = len (valid_idx) print (f"光瞳尺寸: {H} x{W} , 有效点: {N_valid} , Zernike阶数: {zernikePol.shape[1 ]} " )NM_TO_M = 1e-9 UM_TO_M = 1e-6 MM_TO_M = 1e-3 wavelength_m = 530 * NM_TO_M total_folcal_len_m = 6240.79 * MM_TO_M ratio_before_pupil = 5 pupil_ccd_focal_len_m = total_folcal_len_m / ratio_before_pupil WFS_pitch_m = 300 * UM_TO_M WFS_N = 10 pupil_to_WFS_ratio = 20 pupil_diameter_m = WFS_pitch_m * WFS_N * pupil_to_WFS_ratio CCD_pixel_pitch_m = 4.5 * UM_TO_M pad_size = 256 print (f"波长 λ = {wavelength_m*1e9 :.1 f} nm" )print (f"成像焦距 f = {pupil_ccd_focal_len_m*1e3 :.3 f} mm" )print (f"光瞳直径 D = {pupil_diameter_m*1e3 :.2 f} mm" )print (f"F数 = {pupil_ccd_focal_len_m / pupil_diameter_m:.2 f} " )defocus_vals = zernikePol[:, 1 ] center = ((W - 1 ) / 2.0 , (H - 1 ) / 2.0 ) radius_px = min (center) y_coords, x_coords = np.indices((H, W)) rho_flat = np.sqrt((x_coords - center[0 ])**2 + (y_coords - center[1 ])**2 ).flatten()[valid_idx] / radius_px A = np.vstack([rho_flat**2 , np.ones_like(rho_flat)]).T a, b = np.linalg.lstsq(A, defocus_vals, rcond=None )[0 ] c2 = a print (f"\nZernike离焦项拟合: Z_defocus = {c2:.6 f} *rho^2 + {b:.6 f} " )print (f"理论 Noll Z4 = sqrt(3)*(2rho^2-1) = {2 *np.sqrt(3 ):.6 f} *rho^2 + {-np.sqrt(3 ):.6 f} " )def zernike_defocus_to_dz (Cd ): return - (8.0 * pupil_ccd_focal_len_m**2 / pupil_diameter_m**2 ) * c2 * Cd test_Cds = [(-0.5 * 0.530 ) * UM_TO_M, -0.1937 * UM_TO_M, -0.530 * UM_TO_M, -1.060 * UM_TO_M] print ("\n--- Zernike离焦系数 ↔ 物理离焦距离换算 ---" )for Cd in test_Cds: dz = zernike_defocus_to_dz(Cd) print (f" Cd = {Cd/UM_TO_M:+.4 f} um <=> dz = {dz*1e3 :+.4 f} mm" ) def simulate_defocus_method_A (zernike_coeffs, Cd_defocus, pad=None ): """ 方式A:Zernike离焦项法(与用户代码一致) """ zc = zernike_coeffs.copy() zc[1 ] += Cd_defocus / UM_TO_M zc = zc * UM_TO_M wavefront_m_flat = zc @ zernikePol.T wavefront_m = np.zeros(H * W, dtype=np.float64) wavefront_m[valid_idx] = wavefront_m_flat wavefront_m = wavefront_m.reshape(H, W) phase = wavefront_m / wavelength_m * 2 * np.pi pupil_complex = Wx * np.exp(1j * phase) if pad is not None and pad > max (H, W): M = pad pad_h = (M - H) // 2 pad_w = (M - W) // 2 padded = np.zeros((M, M), dtype=np.complex128) padded[pad_h:pad_h+H, pad_w:pad_w+W] = pupil_complex pupil_complex = padded else : M = H U_f = np.fft.fft2(pupil_complex, norm="ortho" ) U_f = np.fft.fftshift(U_f, axes=(-2 , -1 )) intensity = np.abs (U_f)**2 n_eff = Wx.sum () max_intensity_theoretical = (n_eff / M)**2 intensity = intensity / max_intensity_theoretical sim_pixel_pitch_m = wavelength_m * pupil_ccd_focal_len_m * H / (M * pupil_diameter_m) return intensity, sim_pixel_pitch_m, M def simulate_defocus_method_B (zernike_coeffs, Cd_defocus, pad=None ): """ 方式B:菲涅耳近似下的移动相机法。 在光瞳上乘以二次相位因子 exp(-i * pi/lambda * dz/f^2 * r^2), 这严格等价于傍轴近似下将像面沿光轴移动距离 dz。 """ zc = zernike_coeffs.copy() * UM_TO_M wavefront_m_flat = zc @ zernikePol.T wavefront_m = np.zeros(H * W, dtype=np.float64) wavefront_m[valid_idx] = wavefront_m_flat wavefront_m = wavefront_m.reshape(H, W) base_phase = wavefront_m / wavelength_m * 2 * np.pi pupil_complex = Wx * np.exp(1j * base_phase) dz = zernike_defocus_to_dz(Cd_defocus) dp = pupil_diameter_m / H y_idx, x_idx = np.indices((H, W)) x_p = (x_idx - (W - 1 ) / 2.0 ) * dp y_p = (y_idx - (H - 1 ) / 2.0 ) * dp r_sq = x_p**2 + y_p**2 phi_defocus = -np.pi / wavelength_m * (dz / pupil_ccd_focal_len_m**2 ) * r_sq pupil_complex = pupil_complex * np.exp(1j * phi_defocus) if pad is not None and pad > max (H, W): M = pad pad_h = (M - H) // 2 pad_w = (M - W) // 2 padded = np.zeros((M, M), dtype=np.complex128) padded[pad_h:pad_h+H, pad_w:pad_w+W] = pupil_complex pupil_complex = padded else : M = H U_f = np.fft.fft2(pupil_complex, norm="ortho" ) U_f = np.fft.fftshift(U_f, axes=(-2 , -1 )) intensity = np.abs (U_f)**2 n_eff = Wx.sum () max_intensity_theoretical = (n_eff / M)**2 intensity = intensity / max_intensity_theoretical sim_pixel_pitch_m = wavelength_m * pupil_ccd_focal_len_m * H / (M * pupil_diameter_m) return intensity, sim_pixel_pitch_m, M, dz zernike_zero = np.zeros(zernikePol.shape[1 ], dtype=np.float64) Cd_test = -0.1937 * UM_TO_M print ("\n" + "=" *60 )print (f"对比实验: Cd = {Cd_test/UM_TO_M:.4 f} um" )print ("=" *60 )psf_A, pitch_A, M_A = simulate_defocus_method_A(zernike_zero, Cd_test, pad=pad_size) psf_B, pitch_B, M_B, dz_actual = simulate_defocus_method_B(zernike_zero, Cd_test, pad=pad_size) print (f"方式A (Zernike离焦): PSF shape={psf_A.shape} , pixel_pitch={pitch_A*1e6 :.3 f} um" )print (f"方式B (菲涅耳移动): PSF shape={psf_B.shape} , pixel_pitch={pitch_B*1e6 :.3 f} um, dz={dz_actual*1e3 :.4 f} mm" )assert np.isclose(pitch_A, pitch_B)assert M_A == M_Bpsf_A_norm = psf_A / psf_A.max () psf_B_norm = psf_B / psf_B.max () abs_diff = np.abs (psf_A_norm - psf_B_norm) threshold = 0.01 mask_compare = (psf_A_norm > threshold) | (psf_B_norm > threshold) mae = np.mean(abs_diff[mask_compare]) rmse = np.sqrt(np.mean(abs_diff[mask_compare]**2 )) max_err = abs_diff[mask_compare].max () print (f"\n差异统计 (mask > {threshold} of max):" )print (f" MAE = {mae:.8 f} " )print (f" RMSE = {rmse:.8 f} " )print (f" Max = {max_err:.8 f} " )mae_full = np.mean(abs_diff) rmse_full = np.sqrt(np.mean(abs_diff**2 )) print (f"\n差异统计 (全图):" )print (f" MAE = {mae_full:.8 f} " )print (f" RMSE = {rmse_full:.8 f} " )def add_crosshair (ax, img, color='lime' ): cy, cx = np.array(img.shape) // 2 ax.axhline(cy, color=color, lw=0.8 , alpha=0.7 ) ax.axvline(cx, color=color, lw=0.8 , alpha=0.7 ) fig, axes = plt.subplots(2 , 4 , figsize=(16 , 8 )) vmax = max (psf_A_norm.max (), psf_B_norm.max ()) axes[0 , 0 ].imshow(psf_A_norm, cmap='hot' , vmin=0 , vmax=vmax) axes[0 , 0 ].set_title(f"Method A: Zernike defocus\nCd={Cd_test/UM_TO_M:.4 f} um" ) axes[0 , 0 ].axis('off' ) add_crosshair(axes[0 , 0 ], psf_A_norm) axes[0 , 1 ].imshow(psf_B_norm, cmap='hot' , vmin=0 , vmax=vmax) axes[0 , 1 ].set_title(f"Method B: Fresnel propagation\ndz={dz_actual*1e3 :.3 f} mm" ) axes[0 , 1 ].axis('off' ) add_crosshair(axes[0 , 1 ], psf_B_norm) im2 = axes[0 , 2 ].imshow(abs_diff, cmap='jet' , vmin=0 , vmax=max_err) axes[0 , 2 ].set_title(f"Absolute diff |A-B|\nMAE={mae:.6 f} , Max={max_err:.6 f} " ) axes[0 , 2 ].axis('off' ) add_crosshair(axes[0 , 2 ], abs_diff) rel_diff = abs_diff / (psf_B_norm + 1e-12 ) rel_diff_vis = np.log10(rel_diff + 1e-6 ) axes[0 , 3 ].imshow(rel_diff_vis, cmap='jet' ) axes[0 , 3 ].set_title("Relative diff log10(|A-B|/B+1e-6)" ) axes[0 , 3 ].axis('off' ) add_crosshair(axes[0 , 3 ], rel_diff) cy = psf_A_norm.shape[0 ] // 2 axes[1 , 0 ].plot(psf_A_norm[cy, :], 'r-' , lw=1.5 , label='Method A (Zernike)' ) axes[1 , 0 ].plot(psf_B_norm[cy, :], 'b--' , lw=1.5 , label='Method B (Fresnel)' ) axes[1 , 0 ].set_title(f"Horizontal profile (y={cy} )" ) axes[1 , 0 ].set_xlabel("pixel" ) axes[1 , 0 ].set_ylabel("normalized intensity" ) axes[1 , 0 ].legend() axes[1 , 0 ].grid(True , alpha=0.3 ) axes[1 , 1 ].plot(abs_diff[cy, :], 'g-' , lw=1.5 ) axes[1 , 1 ].set_title("Horizontal profile diff" ) axes[1 , 1 ].set_xlabel("pixel" ) axes[1 , 1 ].set_ylabel("|A-B|" ) axes[1 , 1 ].grid(True , alpha=0.3 ) cx = psf_A_norm.shape[1 ] // 2 axes[1 , 2 ].plot(psf_A_norm[:, cx], 'r-' , lw=1.5 , label='Method A (Zernike)' ) axes[1 , 2 ].plot(psf_B_norm[:, cx], 'b--' , lw=1.5 , label='Method B (Fresnel)' ) axes[1 , 2 ].set_title(f"Vertical profile (x={cx} )" ) axes[1 , 2 ].set_xlabel("pixel" ) axes[1 , 2 ].set_ylabel("normalized intensity" ) axes[1 , 2 ].legend() axes[1 , 2 ].grid(True , alpha=0.3 ) def radial_profile (img ): y, x = np.indices(img.shape) center = np.array(img.shape) // 2 r = np.sqrt((x - center[1 ])**2 + (y - center[0 ])**2 ).astype(np.int64) r_max = min (center[0 ], center[1 ]) radial_mean = np.zeros(r_max) for i in range (r_max): mask_r = (r == i) if mask_r.sum () > 0 : radial_mean[i] = img[mask_r].mean() return radial_mean rad_A = radial_profile(psf_A_norm) rad_B = radial_profile(psf_B_norm) axes[1 , 3 ].plot(rad_A, 'r-' , lw=1.5 , label='Method A (Zernike)' ) axes[1 , 3 ].plot(rad_B, 'b--' , lw=1.5 , label='Method B (Fresnel)' ) axes[1 , 3 ].set_title("Radial average" ) axes[1 , 3 ].set_xlabel("radius (pixel)" ) axes[1 , 3 ].set_ylabel("normalized intensity" ) axes[1 , 3 ].legend() axes[1 , 3 ].grid(True , alpha=0.3 ) plt.tight_layout() plt.savefig('comparison_defocus_methods_v2.png' , dpi=200 , bbox_inches='tight' ) print ("\nSaved: comparison_defocus_methods_v2.png" )print ("\n" + "=" *60 )print ("Error vs defocus amount:" )print ("=" *60 )defocus_ums = np.linspace(-1.0 , 1.0 , 21 ) * 0.530 results = [] for Cd_um in defocus_ums: Cd = Cd_um * UM_TO_M psf_A, _, _ = simulate_defocus_method_A(zernike_zero, Cd, pad=pad_size) psf_B, _, _, _ = simulate_defocus_method_B(zernike_zero, Cd, pad=pad_size) psf_A_n = psf_A / psf_A.max () psf_B_n = psf_B / psf_B.max () diff = np.abs (psf_A_n - psf_B_n) mae_val = diff.mean() rmse_val = np.sqrt(np.mean(diff**2 )) results.append((Cd_um, mae_val, rmse_val)) print (f" Cd={Cd_um:+.3 f} um MAE={mae_val:.8 f} RMSE={rmse_val:.8 f} " ) results = np.array(results) fig2, ax2 = plt.subplots(1 , 1 , figsize=(8 , 5 )) ax2.plot(results[:, 0 ], results[:, 1 ], 'bo-' , label='MAE' , markersize=4 ) ax2.plot(results[:, 0 ], results[:, 2 ], 'rs-' , label='RMSE' , markersize=4 ) ax2.axvline(x=-0.1937 , color='lime' , linestyle='--' , alpha=0.7 , label='Trained Cd=-0.1937um' ) ax2.set_xlabel("Zernike defocus Cd (um)" ) ax2.set_ylabel("PSF difference" ) ax2.set_title("Method A vs Method B error" ) ax2.legend() ax2.grid(True , alpha=0.3 ) ax2.set_yscale('log' ) plt.tight_layout() plt.savefig('defocus_sweep_error_v2.png' , dpi=200 , bbox_inches='tight' ) print ("Saved: defocus_sweep_error_v2.png" )np.random.seed(42 ) zernike_random = np.random.randn(zernikePol.shape[1 ]) * 0.05 zernike_random[1 ] = 0.0 Cd_rand = -0.1937 * UM_TO_M psf_A_rand, _, _ = simulate_defocus_method_A(zernike_random, Cd_rand, pad=pad_size) psf_B_rand, _, _, _ = simulate_defocus_method_B(zernike_random, Cd_rand, pad=pad_size) psf_A_rand_n = psf_A_rand / psf_A_rand.max () psf_B_rand_n = psf_B_rand / psf_B_rand.max () diff_rand = np.abs (psf_A_rand_n - psf_B_rand_n) mae_rand = diff_rand.mean() rmse_rand = np.sqrt(np.mean(diff_rand**2 )) print ("\n" + "=" *60 )print (f"With random aberrations (Cd=-0.1937um): MAE={mae_rand:.8 f} , RMSE={rmse_rand:.8 f} " )print ("=" *60 )fig3, axes3 = plt.subplots(1 , 3 , figsize=(14 , 4 )) vmax_r = max (psf_A_rand_n.max (), psf_B_rand_n.max ()) axes3[0 ].imshow(psf_A_rand_n, cmap='hot' , vmin=0 , vmax=vmax_r) axes3[0 ].set_title("Method A: Zernike (with aberrations)" ) axes3[0 ].axis('off' ) axes3[1 ].imshow(psf_B_rand_n, cmap='hot' , vmin=0 , vmax=vmax_r) axes3[1 ].set_title("Method B: Fresnel (with aberrations)" ) axes3[1 ].axis('off' ) im3 = axes3[2 ].imshow(diff_rand, cmap='jet' ) axes3[2 ].set_title(f"Absolute diff |A-B|\nMAE={mae_rand:.6 f} " ) axes3[2 ].axis('off' ) plt.colorbar(im3, ax=axes3[2 ], fraction=0.046 ) plt.tight_layout() plt.savefig('comparison_with_aberrations_v2.png' , dpi=200 , bbox_inches='tight' ) print ("Saved: comparison_with_aberrations_v2.png" )print ("\nAll done." )
光瞳:Mask.mat 的 51 × 51 51\times51 5 1 × 5 1
零填充到 256 × 256 256\times256 2 5 6 × 2 5 6
波长 λ = 530 nm \lambda = 530\,\text{nm} λ = 5 3 0 nm
焦距 f = 1248.158 mm f = 1248.158\,\text{mm} f = 1 2 4 8 . 1 5 8 mm
光瞳直径 D = 60 mm D = 60\,\text{mm} D = 6 0 mm
FFT 使用 ortho 归一化(能量守恒)
9.5.2. C d = − 0.1937 μ m C_d = -0.1937\,\mu\text{m} C d = − 0 . 1 9 3 7 μ m 下图对比了两种方法生成的离焦 PSF:
看图说话:
左图(方法 A) 和 中图(方法 B) 看起来几乎一模一样,都是一个中心亮斑加上外围的同心圆环右图(差异图) 用蓝色表示差异小、红色表示差异大。可以看到大部分区域是深蓝色,说明两者非常接近
定量统计:
指标
数值
含义
全图 MAE
0.0019 0.0019 0 . 0 0 1 9 平均每像素差异不到 0.2%
有效区域 MAE(>1% max)
0.0259 0.0259 0 . 0 2 5 9 在亮斑区域内平均差异约 2.6%
全图 RMSE
0.0156 0.0156 0 . 0 1 5 6 均方根误差约 1.6%
最大差异
0.1931 0.1931 0 . 1 9 3 1 极个别像素差异约 19%
为什么还有微小差异?
离散采样误差 :51 × 51 51\times51 5 1 × 5 1 c 2 = 3.3296 c_2 = 3.3296 c 2 = 3 . 3 2 9 6 3.4641 3.4641 3 . 4 6 4 1 3.9 % 3.9\% 3 . 9 % Δ z \Delta z Δ z FFT 数值精度 :256 点 FFT 的有限精度会引入约 1 0 − 15 10^{-15} 1 0 − 1 5 常数相位的数值处理 :虽然理论上常数相位不影响 PSF,但在数值计算中,e i × 3974 e^{i \times 3974} e i × 3 9 7 4
9.5.3. 我们把 C d C_d C d − 1 λ -1\lambda − 1 λ + 1 λ +1\lambda + 1 λ 0.05 λ 0.05\lambda 0 . 0 5 λ
看图说话:
横轴是 Zernike 离焦系数 C d C_d C d μ m \mu\text{m} μ m
纵轴是两种方法生成 PSF 的差异(对数坐标)
在 C d = 0 C_d = 0 C d = 0
随着离焦量增大,误差缓慢上升
在整个 ± 1 λ \pm 1\lambda ± 1 λ < 0.05 < 0.05 < 0 . 0 5
绿虚线标记了你训练后的实际工作点 C d = − 0.1937 μ m C_d = -0.1937\,\mu\text{m} C d = − 0 . 1 9 3 7 μ m
9.5.4. 为了验证等价性在更复杂情况下是否依然成立,我们给光瞳加入了一些随机的小像差(模拟真实系统中除了离焦之外的其他不完美):
看图说话:
左图和方法 B 的 PSF 都呈现出复杂的斑点结构(因为有随机像差)
但两者的整体形态高度一致
差异图 mostly 是深蓝色,说明差异很小
定量统计:
指标
数值
MAE
0.0030 0.0030 0 . 0 0 3 0
RMSE
0.0069 0.0069 0 . 0 0 6 9
有趣的是,加入随机像差后,两种方法的差异反而更小 了(从 MAE 0.026 0.026 0 . 0 2 6 0.003 0.003 0 . 0 0 3
10. 10.1. 在物理光学中,计算一个光学系统焦平面上的光场分布,通常始于夫琅禾费衍射积分 (Fraunhofer Diffraction Integral)。对于位于透镜前焦面(或光瞳面)的复振幅分布 P ( x , y ) P(x,y) P ( x , y ) U f ( x ′ , y ′ ) U_f(x', y') U f ( x ′ , y ′ ) P ( x , y ) P(x,y) P ( x , y )
U f ( f x , f y ) ∝ ∬ − ∞ + ∞ P ( x , y ) e − i 2 π ( f x x + f y y ) d x d y U_f(f_x, f_y) \propto \iint_{-\infty}^{+\infty} P(x,y) \, e^{-i 2\pi (f_x x + f_y y)} \, dx \, dy
U f ( f x , f y ) ∝ ∬ − ∞ + ∞ P ( x , y ) e − i 2 π ( f x x + f y y ) d x d y
其中:
P ( x , y ) = A ( x , y ) ⋅ e i W ( x , y ) P(x,y) = A(x,y) \cdot e^{i W(x,y)} P ( x , y ) = A ( x , y ) ⋅ e i W ( x , y ) 光瞳函数 (Pupil Function)A ( x , y ) A(x,y) A ( x , y ) W ( x , y ) W(x,y) W ( x , y ) a x + b y ax+by a x + b y f x = x ′ / ( λ f ) f_x = x'/(\lambda f) f x = x ′ / ( λ f ) f y = y ′ / ( λ f ) f_y = y'/(\lambda f) f y = y ′ / ( λ f ) λ \lambda λ f f f
这个积分的物理意义非常深刻:焦平面上的每一点,都是整个光瞳面上所有子波源发出的球面波相干叠加的结果 。透镜的作用,本质上是把远场的夫琅禾费衍射图样聚焦到了它的后焦平面上,从而把原本需要传播很远距离才能看到的衍射斑,"压缩"到了焦平面附近。
10.1.1. 连续傅里叶变换是一个无穷积分 ,涉及连续函数和无限域。计算机无法直接处理无穷和连续,因此必须进行三重离散化:
物理现实
数值计算
引入的代价
连续空间 ( x , y ) ∈ R 2 (x,y) \in \mathbb{R}^2 ( x , y ) ∈ R 2
离散采样网格 ( x n , y m ) (x_n, y_m) ( x n , y m )
采样定理约束 :空间细节必须被足够密的网格捕捉
积分限无穷大
有限求和(N × N N \times N N × N
截断误差 :用有限区域近似无穷积分
直接积分 O ( N 4 ) O(N^4) O ( N 4 )
快速傅里叶变换(FFT)O ( N 2 log N ) O(N^2 \log N) O ( N 2 log N )
周期延拓假设 :DFT 的数学根基
当我们写下:
1 U_f = torch.fft.fft2(pupil_complex)
我们实际上是在计算二维离散傅里叶变换(2D-DFT) :
U f [ k , l ] = ∑ n = 0 N − 1 ∑ m = 0 N − 1 P [ n , m ] e − i 2 π ( k n N + l m N ) U_f[k,l] = \sum_{n=0}^{N-1} \sum_{m=0}^{N-1} P[n,m] \, e^{-i 2\pi \left(\frac{kn}{N} + \frac{lm}{N}\right)}
U f [ k , l ] = n = 0 ∑ N − 1 m = 0 ∑ N − 1 P [ n , m ] e − i 2 π ( N k n + N l m )
这个公式在数学上是对 CFT 的黎曼和近似 。当采样足够密(满足奈奎斯特采样定理)、网格足够大时,DFT 的结果可以收敛到 CFT 的结果。
10.2. 10.2.1. 在真实物理中,光瞳函数 P ( x , y ) P(x,y) P ( x , y ) 紧支集(Compact Support) :光瞳内(透镜口径范围内)有光场分布,光瞳外严格为 0。
这不是数值近似,而是物理现实。 透镜的边框、镜筒、光阑(Aperture Stop)把光挡住了。光瞳外没有光能参与成像。因此,真实的夫琅禾费衍射积分虽然在形式上写成了 ∫ − ∞ + ∞ \int_{-\infty}^{+\infty} ∫ − ∞ + ∞ P ( x , y ) P(x,y) P ( x , y )
U f ( f x , f y ) ∝ ∬ 光瞳 P ( x , y ) e − i 2 π ( f x x + f y y ) d x d y U_f(f_x, f_y) \propto \iint_{\text{光瞳}} P(x,y) \, e^{-i 2\pi (f_x x + f_y y)} \, dx \, dy
U f ( f x , f y ) ∝ ∬ 光瞳 P ( x , y ) e − i 2 π ( f x x + f y y ) d x d y
这是一个紧支集函数的连续傅里叶变换 。从数学分析可知,紧支集光滑函数的傅里叶变换是整函数(Entire Function) ,在频域上是无限延伸且无限可微的,没有任何周期性。
10.2.2. 离散傅里叶变换的公式定义在周期序列 上。DFT 从不"认识"有限序列,它只认识周期为 N N N
X [ k ] = ∑ n = 0 N − 1 x [ n ] e − i 2 π k n / N X[k] = \sum_{n=0}^{N-1} x[n] \, e^{-i 2\pi kn/N}
X [ k ] = n = 0 ∑ N − 1 x [ n ] e − i 2 π k n / N
这个公式的隐含前提是:输入序列 x [ n ] x[n] x [ n ] N N N 。换句话说,DFT 计算的不是"一个有限图像的频谱",而是这个图像作为无限周期瓷砖阵列的一个周期单元的离散频谱 。
这意味着:
空间域周期化 :你的 N × N N \times N N × N 频率域周期化 :输出的频谱也是周期为 N N N
周期延拓不是你可以通过某种参数"关闭"的选项,它是你用 FFT 这个工具时必须接受的数学现实。 FFT 算法之所以能达到 O ( N 2 log N ) O(N^2 \log N) O ( N 2 log N ) O ( N 4 ) O(N^4) O ( N 4 )
10.2.3. DFT 的基函数是复指数函数 e − i 2 π k n / N e^{-i 2\pi kn/N} e − i 2 π k n / N
换句话说,当你使用 FFT 时,你已经在数学上"签约"接受了周期世界。紧支集的物理现实,必须在这个周期框架内被重建 出来,而不是被直接施加。
10.3. 既然周期延拓不可消除,那么如何让它对真实物理的干扰最小化?答案就是零填充(Zero-Padding) 。
10.3.1. 零填充的操作极其简单:把原本大小为 D × D D \times D D × D N × N N \times N N × N N > D N > D N > D
1 2 3 4 5 6 7 padded = torch.zeros(N, N, dtype=torch.complex64, device=device) start = (N - D) // 2 padded[start:start+D, start:start+D] = pupil_complex U_f = torch.fft.fftshift(torch.fft.fft2(padded, norm='ortho' ))
在数学上,这等价于对原始光瞳函数 P ( x , y ) P(x,y) P ( x , y ) 上采样(Upsampling) ——即在更细的频率网格上计算其傅里叶变换。从卷积定理的角度看,零填充后的 DFT 输出,是原始光瞳 DFT 与 sinc 函数的卷积,但由于零填充增加了采样密度,这个 sinc 函数在频域上被压缩,从而更精确地采样了真实的连续频谱 。
10.3.2. 考虑不做零填充的情况:光瞳填满整个 N × N N \times N N × N 硬截断跳变 :
1 2 3 4 5 周期单元(光瞳填满网格): [ ████ ] [ ████ ] [ ████ ] [ ████ ] [ ████ ] [ ████ ] ↑ 边界跳变:光瞳右边缘的值直接拼接左边缘的值
如果光瞳在边界处不是周期连续的(例如圆形光瞳被方形网格截断),这种跳变在数学上是一个不连续函数 ,其傅里叶变换会产生严重的吉布斯现象(Gibbs Phenomenon)和 频谱泄漏(Spectral Leakage) 。此时 FFT 计算的不是"单个孔径的衍射",而是无限大周期孔径阵列(Periodic Aperture Array)的衍射 ——这在物理上完全错误。
而做了零填充之后:
1 2 3 4 5 6 周期单元(光瞳只占网格中心一小部分): [ 000000000000000 ] [ 000 光瞳 0000 ] [ 000000000000000 ] ↑ 边界跳变:0 与 0 相接,没有不连续
此时,周期延拓的相邻"瓷砖"之间被大量 0 隔开,拼接处是 0 与 0 相接 ,没有任何跳变不连续。在这个巨大的周期单元内部,光瞳被 0 包围,数学上完美复现了"紧支集"的物理图景 。
周期延拓引入的"假邻居"被推到很远的地方,其频谱泄漏主要落在高频区域,而你的有效频带内几乎不受影响。
10.3.3. 这是一个常见的误解:零填充能提高分辨率吗?
不能。 零填充不会增加任何物理上不存在的信息,也不会突破衍射极限。光学系统的物理分辨率(瑞利判据)由光瞳口径 D D D λ \lambda λ
Δ x ≈ 1.22 λ f D \Delta x \approx 1.22 \frac{\lambda f}{D}
Δ x ≈ 1 . 2 2 D λ f
零填充改变不了这个极限。它改善的是数值采样精度 :
不做零填充(即使不做0填充,实际上圆形光瞳外还是有0填充的,也会有一个被污染的艾里斑) :FFT 输出可能只采样了 sinc/Airy 函数的 3~4 个点,峰值位置可能被网格量化误差偏移,旁瓣结构扭曲。做零填充 (在数学上逼近了紧支集假设):同一个衍射斑被采样了几十甚至上百个点,峰值位置更准确,旁瓣的对称性和深度更干净,能量守恒更容易满足。
10.3.4. 为了直观展示零填充对仿真精度的影响,下面是同一组波前(原始尺寸 51 × 51 51\times51 5 1 × 5 1
将波前零填充至 256 × 256 256\times256 2 5 6 × 2 5 6
不做零填充(原始 51 × 51 51\times51 5 1 × 5 1
10.3.5.
填充倍数
光瞳占网格比例
适用场景
1× (不填充)100%
仅用于快速测试,会引入严重混叠
2× 25%
快速估算,混叠基本可控,旁瓣可见
4× 6.25%
标准精度 ,旁瓣干净,能量守恒良好
8× 1.56%
极高精度,或光瞳边缘相位变化剧烈(如高阶像差)
经验法则:如果你看到焦平面的 PSF 在边缘处有奇怪的振荡,或者总能量在正逆变换后不守恒,通常就是零填充不够。
10.3.6. torch.fft.fft2 的 norm 参数决定了正逆变换的归一化方式:
norm='backward'(默认):正变换不归一化,逆变换除以 N 2 N^2 N 2 norm='ortho'(推荐):正逆变换都除以 N N N 1 / N 2 1/\sqrt{N^2} 1 / N 2
在光学仿真中,能量守恒通常是重要的物理约束(光瞳内的总功率应等于焦平面上的总功率),因此推荐使用 norm='ortho'。
这里你 pad 了之后并不会影响最终仿真图像的大小,因为 pad 只是让频域的采样点更密(频率分辨率更高),它并不改变 FFT 能分析到的最大频率。真正决定最大频率的是光瞳面的采样率 Δ x \Delta x Δ x Δ x \Delta x Δ x Δ x \Delta x Δ x
量
不 padding(N 1 N_1 N 1
Padding 4×(N 2 = 4 N 1 N_2=4N_1 N 2 = 4 N 1
是否改变
光瞳采样间隔 Δ x \Delta x Δ x Δ x \Delta x Δ x Δ x \Delta x Δ x ❌ 不变
频域总宽度 1 / Δ x 1/\Delta x 1 / Δ x 1 / Δ x 1/\Delta x 1 / Δ x 1 / Δ x 1/\Delta x 1 / Δ x ❌ 不变
焦平面总视场 λ f / Δ x \lambda f/\Delta x λ f / Δ x FOV
FOV
❌ 不变
频率步长 Δ f = 1 / ( N Δ x ) \Delta f = 1/(N\Delta x) Δ f = 1 / ( N Δ x ) 1 / L 1 1/L_1 1 / L 1 1 / L 2 = 1 / ( 4 L 1 ) 1/L_2 = 1/(4L_1) 1 / L 2 = 1 / ( 4 L 1 ) ✅ 变密 4 倍
焦平面像素大小 λ f ⋅ Δ f \lambda f \cdot \Delta f λ f ⋅ Δ f p 1 p_1 p 1 p 2 = p 1 / 4 p_2 = p_1/4 p 2 = p 1 / 4 ✅ 变小 4 倍
输出数组像素数 N 1 N_1 N 1 N 2 = 4 N 1 N_2 = 4N_1 N 2 = 4 N 1 ✅ 变多 4 倍
总物理尺寸 N ⋅ p N \cdot p N ⋅ p N 1 p 1 = FOV N_1 p_1 = \text{FOV} N 1 p 1 = FOV N 2 p 2 = 4 N 1 ⋅ ( p 1 / 4 ) = FOV N_2 p_2 = 4N_1 \cdot (p_1/4) = \text{FOV} N 2 p 2 = 4 N 1 ⋅ ( p 1 / 4 ) = FOV ❌ 不变
10.4. 10.4.1. 在几何光学(射线光学,Ray Optics)中,一个倾斜的平行平面波被理想透镜汇聚后,会在焦平面上形成一个 几何点 ,其位置仅由倾斜角决定:
x f ∝ a , y f ∝ b x_f \propto a, \quad y_f \propto b
x f ∝ a , y f ∝ b
如果截取平面波的中间一部分(通过有限口径),几何光学的结论是:焦点位置不变,只是参与聚焦的光线数量减少,因此像点光强减弱。
这个直觉在工程上非常有用,它是波动光学在波长 λ → 0 \lambda \to 0 λ → 0 。当孔径远大于波长时,衍射斑非常小,肉眼或常规仪器看来就像一个"点"。
10.4.2. 但在**波动光学(Wave Optics)**中,有限孔径的衍射效应不可忽略。被透镜口径截断的倾斜平面波,其数学形式是:
P ( x , y ) = rect ( r D ) ⋅ e i ( a x + b y ) P(x,y) = \text{rect}\left(\frac{r}{D}\right) \cdot e^{i(ax+by)}
P ( x , y ) = rect ( D r ) ⋅ e i ( a x + b y )
根据卷积定理 ,它的傅里叶变换是孔径函数的变换与平面波变换的卷积:
F { P } = F { rect } ∗ F { e i ( a x + b y ) } = [ D 2 ⋅ sinc ( D f x ) sinc ( D f y ) ] ∗ δ ( f x − a 2 π , f y − b 2 π ) \mathcal{F}\{P\} = \mathcal{F}\{\text{rect}\} * \mathcal{F}\{e^{i(ax+by)}\} = \left[D^2 \cdot \text{sinc}(D f_x) \text{sinc}(D f_y)\right] * \delta\left(f_x - \frac{a}{2\pi}, f_y - \frac{b}{2\pi}\right)
F { P } = F { rect } ∗ F { e i ( a x + b y ) } = [ D 2 ⋅ sinc ( D f x ) sinc ( D f y ) ] ∗ δ ( f x − 2 π a , f y − 2 π b )
这意味着:理想点被孔径的 sinc 函数"涂抹"开了 。焦平面上的光场不是一个点,而是一个中心偏移的 sinc 函数 (矩形光瞳)或 Airy 斑 (圆形光瞳)。
10.4.3. 从惠更斯-菲涅尔原理(Huygens-Fresnel Principle)看,焦平面上任意一点的光场,是 整个孔径上所有子波源发出的球面子波相干叠加 的结果。
当你把孔径截断时,你不是简单地"扔掉一些光线"(几何光学视角),而是删除了一大批参与干涉的相干子波源 。这些被移除的子波源原本负责在焦平面周围形成精确的相位抵消——它们定义了"理想点"的边界。它们消失后,能量就从中心峰值泄漏到了周围区域,形成旁瓣。
这不是"补充 0 带来的数值干扰",而是物理衍射 ——即使你用解析积分而不是 FFT,结果也是 sinc 斑。零填充只是让 FFT 更准确地计算这个 sinc 斑,而不是引入它。
10.4.4. 要在物理上真正得到理想的几何点,需要同时满足两个不可实现 的条件:
无限大的平面波 :波前完全平坦,无边界截断,在全空间 R 2 \mathbb{R}^2 R 2 e i ( a x + b y ) e^{i(ax+by)} e i ( a x + b y ) 无限大的透镜/光学系统 :没有任何口径限制,能接收无限大波前的全部能量。
只要其中任何一个变成有限,结果就立即退化为有限孔径衍射 。
所以,"无限平面波聚焦为理想点"是一个数学极限,物理上永远无法实现。 任何真实光学系统(望远镜、镜头、人眼、显微镜)的焦平面上,你看到的永远是衍射斑,只是大小不同:
大望远镜(口径数米):Airy 斑可能只有几微米,但绝不是 0 尺寸。
小孔径:衍射非常明显(如针孔相机、手机镜头夜景的星芒)。
10.5. 当我们写下 torch.fft.fft2(pupil_complex) 时,我们实际上同时操作着三个层面:
代码层 :一个高效的矩阵运算,利用 FFT 算法在毫秒级完成数百万点的变换。
数学层 :一个周期序列的离散傅里叶级数系数计算。DFT 的基函数——复指数 e − i 2 π k n / N e^{-i 2\pi kn/N} e − i 2 π k n / N
物理层 :光波穿过有限孔径后,在远场形成的带有衍射极限的干涉图样。透镜的有限口径就是物理光阑,光瞳外严格为 0。紧支集、有限能量、边界衍射,这些是物理现实强加给我们的约束。
数值光学工程的核心智慧,不在于消除数学与物理之间的张力——这种张力是内禀的、不可消除的——而在于深刻理解张力双方的结构,并用精巧的技巧(零填充、过采样、正交归一化)在数学框架内重建物理真实 。
几何光学给了我们简洁而强大的直觉:光线汇聚于一点。波动光学则提醒我们:只要孔径有限、波长非零,世界就永远是模糊的。衍射不是计算的缺陷,不是 FFT 的伪影,而是光的内禀属性 ——它是光作为波的最诚实告白。
“光在传播时,每一寸边界都在诉说它的存在。你无法截断一束波而不留下痕迹,正如你无法在时空中划定边界而不产生涟漪。”
11. 11.1. 11.1.1. 当信号 f ( x ) f(x) f ( x )
正变换:
f ^ ( ξ ) = ∫ − ∞ ∞ f ( x ) e − 2 π i x ξ d x \hat{f}(\xi) = \int_{-\infty}^{\infty} f(x) \, e^{-2\pi i x \xi} \, dx
f ^ ( ξ ) = ∫ − ∞ ∞ f ( x ) e − 2 π i x ξ d x
逆变换:
f ( x ) = ∫ − ∞ ∞ f ^ ( ξ ) e 2 π i x ξ d ξ f(x) = \int_{-\infty}^{\infty} \hat{f}(\xi) \, e^{2\pi i x \xi} \, d\xi
f ( x ) = ∫ − ∞ ∞ f ^ ( ξ ) e 2 π i x ξ d ξ
这是理论最完美的情况:时域无限,频域连续。但现实中,我们永远无法处理无限长的信号。
11.1.2. 有限区间:两条截然不同的路径 当信号仅在 [ a , b ] [a, b] [ a , b ]
路径 A:紧支集假设(Truncation)
直接将积分限改为有限区间,假设信号在区间外严格为零 :
f ^ ( ξ ) = ∫ a b f ( x ) e − 2 π i x ξ d x \hat{f}(\xi) = \int_{a}^{b} f(x) \, e^{-2\pi i x \xi} \, dx
f ^ ( ξ ) = ∫ a b f ( x ) e − 2 π i x ξ d x
频谱特征 :连续的、解析的(无限可微),呈现 sinc 函数型振荡逆变换结果 :若使用完整频谱 f ^ ( ξ ) \hat{f}(\xi) f ^ ( ξ ) ξ ∈ ( − ∞ , ∞ ) \xi \in (-\infty, \infty) ξ ∈ ( − ∞ , ∞ ) [ a , b ] [a,b] [ a , b ] 物理意义 :适用于瞬态信号(如脉冲、衰减振动)
关于为什么叫紧支集的解释:函数的支集 (函数值不为零的所有点的闭包 )本身就是一个紧集
(在 R n \mathbb{R}^n R n 有界闭集 ),意味着非零区域被限制在一个有限且封闭的范围内,外部恒为零。
路径 B:周期延拓(Periodic Extension)
将有限区间视为周期信号的一个周期,使用傅里叶级数 :
f ( x ) = ∑ n = − ∞ ∞ c n e i 2 π T n x , c n = 1 T ∫ − T / 2 T / 2 f ( x ) e − i 2 π T n x d x f(x) = \sum_{n=-\infty}^{\infty} c_n \, e^{i \frac{2\pi}{T}nx}, \quad c_n = \frac{1}{T}\int_{-T/2}^{T/2} f(x) \, e^{-i \frac{2\pi}{T}nx} \, dx
f ( x ) = n = − ∞ ∑ ∞ c n e i T 2 π n x , c n = T 1 ∫ − T / 2 T / 2 f ( x ) e − i T 2 π n x d x
频谱特征 :离散 的频率点 ξ n = n / T \xi_n = n/T ξ n = n / T 逆变换结果 :周期函数,在区间外循环重复 原波形物理意义 :适用于 inherently 周期的现象(如声波、交流电)
这里两种方式都是有限区间内的积分,只是一个除以了区间长度,一个没有除,为什么就有定义域外默认为0,和定义域外默认为周期延拓的区别?
11.1.2.1. 两种方法确实都在有限区间上积分,区别似乎只是归一化因子 1 / T 1/T 1 / T 单位换算的技术细节 ,真正决定延拓行为的,是两种方法选用的**基函数(Basis Functions)**具有根本不同的数学属性。
路径 A(傅里叶变换)的基函数:
e − 2 π i x ξ , ξ ∈ R e^{-2\pi i x \xi}, \quad \xi \in \mathbb{R}
e − 2 π i x ξ , ξ ∈ R
这些基函数是非周期的平面波 ,在 ∣ x ∣ → ∞ |x| \to \infty ∣ x ∣ → ∞
f ( x ) = ∫ − ∞ ∞ f ^ ( ξ ) e 2 π i x ξ d ξ f(x) = \int_{-\infty}^{\infty} \hat{f}(\xi) e^{2\pi i x\xi} \, d\xi
f ( x ) = ∫ − ∞ ∞ f ^ ( ξ ) e 2 π i x ξ d ξ
本质上是用无限多个无限延伸的平面波来合成原信号。要使这个合成结果在 [ a , b ] [a,b] [ a , b ] 精确为零 (紧支集),需要所有基波在区间外通过相位干涉完美相消——这要求频谱 f ^ ( ξ ) \hat{f}(\xi) f ^ ( ξ ) 紧支集特性是频谱分析的结果,而非随意假设 。
路径 B(傅里叶级数)的基函数:
e i 2 π T n x , n ∈ Z e^{i \frac{2\pi}{T} n x}, \quad n \in \mathbb{Z}
e i T 2 π n x , n ∈ Z
这些基函数天生具有周期 T T T :
e i 2 π T n ( x + T ) = e i 2 π T n x e^{i \frac{2\pi}{T} n (x+T)} = e^{i \frac{2\pi}{T} n x}
e i T 2 π n ( x + T ) = e i T 2 π n x
无论系数 c n c_n c n
f ( x + T ) = f ( x ) f(x+T) = f(x)
f ( x + T ) = f ( x )
因此,当你写出:
f ( x ) = ∑ n = − ∞ ∞ c n e i 2 π T n x f(x) = \sum_{n=-\infty}^{\infty} c_n e^{i \frac{2\pi}{T} n x}
f ( x ) = n = − ∞ ∑ ∞ c n e i T 2 π n x
周期性已经内禀地蕴含在基函数之中 ,不是可选项,而是数学必然。
11.1.2.2. 问题的关键在于:当你写下有限区间的积分时,你正在对什么对象做积分?
紧支集方法 :函数 f f f R \mathbb{R} R ∫ a b \int_a^b ∫ a b ∫ − ∞ ∞ \int_{-\infty}^\infty ∫ − ∞ ∞ 偷懒写法 ,因为 f ( x ) f(x) f ( x ) [ a , b ] [a,b] [ a , b ] 已经被定义为零 。数学表述:f ∈ L 2 ( R ) f \in L^2(\mathbb{R}) f ∈ L 2 ( R ) supp ( f ) ⊆ [ a , b ] \text{supp}(f) \subseteq [a,b] supp ( f ) ⊆ [ a , b ] "区间外为零"是前提假设 ,积分只是验证这个假设的副产品。
周期延拓方法 :函数 f f f T T \mathbb{T}_T T T T T T R \mathbb{R} R f ( x + T ) = f ( x ) f(x+T)=f(x) f ( x + T ) = f ( x ) ∫ − T / 2 T / 2 \int_{-T/2}^{T/2} ∫ − T / 2 T / 2 圆环上的一个 Fundamental Domain(基本域)上积分,不是在"实数轴的一个区间"上积分。数学表述:f ∈ L 2 ( T T ) f \in L^2(\mathbb{T}_T) f ∈ L 2 ( T T ) x + T x+T x + T 就是 x x x "周期重复"是定义域的内在结构 ,不是延拓出来的。
特征
紧支集方法
周期延拓方法
函数生活在哪里 实数轴 R \mathbb{R} R
圆环 T T \mathbb{T}_T T T
积分含义 截断整个实数轴(外面已经没东西了)
遍历整个圆环(选一个代表元区间)
f ( 0 ) f(0) f ( 0 ) f ( T ) f(T) f ( T ) 没关系,可能 f ( 0 ) ≠ 0 f(0)\neq 0 f ( 0 ) = 0 f ( T ) = 0 f(T)=0 f ( T ) = 0
f ( 0 ) = f ( T ) f(0) = f(T) f ( 0 ) = f ( T ) 强制性等同 ,因为它们是同一个点
逆变换结果 支集外为 0
支集外周期性复制
11.1.2.3. 当首尾值不相等或者首尾值不等于0时,周期延拓或者紧支都有可能产生不连续性,
从而在频域产生高频分量,但形态不同。
11.1.2.4. 当你只能观测或采集有限长的一段信号(有限时间窗口 T T T D D D 矩形窗 ,而矩形窗的傅里叶变换是一个 sinc 函数 (sin x / x \sin x / x sin x / x
11.1.2.4.1. 透镜的孔径是有限的,相当于空间域的矩形窗。焦平面上的频谱仍然是连续分布 的,你理论上可以读取任意频率点的值,不存在离散的“频率间隔”。
但是,真实频谱已经被孔径的 sinc 谱涂抹了:
一个理想的点光源(空间 delta 函数)成像后,变成一个艾里斑或 sinc 斑 ;
两个靠得很近的空间频率成分,会因主瓣重叠而糊成一片,无法区分。
表现 :没有离散的频率格子,但存在最小可分辨间隔 (瑞利判据),其量级约为 1 / D 1/D 1 / D D D D
11.1.2.4.2. 在数值计算中,你不仅时间有限(T T T N N N N N N
sinc 涂抹的主瓣宽度约为 1 / T 1/T 1 / T
Δ f = 1 T = f s N \Delta f = \frac{1}{T} = \frac{f_s}{N}
Δ f = T 1 = N f s
表现 :频域被强制画成了等间距的离散网格。你看到的不是连续的模糊带,而是只能落在这 N N N 真实分辨率仍然由 1 / T 1/T 1 / T 。
11.1.2.4.3. 1 / T 1/T 1 / T 有限窗口 [ 0 , T ] [0, T] [ 0 , T ] 两个不同频率的复指数信号,在这个区间内是否"独立"?
数学上,"独立"的标准是正交 ——它们的内积必须为零(才能将其区分开)。
11.1.2.4.3.1. 在区间 [ 0 , T ] [0, T] [ 0 , T ]
⟨ e i 2 π f 1 t , e i 2 π f 2 t ⟩ = ∫ 0 T e i 2 π f 1 t ⋅ e − i 2 π f 2 t d t = ∫ 0 T e i 2 π ( f 1 − f 2 ) t d t \langle e^{i2\pi f_1 t},\, e^{i2\pi f_2 t} \rangle = \int_0^T e^{i2\pi f_1 t} \cdot e^{-i2\pi f_2 t} \, dt = \int_0^T e^{i2\pi (f_1 - f_2)t} \, dt
⟨ e i 2 π f 1 t , e i 2 π f 2 t ⟩ = ∫ 0 T e i 2 π f 1 t ⋅ e − i 2 π f 2 t d t = ∫ 0 T e i 2 π ( f 1 − f 2 ) t d t
令 Δ f = f 1 − f 2 \Delta f = f_1 - f_2 Δ f = f 1 − f 2
⟨ e f 1 , e f 2 ⟩ = e i 2 π Δ f T − 1 i 2 π Δ f \langle \mathbf{e}_{f_1}, \mathbf{e}_{f_2} \rangle = \frac{e^{i2\pi \Delta f \, T} - 1}{i2\pi \Delta f}
⟨ e f 1 , e f 2 ⟩ = i 2 π Δ f e i 2 π Δ f T − 1
利用欧拉公式 e i θ − 1 = e i θ / 2 ⋅ 2 i sin ( θ / 2 ) e^{i\theta} - 1 = e^{i\theta/2} \cdot 2i\sin(\theta/2) e i θ − 1 = e i θ / 2 ⋅ 2 i sin ( θ / 2 )
⟨ e f 1 , e f 2 ⟩ = T ⋅ sin ( π Δ f T ) π Δ f T ⋅ e i π Δ f T \langle \mathbf{e}_{f_1}, \mathbf{e}_{f_2} \rangle = T \cdot \frac{\sin(\pi \Delta f \, T)}{\pi \Delta f \, T} \cdot e^{i\pi \Delta f \, T}
⟨ e f 1 , e f 2 ⟩ = T ⋅ π Δ f T sin ( π Δ f T ) ⋅ e i π Δ f T
11.1.2.4.3.2. 两个基向量正交,当且仅当内积为零:
sin ( π Δ f T ) = 0 \sin(\pi \Delta f \, T) = 0
sin ( π Δ f T ) = 0
这要求:
π Δ f T = k π , k = ± 1 , ± 2 , … \pi \Delta f \, T = k\pi, \quad k = \pm 1, \pm 2, \dots
π Δ f T = k π , k = ± 1 , ± 2 , …
即:
Δ f = k T \Delta f = \frac{k}{T}
Δ f = T k
11.1.2.4.3.3. 满足正交的最小非零频率间隔对应 k = 1 k = 1 k = 1
Δ f min = 1 T \boxed{\Delta f_{\min} = \frac{1}{T}}
Δ f min = T 1
这意味着:在有限窗口 [ 0 , T ] [0, T] [ 0 , T ] 1 / T 1/T 1 / T
11.1.2.4.3.4. 傅里叶分析是线性投影 :把信号往各个频率基向量上投影,投影系数就是该频率的幅度。
若基向量正交 (Δ f ≥ 1 / T \Delta f \geq 1/T Δ f ≥ 1 / T 独立、唯一 地提取。
若基向量不正交 (Δ f < 1 / T \Delta f < 1/T Δ f < 1 / T sin ( π Δ f T ) π Δ f T \frac{\sin(\pi \Delta f T)}{\pi \Delta f T} π Δ f T sin ( π Δ f T ) 平行 。此时:
10 Hz 的投影里混入了 10.05 Hz 的能量;
10.05 Hz 的投影里也混入了 10 Hz 的能量;
逆问题病态,存在无穷多组系数都能同样好地解释同一段数据。
11.1.2.4.3.5. DFT 选取的频率点正是:
f k = k T , k = 0 , 1 , … , N − 1 f_k = \frac{k}{T}, \quad k = 0, 1, \dots, N-1
f k = T k , k = 0 , 1 , … , N − 1
这不是人为设定,而是这套基函数在 [ 0 , T ] [0, T] [ 0 , T ] 。相邻谱线的间隔恰好是 1 / T 1/T 1 / T
低于这个间隔的频率对,因为基向量不正交,DFT 无法将它们独立分辨——能量会泄漏、重叠、混为一谈。
11.1.2.4.4. 有限采样空间触发的 sinc 涂抹,是连续和离散情况下的共同根源。连续 FT 让你看到涂抹后的连续模糊;DFT 则把这个模糊采样成了间距为 1 / T 1/T 1 / T ——两者都逃不开 Δ t ⋅ Δ f ∼ 1 \Delta t \cdot \Delta f \sim 1 Δ t ⋅ Δ f ∼ 1
离散傅里叶变换 (DFT)
连续傅里叶变换 (如光学透镜)
有限窗口的数学作用 对无限信号加矩形窗,取 N N N
对波前加有限孔径 P ( x , y ) P(x,y) P ( x , y )
频域效应 与 sinc 函数(Dirichlet核)卷积后,只采样离散频点
与 sinc 函数(或艾里斑)卷积,频域仍是连续的
表现形式 频率间隔(Frequency Spacing) Δ f = 1 / T \Delta f = 1/T Δ f = 1 / T 频谱展宽 / 衍射极限 δ \delta δ
分辨极限 频率分辨率受限,谱泄漏
瑞利判据:两点刚好可分辨的最小角间距
11.1.3. 当我们将连续信号数字化时,面临两个操作:时域采样 和 频域采样 。这两个操作对应着对偶的周期化效应。
11.1.3.1. 对连续信号 f ( t ) f(t) f ( t ) T s T_s T s x [ n ] = f ( n T s ) x[n] = f(nT_s) x [ n ] = f ( n T s )
X ( ω ) = ∑ n = − ∞ ∞ x [ n ] e − i ω n X(\omega) = \sum_{n=-\infty}^{\infty} x[n] \, e^{-i\omega n}
X ( ω ) = n = − ∞ ∑ ∞ x [ n ] e − i ω n
这是离散时间傅里叶变换(DTFT)。注意到 ω \omega ω 2 π 2\pi 2 π ω + 2 π \omega + 2\pi ω + 2 π 2 π 2\pi 2 π
11.1.3.2. 工程中最常用的 DFT,实际上是对 DTFT 的频域采样:
X [ k ] = ∑ n = 0 N − 1 x [ n ] e − i 2 π N k n , k = 0 , 1 , … , N − 1 X[k] = \sum_{n=0}^{N-1} x[n] \, e^{-i\frac{2\pi}{N}kn}, \quad k = 0, 1, \ldots, N-1
X [ k ] = n = 0 ∑ N − 1 x [ n ] e − i N 2 π k n , k = 0 , 1 , … , N − 1
DFT 隐含的数学假设 :
时域周期 :x [ n ] = x [ n + N ] x[n] = x[n + N] x [ n ] = x [ n + N ] N N N 频域周期 :X [ k ] = X [ k + N ] X[k] = X[k + N] X [ k ] = X [ k + N ]
这与"截断"有本质区别! 如果你有一段信号 [ 1 , 2 , 3 , 4 ] [1, 2, 3, 4] [ 1 , 2 , 3 , 4 ] … , 1 , 2 , 3 , 4 , 1 , 2 , 3 , 4 , 1 , 2 , 3 , 4 , … \ldots, 1,2,3,4,1,2,3,4,1,2,3,4, \ldots … , 1 , 2 , 3 , 4 , 1 , 2 , 3 , 4 , 1 , 2 , 3 , 4 , … … , 0 , 0 , 1 , 2 , 3 , 4 , 0 , 0 , … \ldots,0,0,1,2,3,4,0,0,\ldots … , 0 , 0 , 1 , 2 , 3 , 4 , 0 , 0 , …
11.1.4.
变换类型
时域特征
频域特征
数学假设
适用场景
边界/周期特性
连续傅里叶变换 (CFT) 连续,无限区间 ( − ∞ , ∞ ) (-\infty, \infty) ( − ∞ , ∞ )
连续,无限区间
绝对可积
理论分析
无周期假设
有限区间 FT(截断) 连续,有限 [ a , b ] [a,b] [ a , b ] 区间外为 0
连续,无限
紧支集
瞬态信号分析
区间外严格零值
傅里叶级数 (FS) 连续,周期延拓
离散 谱线 ξ n = n / T \xi_n = n/T ξ n = n / T 周期函数
周期振动、谐波分析
区间外周期重复
离散时间 FT (DTFT) 离散采样 ,无限长连续,周期 2 π 2\pi 2 π
时域离散
数字滤波器设计
频域自然周期化
离散傅里叶变换 (DFT) 离散 + 周期延拓 (N N N 离散 + 周期 (N N N 双重周期 FFT 实现、数字信号处理
时域首尾相连,循环卷积
12. 12.1. 12.1.1. 设 I 0 ( x , y ) I_0(x,y) I 0 ( x , y ) I d ( x , y ) I_d(x,y) I d ( x , y )
S 0 ( u , v ) = F { I 0 } , S d ( u , v ) = F { I d } S_0(u,v) = \mathcal{F}\{I_0\}, \quad S_d(u,v) = \mathcal{F}\{I_d\}
S 0 ( u , v ) = F { I 0 } , S d ( u , v ) = F { I d }
M4 定义为功率谱比值:
M 4 ( u , v ) = ∣ S 0 ( u , v ) ∣ 2 − ∣ S d ( u , v ) ∣ 2 ∣ S 0 ( u , v ) ∣ 2 + ∣ S d ( u , v ) ∣ 2 M_4(u,v) = \frac{|S_0(u,v)|^2 - |S_d(u,v)|^2}{|S_0(u,v)|^2 + |S_d(u,v)|^2}
M 4 ( u , v ) = ∣ S 0 ( u , v ) ∣ 2 + ∣ S d ( u , v ) ∣ 2 ∣ S 0 ( u , v ) ∣ 2 − ∣ S d ( u , v ) ∣ 2
12.1.2.
在做基于 M4 metric 的无信标波前重构时,我尝试在 dataset.py 里把图像背景(灰度值约 130)减掉,结果测试 RMS 从 0.16 涨到了 0.22 。深入排查后发现:不是背景不该减,而是我的数据增强 pipeline 与“绝对灰度值”强耦合 ,减去背景后,RandomShiftWithPad0、RandomErasing 等操作几乎失效,导致训练正则化不足、泛化变差。
预处理方式
最佳 Test RMS
不减背景 (image / 4096.0)~0.16
减去背景 130 ((image - 130) / 4096.0)
~0.22
从 log 里可以清晰看到,减去背景的模型在第 6 个 epoch 后就开始过拟合,test_rms 停止下降甚至反弹;而不减背景的模型收敛得更平稳,最终 RMS 明显更低。
这让我非常困惑:背景不是噪声吗?为什么去掉噪声反而变差?
12.1.2.1. 12.1.2.1.1. 先回到物理本质。M4 metric 的定义是:
M 4 = ∣ S o ∣ 2 − ∣ S d ∣ 2 ∣ S o ∣ 2 + ∣ S d ∣ 2 M_4 = \frac{|S_o|^2 - |S_d|^2}{|S_o|^2 + |S_d|^2}
M 4 = ∣ S o ∣ 2 + ∣ S d ∣ 2 ∣ S o ∣ 2 − ∣ S d ∣ 2
其中 S o S_o S o S d S_d S d 均匀常数背景 B B B ( 0 , 0 ) (0,0) ( 0 , 0 ) 如果没有后续的数据增强 ,减不减背景,M4 输出在绝大多数频点上应该是完全一样的。
我直接用训练数据验证过:只做 ToTensor 和归一化时,两种情况算出的 M4 均值差异仅有 5 × 1 0 − 6 5\times10^{-6} 5 × 1 0 − 6
所以问题不在 M4 层,而在 M4 层之后的数据增强。
12.1.2.1.2. 我的训练 transform 如下:
1 2 3 4 5 6 transform_train = transforms.Compose([ transforms.ToTensor(), RandomShiftWithPad0(max_shift_h=5 , max_shift_w=5 , p=0.5 ), transforms.ColorJitter(brightness=0 , contrast=1 , saturation=0 , hue=0 ), transforms.RandomErasing(p=0.3 , scale=(0.02 , 0.33 ), ratio=(0.3 , 3.3 ), value=0 ), ])
这三个操作都严重依赖图像的绝对灰度值 ,而减去背景会彻底改变它们的行为:
① RandomShiftWithPad0 —— 平移后补 0
不减背景 :图像背景约为 130 / 4096 ≈ 0.032 130/4096 \approx 0.032 1 3 0 / 4 0 9 6 ≈ 0 . 0 3 2 0 ,会在图像边缘形成明显的“暗边”,引入强烈的频谱扰动。减去背景 :背景被拉到 0 附近。填充 0 等同于填充背景,暗边消失 ,频谱扰动几乎被抹平。
② RandomErasing(value=0) —— 用 0 擦除一块区域
不减背景 :在亮背景上打一块“黑斑”,产生显著的局部频域变化。减去背景 :擦除区域和周围背景灰度几乎一致,擦了个寂寞 ,对网络来说相当于没做增强。
③ ColorJitter(contrast=1) —— 以均值为基准拉伸
不减背景 :均值约为 0.032,对比度拉伸会把“信号+背景”一起放大,保持动态范围变化。减去背景 :均值接近 0,拉伸的幅度和效果都大打折扣。
一句话总结 :减去背景后,数据增强被“阉割”了,训练样本多样性严重不足,模型学不到足够鲁棒的特征,测试性能自然崩塌。
12.1.2.1.3. 更雪上加霜的是,我统计了训练集里 200 个样本的灰度分布:
统计量
数值
像素最小值
118.43 ~ 119.01(平均 118.79)
像素均值
122.58
这说明真实的暗电流/偏置(background)应该在 ~118.8 左右,而不是 130(130是背景的最大值)。强行减 130 会在图像上留下约 -11.2 的残余负偏置,导致:
RandomErasing(value=0) 的“黑斑”变成了相对背景而言的亮斑 ;图像整体出现负值,可能让 BatchNorm 或 ReLU 的分布发生微妙偏移。
12.1.2.1.4. 回头再看参考论文 Phase-diversity wave-front sensor for imaging systems,其中提到的 subtract 出现在噪声分析章节:
“the camera noise can be closely approximated by a decoupled spectrum that will cancel in the numerator. This spectrum can be experimentally determined and also subtracted as a separate term in the denominator .”
注意,这里说的是在 M4 metric 的分母里减去噪声功率谱 (denominator subtraction),是在频域 对功率谱做的操作,绝不是在空域直接减去一个固定灰度值 130 。
12.1.2.2. 为了量化增强失效的程度,我写了一个对比脚本:对同一张训练样本施加完全相同的 平移(5,5)、对比度抖动(factor=1.5)、随机擦除,然后计算 M4。
1 2 3 4 5 6 for sub_bg in [False , True ]: x = apply_transforms(img, sub_bg=sub_bg).unsqueeze(0 ) ... m4 = (power_So - power_Sd) / (power_So + power_Sd + 1e-8 ) print (f"sub={sub_bg} : M4 mean={m4.mean():.4 f} " )
结果:
预处理
M4 均值
不减背景
0.2059
减去背景 130
0.5478
两者 M4 的差异均值达到 -0.34 ,最大单点差异接近 2.0 。
这证实了减去背景操作对数据增广的影响。
这并不能定量度量减去背景对数据增广的影响?为什么?
12.1.2.3. 不是背景不能减,而是你的数据增强策略与“非零背景”共生。 RandomShiftWithPad0、RandomErasing 和 ColorJitter 发挥了最强的正则化作用。
深度学习里的很多“玄学”问题,往往根子都在预处理与增强的耦合 上。这次踩坑让我意识到:
“去掉背景”这个操作在物理上很干净,但在工程实现里,必须考虑整条数据管道的上下文。
12.1.3. 定理 :对于离焦图像对 I 0 I_0 I 0 I d I_d I d
12.1.3.1. 对于长度为 N N N x [ n ] x[n] x [ n ] n = 0 , 1 , … , N − 1 n = 0, 1, \dots, N-1 n = 0 , 1 , … , N − 1
X [ k ] = ∑ n = 0 N − 1 x [ n ] ⋅ e − i 2 π k n / N , k = 0 , 1 , … , N − 1 X[k] = \sum_{n=0}^{N-1} x[n] \cdot e^{-i 2\pi k n / N}, \quad k = 0, 1, \dots, N-1
X [ k ] = n = 0 ∑ N − 1 x [ n ] ⋅ e − i 2 π k n / N , k = 0 , 1 , … , N − 1
关键洞察 :这个公式本身就假设了 x [ n ] x[n] x [ n ] 周期为 N N N 的周期信号,即:
x [ n + N ] = x [ n ] , ∀ n ∈ Z x[n + N] = x[n], \quad \forall n \in \mathbb{Z}
x [ n + N ] = x [ n ] , ∀ n ∈ Z
12.1.3.2. 在周期信号框架下,平移 Δ \Delta Δ
x ′ [ n ] = x [ ( n − Δ ) m o d N ] x'[n] = x[(n - \Delta) \bmod N]
x ′ [ n ] = x [ ( n − Δ ) m o d N ]
这正是 torch.roll 所做的操作。在这个定义下:
平移定理(DFT 版本) :
如果 x [ n ] → DFT X [ k ] x[n] \xrightarrow{\text{DFT}} X[k] x [ n ] DFT X [ k ]
x [ ( n − Δ ) m o d N ] → DFT X [ k ] ⋅ e − i 2 π k Δ / N x[(n-\Delta) \bmod N] \xrightarrow{\text{DFT}} X[k] \cdot e^{-i 2\pi k \Delta / N}
x [ ( n − Δ ) m o d N ] DFT X [ k ] ⋅ e − i 2 π k Δ / N
证明 :
∑ n = 0 N − 1 x [ ( n − Δ ) m o d N ] ⋅ e − i 2 π k n / N = ∑ m = − Δ N − 1 − Δ x [ m m o d N ] ⋅ e − i 2 π k ( m + Δ ) / N ( 令 m = n − Δ ) = e − i 2 π k Δ / N ∑ m = 0 N − 1 x [ m ] ⋅ e − i 2 π k m / N ( 周期求和不变 ) = X [ k ] ⋅ e − i 2 π k Δ / N \begin{aligned}
\sum_{n=0}^{N-1} x[(n-\Delta) \bmod N] \cdot e^{-i 2\pi k n / N}
&= \sum_{m=-\Delta}^{N-1-\Delta} x[m \bmod N] \cdot e^{-i 2\pi k (m+\Delta) / N} \quad (\text{令 } m = n-\Delta) \\
&= e^{-i 2\pi k \Delta / N} \sum_{m=0}^{N-1} x[m] \cdot e^{-i 2\pi k m / N} \quad (\text{周期求和不变}) \\
&= X[k] \cdot e^{-i 2\pi k \Delta / N}
\end{aligned}
n = 0 ∑ N − 1 x [ ( n − Δ ) m o d N ] ⋅ e − i 2 π k n / N = m = − Δ ∑ N − 1 − Δ x [ m m o d N ] ⋅ e − i 2 π k ( m + Δ ) / N ( 令 m = n − Δ ) = e − i 2 π k Δ / N m = 0 ∑ N − 1 x [ m ] ⋅ e − i 2 π k m / N ( 周期求和不变 ) = X [ k ] ⋅ e − i 2 π k Δ / N
12.1.3.3. 取模平方:
∣ X ′ [ k ] ∣ 2 = ∣ X [ k ] ⋅ e − i 2 π k Δ / N ∣ 2 = ∣ X [ k ] ∣ 2 ⋅ ∣ e − i 2 π k Δ / N ∣ 2 = ∣ X [ k ] ∣ 2 |X'[k]|^2 = |X[k] \cdot e^{-i 2\pi k \Delta / N}|^2 = |X[k]|^2 \cdot |e^{-i 2\pi k \Delta / N}|^2 = |X[k]|^2
∣ X ′ [ k ] ∣ 2 = ∣ X [ k ] ⋅ e − i 2 π k Δ / N ∣ 2 = ∣ X [ k ] ∣ 2 ⋅ ∣ e − i 2 π k Δ / N ∣ 2 = ∣ X [ k ] ∣ 2
关键 :因为 e − i θ e^{-i\theta} e − i θ
12.1.3.4. 零填充平移在时域的数学表达:
x z p [ n ] = { x [ ( n − Δ ) m o d N ] if 0 ≤ n < N 0 otherwise x_{zp}[n] = \begin{cases} x[(n-\Delta) \bmod N] & \text{if } 0 \leq n < N \\ 0 & \text{otherwise} \end{cases}
x z p [ n ] = { x [ ( n − Δ ) m o d N ] 0 if 0 ≤ n < N otherwise
但这不是 DFT 框架下的操作!零填充实际上等价于:
12.1.3.4.1. x z p [ n ] = x s h i f t e d [ n ] ⋅ Π [ n ] x_{zp}[n] = x_{shifted}[n] \cdot \Pi[n]
x z p [ n ] = x s h i f t e d [ n ] ⋅ Π [ n ]
其中 Π [ n ] \Pi[n] Π [ n ] n ∈ [ 0 , N − 1 ] n \in [0,N-1] n ∈ [ 0 , N − 1 ]
12.1.3.4.2. 根据卷积定理:
DFT { x z p } = DFT { x s h i f t e d } ⊛ DFT { Π } = ( X [ k ] ⋅ e − i ϕ k ) ⊛ sinc ( k ) \text{DFT}\{x_{zp}\} = \text{DFT}\{x_{shifted}\} \circledast \text{DFT}\{\Pi\} = (X[k] \cdot e^{-i\phi_k}) \circledast \text{sinc}(k)
DFT { x z p } = DFT { x s h i f t e d } ⊛ DFT { Π } = ( X [ k ] ⋅ e − i ϕ k ) ⊛ sinc ( k )
这里 sinc ( k ) = sin ( π k ) π k \text{sinc}(k) = \frac{\sin(\pi k)}{\pi k} sinc ( k ) = π k sin ( π k )
结果 :功率谱被 smear(涂抹):
∣ X z p [ k ] ∣ 2 ≠ ∣ X [ k ] ∣ 2 |X_{zp}[k]|^2 \neq |X[k]|^2
∣ X z p [ k ] ∣ 2 = ∣ X [ k ] ∣ 2
13. 13.1. 在光学模型里,我们经常希望波长能自动调整 ——比如让神经网络自己优化出最佳波长。
但波长有个硬约束:必须是正数,不能为 0,更不能为负。
下面这段代码展示了一个非常巧妙的做法:
1 2 3 4 5 6 7 8 raw_wl = float (init_wavelength_m) if raw_wl > 100e-9 : raw_wl = np.log(np.exp(raw_wl) - 1.0 ) self.raw_wavelength_m = nn.Parameter(torch.tensor(raw_wl)) @property def wavelength_m (self ): return F.softplus(self.raw_wavelength_m) + 1e-12
13.1.1. 假设你的初始波长是 1.0,先做了一道"反向计算":
1 raw_wl = np.log(np.exp(raw_wl) - 1.0 )
这步就是在算暗号 :应该存什么数字,才能让后面解码出来恰好等于原始波长?
打个比方:保险箱规定"取出来的时候自动加 1"。你想最终拿到 500,就不能存 500,得存 499。这步就是在算"499"。
13.1.2. 1 2 3 @property def wavelength_m (self ): return F.softplus(self.raw_wavelength_m) + 1e-12
softplus 的作用很简单:无论你输入什么数字,输出永远是正数。
内部暗号
softplus 输出
10
10.0
0
0.69
-5
0.007
-100
约 0
因为内部暗号可以任意变化(训练时梯度下降会不断更新它),但经过 softplus 一过滤,最终波长永远被锁在正数区间 。
最后的 + 1e-12 只是再加个保险,确保波长不会变成 0,避免后面做除法时崩溃。
13.1.3. 13.1.3.1. 波长不能为负,不能为 0。softplus 在数学上就是一个"单向阀门":进去的是任意实数,出来的永远是正数。
13.1.3.2. nn.Parameter 意味着这个值会被自动优化。优化过程中参数可能变正、变负、变小、变大——内部暗号随便变,没关系 。因为解码器(softplus)会把它"压"成正数。
编码 是为了让初始值不被扭曲;解码 是为了让输出永远合法。
13.2.
背景 :在真实光学系统中采集的在焦/离焦点扩散函数(PSF)往往因为光轴对准误差、探测器安装公差等原因,并不严格位于图像中心 。然而,物理仿真得到的 PSF 默认是以光轴为中心生成的。如果直接在像素空间做 L2/L1 监督,一个微小的平移就会让损失函数爆炸,优化器被迫去"凑"位置而不是真正学习像差和离焦量。
13.2.1. 13.2.1.1. 我们从二维离散傅里叶变换(2D-DFT)的定义 出发,一步一步推导。
对一幅尺寸为 H × W H \times W H × W I ( x , y ) I(x,y) I ( x , y )
F { I } ( u , v ) = ∑ x = 0 W − 1 ∑ y = 0 H − 1 I ( x , y ) e − j 2 π ( u x W + v y H ) \mathcal{F}\{I\}(u,v) = \sum_{x=0}^{W-1} \sum_{y=0}^{H-1} I(x,y) \; e^{-j 2\pi \left(\frac{ux}{W} + \frac{vy}{H}\right)}
F { I } ( u , v ) = x = 0 ∑ W − 1 y = 0 ∑ H − 1 I ( x , y ) e − j 2 π ( W u x + H v y )
其中:
( x , y ) (x,y) ( x , y ) ( u , v ) (u,v) ( u , v ) j j j j 2 = − 1 j^2 = -1 j 2 = − 1
现在,图像发生空间平移 ( x 0 , y 0 ) (x_0, y_0) ( x 0 , y 0 )
I ′ ( x , y ) = I ( x − x 0 , y − y 0 ) I'(x,y) = I(x-x_0,\; y-y_0)
I ′ ( x , y ) = I ( x − x 0 , y − y 0 )
将 I ′ I' I ′
F { I ′ } ( u , v ) = ∑ x = 0 W − 1 ∑ y = 0 H − 1 I ( x − x 0 , y − y 0 ) e − j 2 π ( u x W + v y H ) \mathcal{F}\{I'\}(u,v) = \sum_{x=0}^{W-1} \sum_{y=0}^{H-1} I(x-x_0,\; y-y_0) \; e^{-j 2\pi \left(\frac{ux}{W} + \frac{vy}{H}\right)}
F { I ′ } ( u , v ) = x = 0 ∑ W − 1 y = 0 ∑ H − 1 I ( x − x 0 , y − y 0 ) e − j 2 π ( W u x + H v y )
做变量代换 :令 m = x − x 0 m = x - x_0 m = x − x 0 n = y − y 0 n = y - y_0 n = y − y 0 x = m + x 0 x = m + x_0 x = m + x 0 y = n + y 0 y = n + y_0 y = n + y 0 x x x 0 … W − 1 0 \dots W-1 0 … W − 1 m m m − x 0 … W − 1 − x 0 -x_0 \dots W-1-x_0 − x 0 … W − 1 − x 0 隐含周期性边界条件 I ( x + W , y ) = I ( x , y ) I(x+W, y) = I(x, y) I ( x + W , y ) = I ( x , y )
F { I ′ } ( u , v ) = ∑ m = 0 W − 1 ∑ n = 0 H − 1 I ( m , n ) e − j 2 π ( u ( m + x 0 ) W + v ( n + y 0 ) H ) \mathcal{F}\{I'\}(u,v) = \sum_{m=0}^{W-1} \sum_{n=0}^{H-1} I(m,n) \; e^{-j 2\pi \left(\frac{u(m+x_0)}{W} + \frac{v(n+y_0)}{H}\right)}
F { I ′ } ( u , v ) = m = 0 ∑ W − 1 n = 0 ∑ H − 1 I ( m , n ) e − j 2 π ( W u ( m + x 0 ) + H v ( n + y 0 ) )
将指数项拆开 。利用指数性质 e a + b = e a ⋅ e b e^{a+b} = e^a \cdot e^b e a + b = e a ⋅ e b
F { I ′ } ( u , v ) = ∑ m = 0 W − 1 ∑ n = 0 H − 1 I ( m , n ) e − j 2 π ( u m W + v n H ) ⋅ e − j 2 π ( u x 0 W + v y 0 H ) \mathcal{F}\{I'\}(u,v) = \sum_{m=0}^{W-1} \sum_{n=0}^{H-1} I(m,n) \; e^{-j 2\pi \left(\frac{um}{W} + \frac{vn}{H}\right)} \cdot e^{-j 2\pi \left(\frac{ux_0}{W} + \frac{vy_0}{H}\right)}
F { I ′ } ( u , v ) = m = 0 ∑ W − 1 n = 0 ∑ H − 1 I ( m , n ) e − j 2 π ( W u m + H v n ) ⋅ e − j 2 π ( W u x 0 + H v y 0 )
提取公因子 。观察第二项指数 e − j 2 π ( u x 0 W + v y 0 H ) e^{-j 2\pi \left(\frac{ux_0}{W} + \frac{vy_0}{H}\right)} e − j 2 π ( W u x 0 + H v y 0 ) ( u , v ) (u,v) ( u , v ) ( x 0 , y 0 ) (x_0,y_0) ( x 0 , y 0 ) ( m , n ) (m,n) ( m , n ) 完全无关 。因此它可以被提到双重求和号外面:
F { I ′ } ( u , v ) = [ ∑ m = 0 W − 1 ∑ n = 0 H − 1 I ( m , n ) e − j 2 π ( u m W + v n H ) ] ⏟ 这正是 F { I } ( u , v ) ⋅ e − j 2 π ( u x 0 W + v y 0 H ) \mathcal{F}\{I'\}(u,v) = \underbrace{\left[\sum_{m=0}^{W-1} \sum_{n=0}^{H-1} I(m,n) \; e^{-j 2\pi \left(\frac{um}{W} + \frac{vn}{H}\right)}\right]}_{\text{这正是 } \mathcal{F}\{I\}(u,v)} \cdot e^{-j 2\pi \left(\frac{ux_0}{W} + \frac{vy_0}{H}\right)}
F { I ′ } ( u , v ) = 这正是 F { I } ( u , v ) [ m = 0 ∑ W − 1 n = 0 ∑ H − 1 I ( m , n ) e − j 2 π ( W u m + H v n ) ] ⋅ e − j 2 π ( W u x 0 + H v y 0 )
于是得到平移定理(Shift Theorem) :
F { I ′ } ( u , v ) = F { I } ( u , v ) ⋅ e − j 2 π ( u x 0 W + v y 0 H ) \boxed{\mathcal{F}\{I'\}(u,v) = \mathcal{F}\{I\}(u,v) \;\cdot\; e^{-j 2\pi \left(\frac{ux_0}{W} + \frac{vy_0}{H}\right)}}
F { I ′ } ( u , v ) = F { I } ( u , v ) ⋅ e − j 2 π ( W u x 0 + H v y 0 )
物理意义 :空间域的平移 ( x 0 , y 0 ) (x_0, y_0) ( x 0 , y 0 ) ( u , v ) (u,v) ( u , v ) 单位复数 e − j 2 π ( ⋯ ) e^{-j 2\pi (\cdots)} e − j 2 π ( ⋯ )
13.2.1.2. 我们把原图像在频率 ( u , v ) (u,v) ( u , v ) 极坐标形式 (幅度-相位形式):
F { I } ( u , v ) = A ( u , v ) ⋅ e j ϕ ( u , v ) \mathcal{F}\{I\}(u,v) = A(u,v) \cdot e^{j\phi(u,v)}
F { I } ( u , v ) = A ( u , v ) ⋅ e j ϕ ( u , v )
其中:
A ( u , v ) = ∣ F { I } ( u , v ) ∣ ≥ 0 A(u,v) = \big|\mathcal{F}\{I\}(u,v)\big| \ge 0 A ( u , v ) = ∣ ∣ F { I } ( u , v ) ∣ ∣ ≥ 0 幅度 (Amplitude / Magnitude);ϕ ( u , v ) = arg ( F { I } ( u , v ) ) \phi(u,v) = \arg\big(\mathcal{F}\{I\}(u,v)\big) ϕ ( u , v ) = arg ( F { I } ( u , v ) ) 相位 (Phase)。
将平移定理代入:
F { I ′ } ( u , v ) = [ A ( u , v ) ⋅ e j ϕ ( u , v ) ] ⋅ e − j 2 π ( u x 0 W + v y 0 H ) \mathcal{F}\{I'\}(u,v) = \left[A(u,v) \cdot e^{j\phi(u,v)}\right] \cdot e^{-j 2\pi \left(\frac{ux_0}{W} + \frac{vy_0}{H}\right)}
F { I ′ } ( u , v ) = [ A ( u , v ) ⋅ e j ϕ ( u , v ) ] ⋅ e − j 2 π ( W u x 0 + H v y 0 )
合并指数项:
F { I ′ } ( u , v ) = A ( u , v ) ⋅ e j [ ϕ ( u , v ) − 2 π ( u x 0 W + v y 0 H ) ] \mathcal{F}\{I'\}(u,v) = A(u,v) \cdot e^{j\left[\phi(u,v) \;-\; 2\pi\left(\frac{ux_0}{W} + \frac{vy_0}{H}\right)\right]}
F { I ′ } ( u , v ) = A ( u , v ) ⋅ e j [ ϕ ( u , v ) − 2 π ( W u x 0 + H v y 0 ) ]
13.2.1.2.1. 对上式两边取复数模 (Magnitude)。利用复数模的乘法性质 ∣ z 1 ⋅ z 2 ∣ = ∣ z 1 ∣ ⋅ ∣ z 2 ∣ |z_1 \cdot z_2| = |z_1| \cdot |z_2| ∣ z 1 ⋅ z 2 ∣ = ∣ z 1 ∣ ⋅ ∣ z 2 ∣
∣ F { I ′ } ( u , v ) ∣ = ∣ A ( u , v ) ⋅ e j [ ϕ ( u , v ) − 2 π ( ⋯ ) ] ∣ \big|\mathcal{F}\{I'\}(u,v)\big| = \Big|A(u,v) \cdot e^{j\left[\phi(u,v) - 2\pi(\cdots)\right]}\Big|
∣ ∣ F { I ′ } ( u , v ) ∣ ∣ = ∣ ∣ ∣ A ( u , v ) ⋅ e j [ ϕ ( u , v ) − 2 π ( ⋯ ) ] ∣ ∣ ∣
= ∣ A ( u , v ) ∣ ⋅ ∣ e j [ ϕ ( u , v ) − 2 π ( ⋯ ) ] ∣ ⏟ (关键一步) = |A(u,v)| \cdot \underbrace{\left|e^{j\left[\phi(u,v) - 2\pi(\cdots)\right]}\right|}_{\text{(关键一步)}}
= ∣ A ( u , v ) ∣ ⋅ (关键一步) ∣ ∣ ∣ e j [ ϕ ( u , v ) − 2 π ( ⋯ ) ] ∣ ∣ ∣
这里用到复分析中的基本结论:对任意实数 θ \theta θ
∣ e j θ ∣ = cos 2 θ + sin 2 θ = 1 |e^{j\theta}| = \sqrt{\cos^2\theta + \sin^2\theta} = 1
∣ e j θ ∣ = cos 2 θ + sin 2 θ = 1
因此,无论括号里的相位是什么,单位复数的模恒为 1:
∣ e j [ ϕ ( u , v ) − 2 π ( ⋯ ) ] ∣ = 1 \left|e^{j\left[\phi(u,v) - 2\pi(\cdots)\right]}\right| = 1
∣ ∣ ∣ e j [ ϕ ( u , v ) − 2 π ( ⋯ ) ] ∣ ∣ ∣ = 1
代回上式:
∣ F { I ′ } ( u , v ) ∣ = ∣ A ( u , v ) ∣ ⋅ 1 = A ( u , v ) \big|\mathcal{F}\{I'\}(u,v)\big| = |A(u,v)| \cdot 1 = A(u,v)
∣ ∣ F { I ′ } ( u , v ) ∣ ∣ = ∣ A ( u , v ) ∣ ⋅ 1 = A ( u , v )
而 A ( u , v ) = ∣ F { I } ( u , v ) ∣ A(u,v) = \big|\mathcal{F}\{I\}(u,v)\big| A ( u , v ) = ∣ ∣ F { I } ( u , v ) ∣ ∣
∣ F { I ′ } ( u , v ) ∣ = ∣ F { I } ( u , v ) ∣ \boxed{\big|\mathcal{F}\{I'\}(u,v)\big| = \big|\mathcal{F}\{I\}(u,v)\big|}
∣ ∣ F { I ′ } ( u , v ) ∣ ∣ = ∣ ∣ F { I } ( u , v ) ∣ ∣
结论 :图像在空间域发生任意平移 ( x 0 , y 0 ) (x_0, y_0) ( x 0 , y 0 ) 幅度谱(Magnitude Spectrum)在每个频率上都严格保持不变 。
13.2.1.2.2. 合并指数后的表达式直接读取相位:
arg ( F { I ′ } ( u , v ) ) = ϕ ( u , v ) − 2 π ( u x 0 W + v y 0 H ) \arg\Big(\mathcal{F}\{I'\}(u,v)\Big) = \phi(u,v) \;-\; 2\pi\left(\frac{ux_0}{W} + \frac{vy_0}{H}\right)
arg ( F { I ′ } ( u , v ) ) = ϕ ( u , v ) − 2 π ( W u x 0 + H v y 0 )
即:
arg ( F { I ′ } ) = arg ( F { I } ) − 2 π ( u x 0 W + v y 0 H ) \boxed{\arg\Big(\mathcal{F}\{I'\}\Big) = \arg\Big(\mathcal{F}\{I\}\Big) \;-\; 2\pi\left(\frac{ux_0}{W} + \frac{vy_0}{H}\right)}
arg ( F { I ′ } ) = arg ( F { I } ) − 2 π ( W u x 0 + H v y 0 )
结论 :
空间平移确实改变了相位谱 ;
在每个频率 ( u , v ) (u,v) ( u , v ) Δ ϕ = − 2 π ( u x 0 W + v y 0 H ) \Delta\phi = -2\pi\left(\frac{ux_0}{W} + \frac{vy_0}{H}\right) Δ ϕ = − 2 π ( W u x 0 + H v y 0 ) ( u , v ) (u,v) ( u , v ) 线性关系 ;
相位改变量与图像内容 I ( x , y ) I(x,y) I ( x , y ) ( x 0 , y 0 ) (x_0, y_0) ( x 0 , y 0 )
平移后 ⇒ { 幅度谱: ∣ F { I ′ } ∣ = ∣ F { I } ∣ (完全不变) 相位谱: arg ( F { I ′ } ) = arg ( F { I } ) − 2 π ( u x 0 W + v y 0 H ) (线性偏移) \text{平移后} \quad \Rightarrow \quad
\begin{cases}
\text{幅度谱:} & \big|\mathcal{F}\{I'\}\big| = \big|\mathcal{F}\{I\}\big| & \text{(完全不变)}\\[8pt]
\text{相位谱:} & \arg(\mathcal{F}\{I'\}) = \arg(\mathcal{F}\{I\}) - 2\pi\left(\frac{ux_0}{W} + \frac{vy_0}{H}\right) & \text{(线性偏移)}
\end{cases}
平移后 ⇒ ⎩ ⎨ ⎧ 幅度谱: 相位谱: ∣ ∣ F { I ′ } ∣ ∣ = ∣ ∣ F { I } ∣ ∣ arg ( F { I ′ } ) = arg ( F { I } ) − 2 π ( W u x 0 + H v y 0 ) (完全不变) (线性偏移)
这就是平移不变性 的严格数学来源。也正因如此,当我们用 FFT 幅度谱 作为监督目标时,就完全不用担心真实采集的 PSF 与仿真 PSF 之间有几像素的中心偏移——因为偏移只影响相位,而我们根本不看相位。
幅度谱 :描述图像中各频率分量的"强度"——即图像中有没有某种粗细的纹理、边缘、光斑形状。它与这些纹理出现在图像的哪个位置 无关。相位谱 :描述各频率分量的"位置对齐信息"。一旦图像平移,所有频率的相位都会按线性规律发生偏转。
因此,如果我们只拿幅度谱 做对比,就天然忽略了"图像整体偏移了多少"这个问题,只关心"图像里的形状对不对"。
13.2.2. 知道了"幅度谱平移不变"这个性质,接下来的问题是:如何把幅度谱转化为一个鲁棒的、可优化的损失函数?
直接对 ∣ F F T ∣ |FFT| ∣ F F T ∣
以下是我们在实际代码中采用的四步法:
13.2.2.1. 真实探测器采集的图像通常带有暗电流或环境杂散光基底。这个恒定背景会在 FFT 的零频(DC 分量)处产生一个巨大的尖峰,掩盖其他频率的差异。
1 2 real = real - real.amin(dim=(-2 , -1 ), keepdim=True ) sim = sim - sim.amin(dim=(-2 , -1 ), keepdim=True )
13.2.2.2. 仿真 PSF 的绝对强度是物理量(W/m²),而真实图像是相机灰度级(ADU)。两者尺度完全不同,必须归一化到同一量级:
1 2 real = real / (real.amax(dim=(-2 , -1 ), keepdim=True ) + eps) sim = sim / (sim.amax(dim=(-2 , -1 ), keepdim=True ) + eps)
这样做保留了 PSF 的相对能量分布 (在焦与离焦的相对亮度、光斑能量集中程度),而去除了探测器增益差异的影响。
13.2.2.3. 1 2 mag_real = torch.log1p(torch.abs (torch.fft.fft2(real, dim=(-2 , -1 )))) mag_sim = torch.log1p(torch.abs (torch.fft.fft2(sim, dim=(-2 , -1 ))))
torch.fft.fft2:计算二维傅里叶变换。torch.abs:取幅度谱,丢弃受平移影响的相位。torch.log1p(x):即 ln ( 1 + x ) \ln(1+x) ln ( 1 + x ) 1 0 4 10^4 1 0 4
13.2.2.4. 1 loss = F.smooth_l1_loss(mag_sim, mag_real)
相比于 MSE,Smooth L1(Huber Loss)对离群值更鲁棒,在频域某些异常频率点上不会导致梯度爆炸。
13.2.3. 13.2.3.1.
旋转与缩放不变性 :FFT 幅度谱对平移不变,但对旋转和缩放不是 不变的。如果你的光路还存在旋转对准误差或像素尺度误差,需要额外处理(例如先把仿真图插值到估计的像素尺度,或在极坐标频域做监督)。直流分量 :虽然做了背景扣除,但如果图像存在大面积非均匀光照(不是恒定背景),低频区域仍可能受影响。
13.2.3.2.
频域加权 :
像差引起的光学传递函数(OTF)退化主要集中在中低频。可以构造一个二维频率权重矩阵 W ( u , v ) W(u,v) W ( u , v )
1 loss = (W * (mag_sim - mag_real)).abs ().mean()
互功率谱对齐(Phase Correlation) :
如果平移量极大(接近图像边界),仅靠幅度谱可能不够。可以先计算互功率谱的逆 FFT,得到平移的置信度图,再据此做软对齐(Soft-Argmax)或作为辅助监督。
加窗处理 :
FFT 假设信号周期性。如果 PSF 图像边缘截断明显(例如能量没有衰减到接近零),可以加 Hann 窗或 Hamming 窗后再做 FFT,减少频谱泄漏。
13.3.
核心结论 :真实采集图像存在非零背景噪声底板(min-max 后均值约 0.019),而仿真 PSF 背景严格为 0。当前 fft_psf_loss 对频域轮廓敏感,但对背景噪声底板几乎无感知,导致模型可以通过高斯模糊"骗过"频域 loss,却在空间域视觉上严重失真。
13.3.1. 观察到以下矛盾现象:
实验
训练 epoch
Test Loss
视觉质量(人眼观察)
no_截断 (仅高斯模糊)7
0.136 ⬇️更差 ❌
no_高斯 (仅截断)1
0.161
更好 ✅
完整 detector (高斯+截断)1
0.218
一般
矛盾点 :no_截断 的 loss 最低,但视觉上 PSF 与真实数据差异反而更大。
13.3.2. 13.3.2.1. 原始数据文件(.npz)中的 image 在送入网络前,经过 dataset.py 的预处理:
1 2 image = image - image.amin(dim=(-2 , -1 ), keepdim=True ) image = image / (image.amax(dim=(-2 , -1 ), keepdim=True ))
预处理后,真实采集图像(focus_real / defocus_real)的像素分布如下:
统计指标
focus_real
defocus_real
严格为 0 的像素数 0~2 个(占比 ~0%)
0~2 个(占比 ~0%)
噪声带 (0.001~0.05) 97.1% 97.1%
中间亮度 (0.05~0.5) 2.8%
2.8%
高亮区 (≥0.5) 0.1%
0.1%
P1 分位数 0.0093
0.0106
P10 分位数 0.0149
0.0152
底部 20% 均值 0.0150
0.0152
关键发现 :
真实图像预处理后,几乎所有像素(97%)都分布在一个非零的噪声带内 ,形成一层均匀的"灰色噪声底板"
即使是最暗的 1% 像素,亮度也在 0.009~0.011 之间
图像中不存在大片严格为 0 的纯黑区域
13.3.2.2. 三个实验的仿真 PSF(focus_train / defocus_train)经过相同的 min-max 归一化后:
实验
focus_train 严格为 0
defocus_train 严格为 0
噪声带 (0.001~0.05)
完整 detector 91.7% 92.1% 5.4%
no_截断 94.2% 94.2% 3.8%
no_高斯 91.7% 91.3% 6.8%
关键发现 :
仿真图像 90%+ 像素严格为 0 ,背景是纯黑的
只有约 4~7% 的像素分布在噪声带,这些通常是高斯模糊或截断产生的过渡像素
13.3.2.3. 选取图像四个角落各 50×50 区域(远离光斑峰值,视为纯背景):
指标
真实 focus_real 角落
完整 detector 仿真角落
均值 0.0193 0.0000
标准差 0.0039 0.0000
最小值 0.0000
0.0000
最大值 0.0392
0.0000
关键发现 :
真实背景区有明显的随机波动 (std=0.004),这是读出噪声和热噪声的特征
仿真背景区完全平坦 (std=0),没有任何噪声
13.3.2.4. 以 focus 为例,分析 train - real 的差异在不同区域的分布:
区域定义
完整 detector MAE
no_截断 MAE
no_高斯 MAE
背景区 (real < 0.05)0.0206
0.0205
0.0201
中间区 (0.05 ≤ real < 0.5)0.1150
0.1131
0.1170
峰值区 (real ≥ 0.5)0.5475
0.5493
0.5602
整体 MAE 0.0237
0.0235
0.0233
关键发现 :
三个实验在背景区的误差方向一致且显著为负 (仿真比真实暗约 0.017~0.018),说明所有实验都存在"背景缺失"问题
no_高斯 在背景区的 MAE 最小(0.0201),_std 也最小(0.0148),说明其背景最"干净"但也最偏离真实噪声
空间域误差主要由峰值区结构差异 主导(MAE 0.55),但背景区的系统性偏差( 0.02)在视觉上非常突出
13.3.3. 13.3.3.1. fft_psf_loss 会"被骗"?当前损失函数定义:
1 2 3 4 5 6 def fft_psf_loss (sim_psf, real_psf, eps=1e-8 ): real_fft = fft.fft2(real_psf, dim=(-2 , -1 )) sim_fft = fft.fft2(sim_psf, dim=(-2 , -1 )) real_mag = torch.log1p(torch.abs (real_fft)) sim_mag = torch.log1p(torch.abs (sim_fft)) return F.smooth_l1_loss(sim_mag, sim_mag)
13.3.3.1.1.
真实数据类型
vs Sim_Clean (清晰)
vs Sim_Blur (模糊)
Clean 艾里斑
0.000 0.006
Clean + 均匀常数背景 (0.015)
0.000 0.006
Clean + 随机背景噪声 (mean=0.015, std=0.004)
0.377 0.383
关键发现 :
均匀常数背景 经过 min-max 归一化后,对 FFT loss 零影响 随机波动的背景噪声 (std=0.004)让同一个艾里斑的 FFT loss 暴涨到 0.377 噪声并没有让"模糊"变得更有优势 ——无论目标是否带噪声,清晰 PSF 始终比模糊 PSF 的 loss 低约 0.006
13.3.3.1.2. 第一步:真实频谱被噪声"污染"
真实数据的频谱 = 信号频谱(艾里斑) + 噪声频谱(宽谱随机波纹)
随机噪声虽然空间域 std 只有 0.004,但它分布在 400×400 = 16 万个像素上。FFT 后,这些扰动不会消失,而是给每一个频率分量 都叠加了一个随机偏移。
第二步:log1p 没有"消除"噪声,而是把它变成了一层"不规则的频谱波纹"
噪声在每个频率上的能量不高(被 16 万像素分摊),log1p 把它压缩成一个小的随机偏移量 。但这个偏移量分布在成千上万个频率分量 上,累积起来形成了一个不规则的频谱基线 。
第三步:SmoothL1Loss 强迫模型扭曲信号去匹配噪声形状
当真实频谱的某个频率因为噪声而随机偏高时,模型为了降低总 loss(数千个频率分量的累积),只能通过扭曲信号本身 来在该频率上"制造"类似的能量:
调整波长(如 no_截断 从 530 nm 推到 306 nm ,偏离 42%)
调整 defocus(从 -0.265 推到 -0.142 )
加高斯模糊(改变频谱衰减斜率)
第四步:空间域灾难
频域上"凑出相似衰减曲线"的代价是:空间域的 PSF 变成了一个物理上不合理、结构上严重失真 的光斑。艾里环被抹平,光斑尺寸被强行改变,悬浮在纯黑背景上——这就是"loss 降、视觉崩"的根源。
随机背景噪声给真实频谱添加了"无规律的波纹"。FFT loss 强迫模型扭曲信号(波长、离焦、模糊)去贴合这些波纹,从而降低了 loss 数值,但空间域的 PSF 结构被严重破坏。
13.3.3.2. 频域匹配 ≠ 空间域匹配
维度
no_截断(7 epoch)
no_高斯(1 epoch)
真实数据
FWHM(半高宽) 9 px (过窄)24 px (接近)19 px
第一暗环深度 0.0496
0.0492
0.0196
第一暗环位置 25 px
14 px
32 px
背景 纯黑(0)
纯黑(0)
灰色底板(~0.02)
艾里环清晰度 被高斯模糊严重抹平
较清晰
清晰但叠加噪声
关键机制 :
no_截断 训练 7 epoch 后 loss 从 0.223 降到 0.136 ,主要不是靠高斯模糊(实验证明模糊反而增加 loss),而是靠物理参数被严重扭曲 :
波长:530 nm → 306 nm (偏离 42%,非物理)
defocus:-0.265 μm → -0.142 μm
模型通过扭曲物理参数来"拟合"被噪声污染的不规则频谱,在空间域产生了一个过窄、过平滑、无艾里环结构 的光斑
真实数据虽然有噪声,但艾里环结构仍然可辨;no_截断 的仿真却把结构完全抹掉了
no_高斯 虽然只有 1 epoch,但没有高斯模糊 ,且物理参数偏离小(波长仅到 518 nm),保留了艾里环结构,虽然背景仍是 0,但至少"轮廓是对的"
13.3.3.3. 当前数据预处理流程:
1 2 3 4 5 原始图像(有背景噪声) ↓ 逐样本减去最小值 最小值被拉到 0,但其他背景像素仍 > 0 ↓ 逐样本除以最大值 噪声底板被归一化到约 0.01~0.02 的范围
问题 :
真实相机的背景是系统性的 (暗电流、读出噪声、固定环境光),应该全局扣除
逐样本 amin 导致每个样本的背景基准不同,模型难以学到统一的背景
仿真 PSF 背景严格为 0,min-max 后仍然是 0,与真实数据的非零底板形成强烈视觉反差
13.3.4. 13.3.4.1. dataset.py )核心思想 :用全局/鲁棒背景估计替代逐样本 amin,让真实数据的背景更接近 0。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import torchimport torch.nn.functional as Fimport numpy as npfrom torch.utils.data import Datasetclass CustomDataset (Dataset ): def __init__ (self, sample_txt, transform=None , global_bg=None ): self.samples = np.loadtxt(sample_txt, dtype=np.str_) self.transform = transform self.global_bg = global_bg def __len__ (self ): return len (self.samples) def __getitem__ (self, idx ): while True : try : data = np.load(self.samples[idx]) image = data["image" ] zernike = data["zernike" ] if self.transform: image = self.transform(image) if self.global_bg is not None : image = image - self.global_bg image = F.relu(image) else : h, w = image.shape[-2 ], image.shape[-1 ] corner_size = min (h, w) // 8 corners = torch.cat([ image[..., :corner_size, :corner_size].flatten(), image[..., :corner_size, -corner_size:].flatten(), image[..., -corner_size:, :corner_size].flatten(), image[..., -corner_size:, -corner_size:].flatten() ]) bg = corners.median() image = image - bg image = F.relu(image) image = image / (image.amax(dim=(-2 , -1 ), keepdim=True ) + 1e-8 ) return image, zernike except BaseException as e: print (e) import time time.sleep(1 )
为什么用角落中位数?
光斑通常位于图像中心,四个角落远离光斑,可视为纯背景
中位数比最小值更鲁棒,不受单个坏点/热像素影响
全局背景扣除保证了样本间背景基准一致
13.3.4.2. 在 generative_M4_model.py 中修改 DetectorResponseLayer,添加可学习的背景偏移和噪声。
13.3.4.3. 当前仅用 fft_psf_loss,对背景不敏感。建议增加空间域损失项:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from torch import fftimport torch.nn.functional as Fdef combined_psf_loss (sim_psf, real_psf, alpha=0.5 , eps=1e-8 ): """ 组合损失:频域 loss(平移不变)+ 空间域 loss(背景敏感) Args: sim_psf: [B, 2, H, W] 仿真 PSF real_psf: [B, 2, H, W] 真实 PSF alpha: 频域 loss 权重(0~1),建议从 0.7 开始调试 """ real_fft = fft.fft2(real_psf, dim=(-2 , -1 )) sim_fft = fft.fft2(sim_psf, dim=(-2 , -1 )) real_mag = torch.log1p(torch.abs (real_fft)) sim_mag = torch.log1p(torch.abs (sim_fft)) fft_loss = F.smooth_l1_loss(sim_mag, sim_mag) spatial_loss = F.smooth_l1_loss(sim_psf, real_psf) bg_mask = (real_psf < 0.05 ).float () bg_loss = F.smooth_l1_loss(sim_psf * bg_mask, real_psf * bg_mask) total_loss = alpha * fft_loss + (1 - alpha) * spatial_loss + 0.1 * bg_loss return total_loss, { 'fft_loss' : fft_loss.item(), 'spatial_loss' : spatial_loss.item(), 'bg_loss' : bg_loss.item() }
参数调试建议 :
阶段
alpha
说明
初期
0.7
以频域为主,保证整体轮廓正确
中期
0.5
空间域与频域同等重要
后期
0.3
以空间域为主,精细化背景匹配
13.3.5. 13.3.5.1.
以下为实际测试数据:将修改后的 dataset.py(角落中位数背景扣除)分别应用到三个实验配置中,不重新训练模型 ,直接运行 test_optical_param.py 对比新旧 dataset 的 raw data。
13.3.5.1.1.
实验
训练模型
Dataset 预处理
说明
旧-完整 detector
旧 checkpoint(1 epoch)
逐样本 amin
基线
旧-无截断
旧 checkpoint(7 epoch)
逐样本 amin
基线
旧-无高斯
旧 checkpoint(1 epoch)
逐样本 amin
基线
新-完整 detector 旧 checkpoint(1 epoch)
角落中位数扣除 验证
新-无截断 旧 checkpoint(7 epoch)
角落中位数扣除 验证
新-无高斯 旧 checkpoint(1 epoch)
角落中位数扣除 验证
13.3.5.1.2. 旧 dataset(逐样本 amin):
底部 10% 像素 = 0.0149
底部 20% 均值 = 0.0150
严格为 0 的像素 = ~0%
角落背景均值 = 0.0093
新 dataset(角落中位数):
P1/P5/P10 = 0.000000
严格为 0 的像素 = 49.3%
微弱残余带 (0.001~0.01) = 44.5%
角落背景均值 = 0.000884 (旧值的 1/10)
13.3.5.1.3.
区域
旧 MAE
新 MAE
变化
解读
背景区 (real < 0.05)~0.010
~0.002
↓ 80% ✅中位数扣除直接消除了背景系统偏差
中间区 (0.05~0.5)~0.120
~0.125
基本持平
中位数扣除不影响信号结构
峰值区 (real ≥ 0.5)~0.500
~0.500
基本持平
峰值结构不受预处理影响
13.3.5.1.4.
改善 100% 来自背景区,峰值区不变
中位数扣除只影响背景,不影响艾里斑结构
峰值区 MAE 不变是因为模型未重训(旧 checkpoint 的物理参数没变)
无高斯在新 dataset 下仍然是最佳配置
新-无高斯 Focus MAE = 0.00328(三实验中最低)
再次验证:高斯模糊是不必要的
仿真数据背景仍为 0,真实数据仍有微弱残余
新 dataset 下仿真背景 = 0.000000
真实背景 = 0.000884,仍有约 44.5% 像素在 0.001~0.01
这是因为角落中位数可能略低于某些暗区像素,扣除后仍有少量残余
如果重新训练模型,峰值区可能也会改善
旧模型是在"高背景"数据上训练的,参数是为了匹配旧数据优化的
新数据背景更干净,如果重训,模型可能学到更准确的物理参数
13.3.5.2.
实验设置:三个配置(完整 detector / 无截断 / 无高斯)均使用新的 dataset.py(角落中位数背景扣除)重新训练 1 个 epoch ,然后运行测试。
13.3.5.2.1. Epoch 0 Loss
实验
旧 Dataset Train
旧 Dataset Test
新 Dataset Train
新 Dataset Test
Train 降幅
Test 降幅
完整 detector 0.2458
0.2182
0.2032 0.1785 -17.3% -18.2%
无截断 0.2512
0.2234
0.2083 0.1834 -17.1% -17.9%
无高斯 0.1712
0.1611
0.1415 0.1340 -17.3% -16.8%
关键发现 :
新 dataset 下,所有配置的初始 loss 都降低了约 17% ,说明中位数背景扣除显著降低了数据与模型的初始失配
无高斯仍然是 loss 最低的 (Test=0.1340),且与其他两个配置的差距保持(完整/无截断约 0.18)
13.3.5.2.2. 训练后模型参数
参数
旧-完整
新-完整
旧-无截断
新-无截断
旧-无高斯
新-无高斯
波长 λ 464 nm
464 nm 403 nm ❌466 nm ✅518 nm
535 nm ✅
defocus -0.184 μm
-0.185 μm
-0.154 μm
-0.187 μm -0.290 μm
-0.301 μm
focus_defocus -0.009 μm
-0.011 μm
-0.038 μm
-0.016 μm -0.062 μm
-0.066 μm
detector σ 1.13
1.13
0.60
1.13 1.21
1.21
detector saturation 0.92
0.92
1.00
1.00
1.04
1.03
关键发现 :
无高斯的波长最接近真实值 :534.8 nm,仅偏离初始值 530 nm 约 0.9%。
无截断的 σ 回归正常 :旧 dataset 下 σ 被迫降到 0.60 来减弱高斯模糊,新 dataset 下回归至 1.13(接近初始 1.2)。
defocus 系数趋于一致 :完整/无截断在新 dataset 下 defocus 都收敛到约 -0.186 μm(接近初始 -0.265 μm 的合理范围),而旧无截断是 -0.154 μm。
13.3.5.2.3. 耦合机制:
高斯模糊(卷积)和波长变化在频域上是耦合的,两者可以相互补偿 。
频域效应对比 :
操作
空间域
频域效应
对高频的影响
波长 λ↓ 艾里斑变小
频谱展宽
增加
高斯模糊 σ↑ 光斑展宽
频谱收缩
减少
关键洞察 :
波长减小 → 频谱高频能量增加
高斯模糊增强 → 频谱高频能量减少
两者产生相反的频域效应
实验验证:不同 (λ, σ) 组合是否能产生相似频谱?
以参考 (λ=530nm, σ=0) 为基准,计算各组合的 fft_psf_loss:
(λ, σ)
vs 参考的 fft_loss
解读
(530, 0)
0.0000 参考
(464, 0)
0.0108
仅改变波长
(464, 0.6)
0.0057 ⭐λ↓ + σ↑ 组合,loss 比单纯 λ↓ 更低
(464, 1.2)
0.0441
λ↓ + σ↑↑,过度补偿
(530, 1.2)
0.0436
仅加高斯模糊
关键发现 :
λ=464nm + σ=0.6 的 loss(0.0057)比 λ=464nm + σ=0(0.0108)更低 这说明:高斯模糊确实可以补偿波长变化带来的频谱差异
模型可以通过 (λ↓, σ↑) 的组合来逼近目标频谱,而无需学到真正的物理参数
对 detector 设计的启示
如果高斯模糊和波长是耦合的,同时保留两者会导致参数解空间退化,模型学不到真正的物理参数。
建议 :
去掉高斯模糊 (已验证无高斯配置在所有指标上最优)固定波长 (如果激光波长已知为 530nm,直接锁死 raw_wavelength_m 的梯度)如果必须保留高斯模糊 ,应同时限制 λ 的学习范围 (如 500~560nm),防止模型用 λ 来补偿 σ
13.3.5.2.4.
⚠️ 重要说明 :以下分析基于逐像素 MAE。由于采集的 PSF 和仿真的 PSF 之间存在未配准的平移 (峰值偏移平均约 1.3~6.5 像素,最大达 13~33 像素),峰值区的逐像素 MAE 会被平移误差污染 。
但以下分析仍然有效:
整体 MAE :97% 像素为背景区,背景均匀,平移对整体 MAE 影响极小背景区 MAE :平移几乎不影响均匀背景的统计峰值区 MAE :受平移污染,仅供趋势参考;已补充平移不变度量(NCC)验证
整体 MAE
实验
旧 Focus MAE
新 Focus MAE(未重训)
新 Focus MAE(重训 1 epoch)
vs 旧改善
完整 detector 0.01169
0.00377
0.00377 -67.7%
无截断 0.01171
0.00316
0.00378 -67.7%
无高斯 0.01131
0.00325
0.00324 -71.3%
实验
旧 Defocus MAE
新 Defocus MAE(重训)
vs 旧改善
完整 detector 0.01434
0.00453 -68.4%
无截断 0.01434
0.00455 -68.3%
无高斯 0.01405
0.00431 -69.3%
关键发现 :
整体 MAE 改善约 70%,几乎全部来自 dataset 预处理 ,重训 1 epoch 对空间域 MAE 几乎没有额外贡献这是因为 1 epoch 训练主要优化频域 loss,而空间域结构由模型初始化决定
按区域分解(Focus)
区域
旧-完整
新-完整(重训)
旧-无截断
新-无截断(重训)
旧-无高斯
新-无高斯(重训)
背景 (<0.05)0.01020
0.00238 0.01020
0.00238 0.00987
0.00190
中间 (0.05~0.5)0.1209
0.1267 0.1149
0.1256 0.1142
0.1202
峰值 (≥0.5)0.4357
0.4347 0.5488
0.4909 0.4434
0.4367
⚠️ 峰值区 MAE 受平移污染 ,以下补充平移不变度量验证。
平移不变验证(NCC 归一化互相关) :
实验
NCC (init)
NCC (train)
训练后改善
完整 detector 0.4973
0.4985
+0.0012
无截断 —
—
—
无高斯 —
—
—
平移不变验证(对齐后 MAE) :
实验
对齐前 MAE
对齐后 MAE
平移导致误差占比
完整 detector 0.003830
0.003502 ~8.6%
关键发现 :
背景区 MAE 降低 80% :这是 dataset 改动的直接效果,与是否重训无关,且不受平移影响
峰值区存在平移,但训练后仍有改善趋势 (无截断 Peak MAE 0.549→0.491)
无截断改善最大:旧 checkpoint 训练 7 epoch 参数扭曲,新 dataset 下重训 1 epoch 后参数回归
平移不变 NCC 验证:训练后仅改善 0.0012,说明 1 epoch 对结构改善确实有限
中间区 MAE 反而略有上升 (旧→新:0.121→0.127)
真实数据背景被扣得更干净后,中间亮度区域边界更清晰,仿真模型尚未充分调整
13.3.5.2.5.
实验
真实 FWHM
仿真 FWHM
偏差
完整 detector 19 px
37 px +95% ❌
无截断 19 px
39 px +105% ❌
无高斯 19 px
22 px +16% ✅
关键发现 :
无高斯的 FWHM 最接近真实(22 vs 19 px),完整/无截断因高斯模糊严重过宽
FWHM 基于峰值位置计算,不受平移影响
13.3.5.2.6.
实验
真实中心 41×41 能量占比
仿真中心 41×41 能量占比
完整 detector 48.1%
64.8%
无截断 48.1%
64.7%
无高斯 48.1%
64.4%
关键发现 :
所有仿真 PSF 的能量都过于集中在中心(比真实高约 16 个百分点)
仿真背景为 0,真实数据扣除后仍有微弱残余背景(corner mean=0.0009),会分散能量
无高斯的集中度最接近真实(64.4% vs 64.8%)
13.3.5.2.7.
实验
旧 M4 init
旧 M4 train
新 M4 init
新 M4 train
Train 改善
完整 detector 0.7048
0.7138
0.6797
0.6905 -3.3%
无截断 0.6155
0.6518
0.6154
0.6290 -3.5%
无高斯 0.7277
0.7097
0.7043
0.6849 -3.5%
关键发现 :
新 dataset 下 M4 MAE 普遍比旧 dataset 低 3~4%
无高斯训练后 M4 MAE = 0.6849,是三实验中最低的 无高斯是唯一一个训练后 M4 比 init 改善的配置(0.7043 → 0.6849)
13.3.5.2.8. 中位数背景扣除的效果(重训验证)
维度
效果
训练收敛速度 Epoch 0 loss 降低 17%,初始匹配更好
物理参数合理性 波长不再被扭曲到非物理值(无截断 403→466nm,无高斯 518→535nm)
PSF 空间匹配 整体 MAE 降低 70%,背景区降低 80%
峰值结构 无截断 Peak MAE 降低 12%(参数回归),无高斯降低 1.6%
M4 精度 提升 3~4%,无高斯最优
三个配置的最终排名(新 dataset + 1 epoch)
排名
配置
优势
劣势
⭐ 1
无高斯 Test loss 最低(0.134),MAE 最低(0.00324),波长最接近 530nm,FWHM 最接近真实,M4 最优
背景仍为 0,与真实有微弱差距
2
完整 detector
参数稳定
FWHM 过宽(37px),loss 比无高斯高 33%
3
无截断
Peak 区改善最大(重训后)
FWHM 最宽(39px),高斯模糊 unnecessary
关键认知更新
高斯模糊完全不必要 :无高斯在所有指标上都是最优或接近最优,且没有高斯模糊的副作用(FWHM 失真)。
1 epoch 重训对空间域改善有限 :整体 MAE 的 70% 改善来自 dataset 预处理本身,重训 1 epoch 主要改善了频域 loss 和峰值区结构(尤其是无截断)。
下一步应继续训练 :当前仅 1 epoch,峰值区和中间区仍有优化空间。建议用新 dataset + 无高斯配置训练 10~20 epoch。
你的目标是"仿真 PSF 与真实 PSF 在空间域 上尽可能一致",而不仅仅是"频域 loss 最小"。当前 fft_psf_loss 是一个好的正则化项 (保证平移不变性),但不应是唯一的监督信号。空间域的 SmoothL1Loss 直接惩罚像素级差异,包括背景噪声底板,是达到"视觉一致"的必经之路。
13.4. 在 Zernike2PSF_layer 中,仿真生成的 PSF(像素间距约 2.2μm)需要通过 F.interpolate 下采样到真实 CCD 的像素尺度(4.5μm)。下采样方式直接影响仿真 PSF 的空间形态,进而影响物理参数(波长 λ、离焦量 defocus)的学习精度。
模式
数学本质
物理意义
bilinear双线性插值取点
从高密度网格中插值采样
area区域像素平均
像素积分 (真实相机行为)
13.4.1. area 更物理?真实相机的每个像素是一个 4.5μm × 4.5μm 的物理面积,接收的是该区域内总光强 :
1 像素值 = ∫∫ PSF(x,y) dx dy (在像素物理面积内)
这等价于对理想 PSF 做一个 box filter(低通滤波) 。mode='area' 在缩小图像时,输出像素 = 输入区域内像素的平均值,正好模拟这一物理过程。
而 bilinear 只是从高密度采样点中插值取点 ,没有积分效应,旁瓣能量被压缩到亚像素级别,不可见。
13.4.2. 13.4.2.1.
数据集:相同的训练/测试划分
训练目标:fft_psf_loss + 0.1 × m4_loss
训练时长:2 epoch
唯一变量:interpolate 模式(bilinear vs area)
13.4.2.2.
指标
bilinear (temp_test_noise)area (temp_test_arae)变化
λ 535 nm
522 nm 更接近真实 530nm
defocus -0.301 μm
-0.291 μm 更接近真实 -0.265μm
训练 loss 0.143
0.134 相当
M4 MAE 0.676
0.646 降低 4.4%
Init Avg Loss 0.140
0.117 降低 16%
13.4.2.3. 尽管 area 模式改善了能量分布,但视觉上仿真 PSF 的"余光"/旁瓣仍然远不如真实数据明显。
原因分析:
下采样比例太大 :scale = 0.49(约 1/2),旁瓣结构被压缩到 1-2 个像素宽理想衍射旁瓣本身就极弱 :艾里斑第一亮环强度 ≈ 中心峰值的 1.75% 真实相机的"余光"来源复杂 :像素积分 + 光学像差 + 散射光 + 读出噪声底板